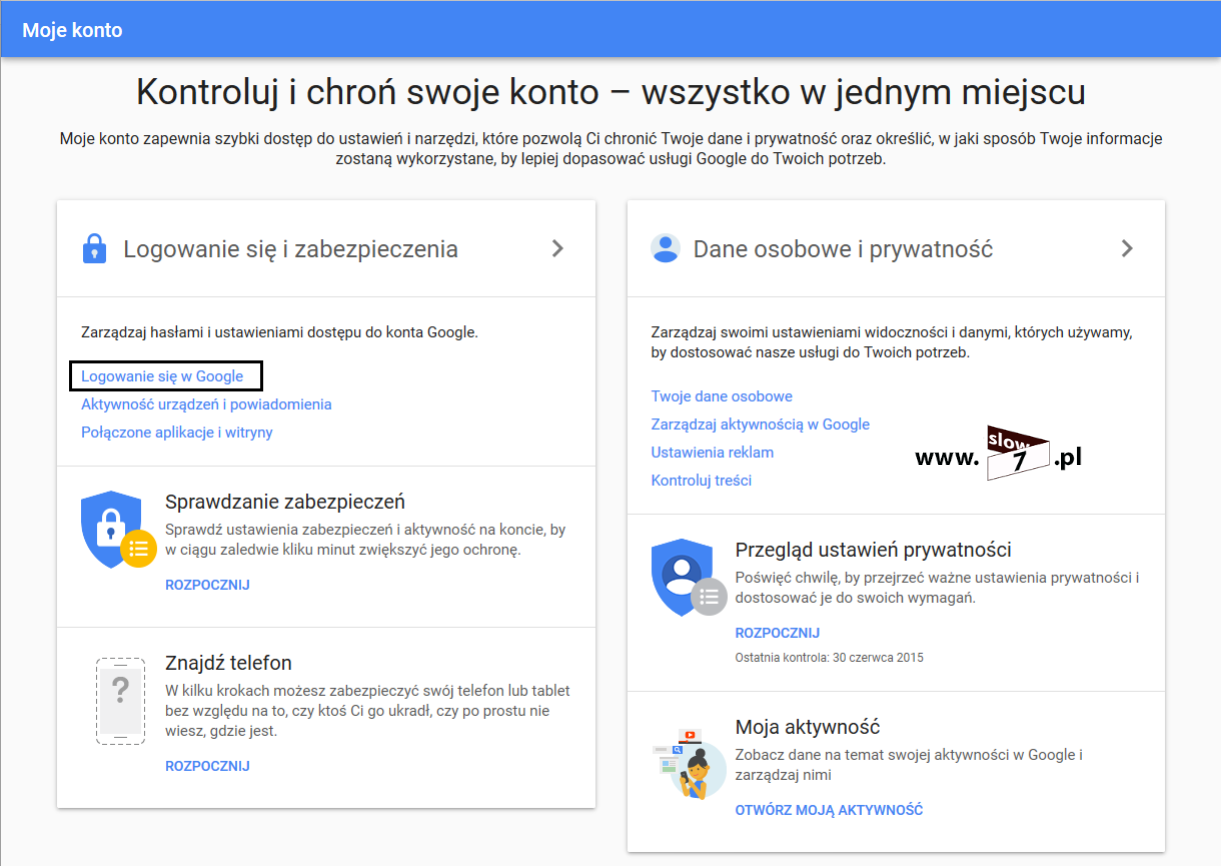
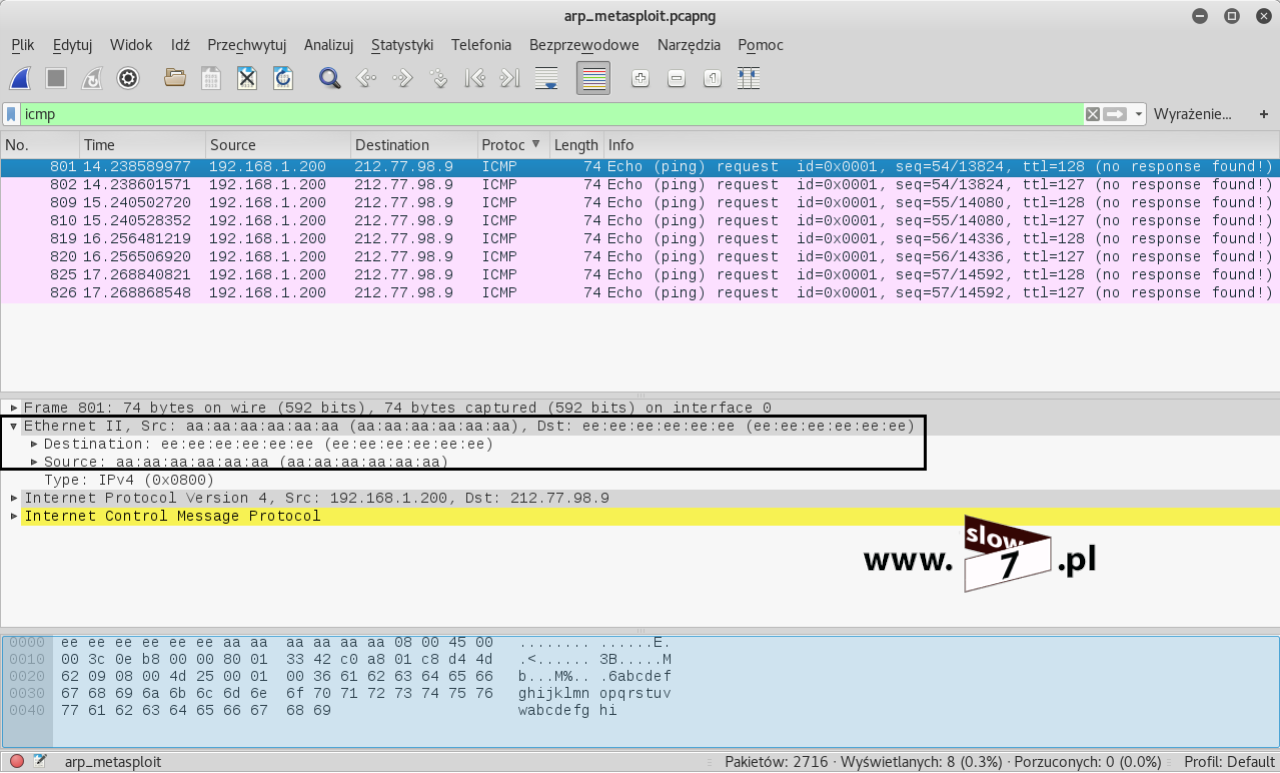
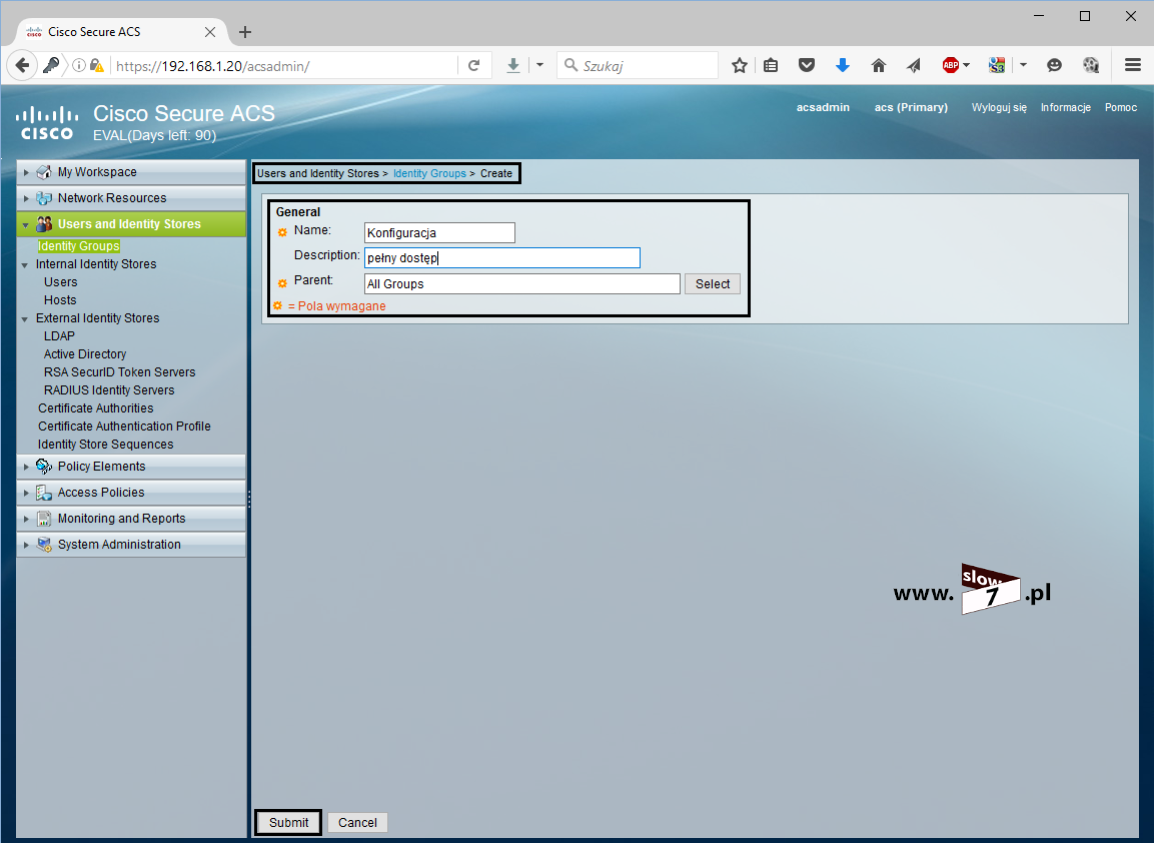
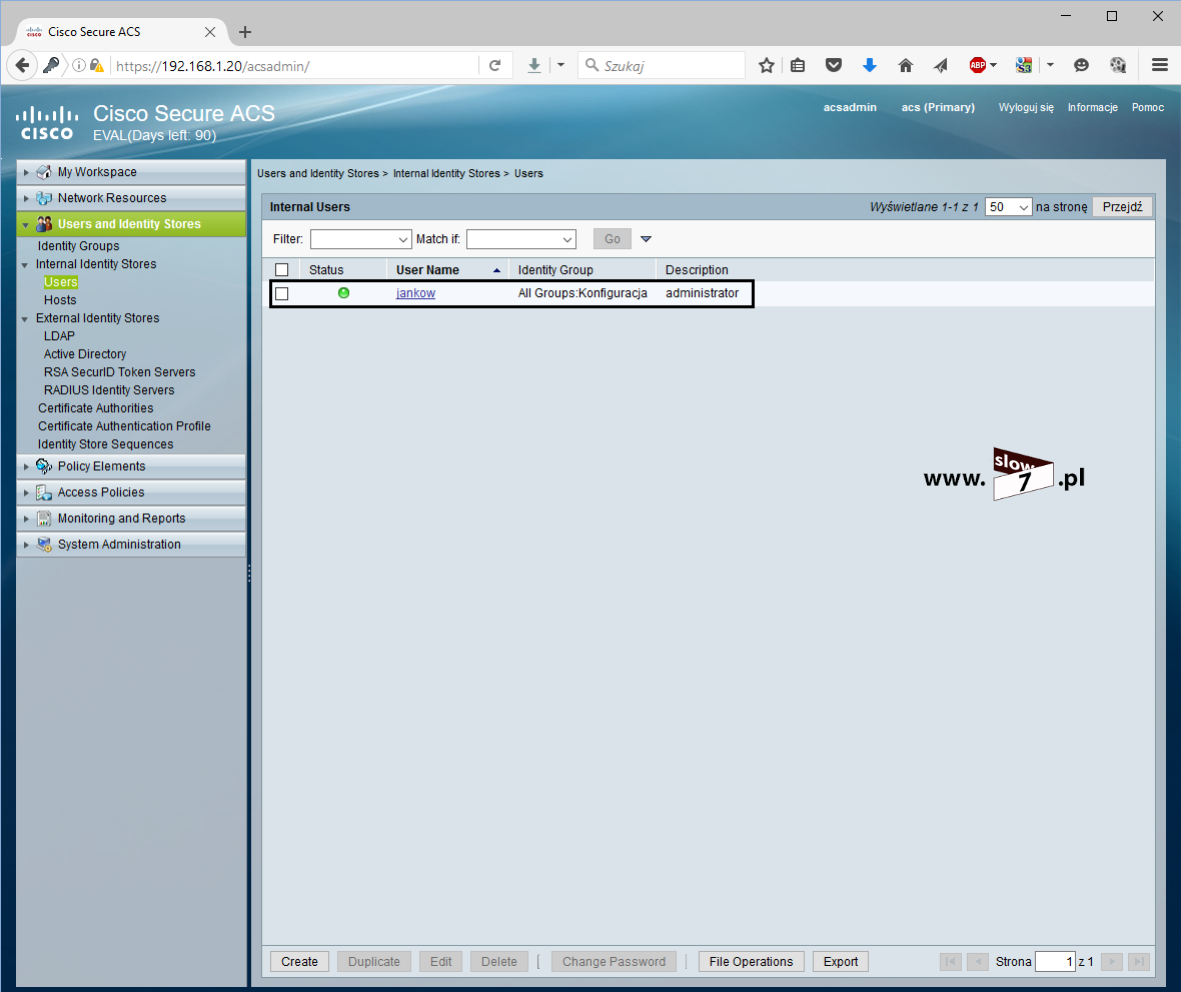
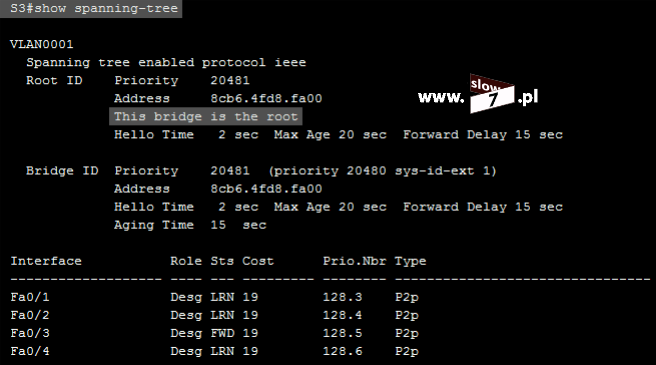
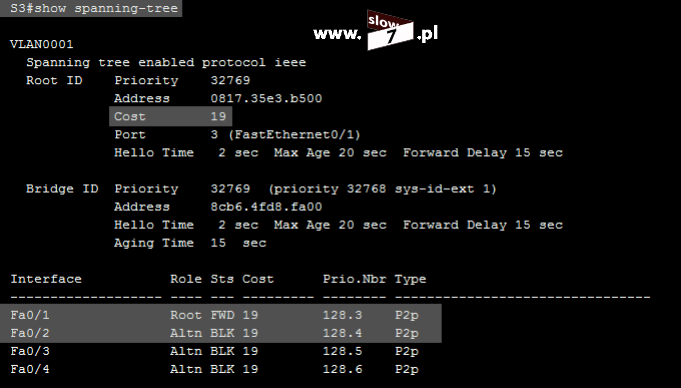
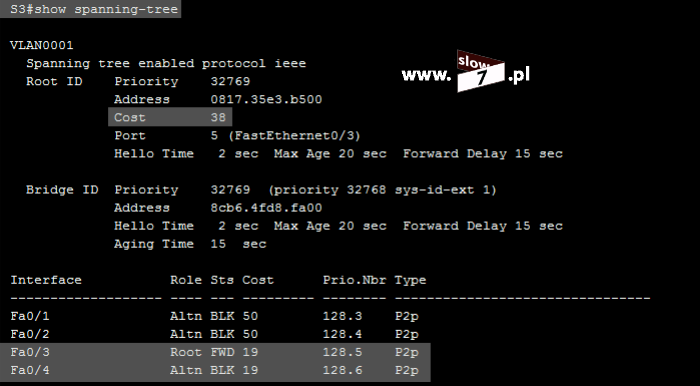
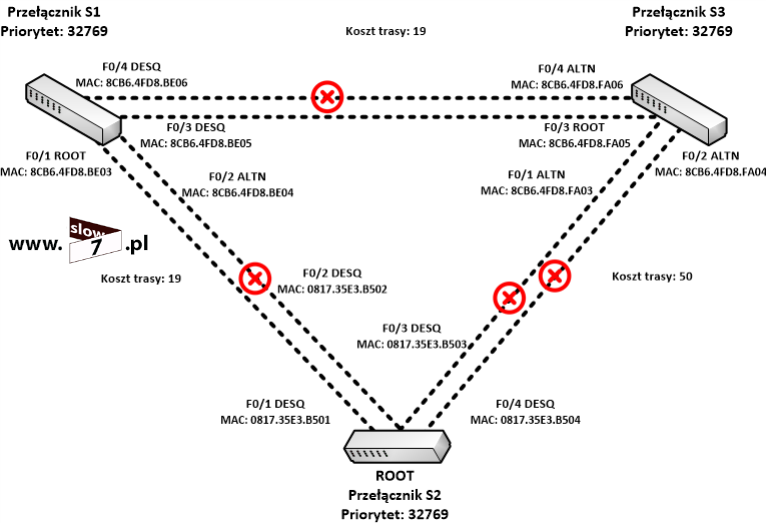
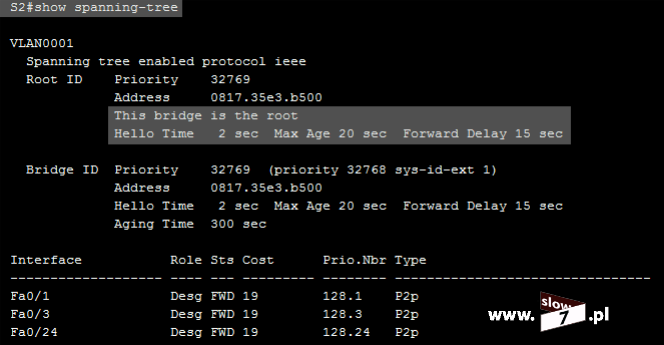
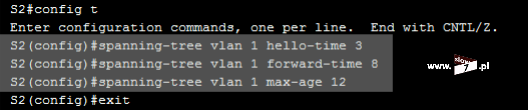
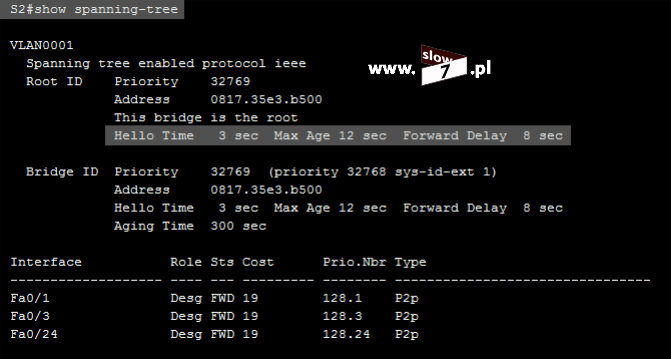
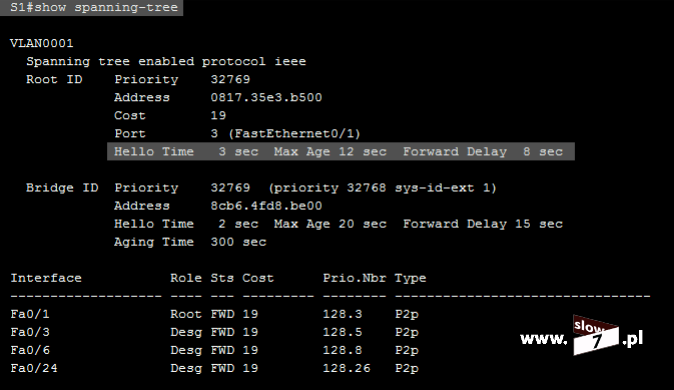
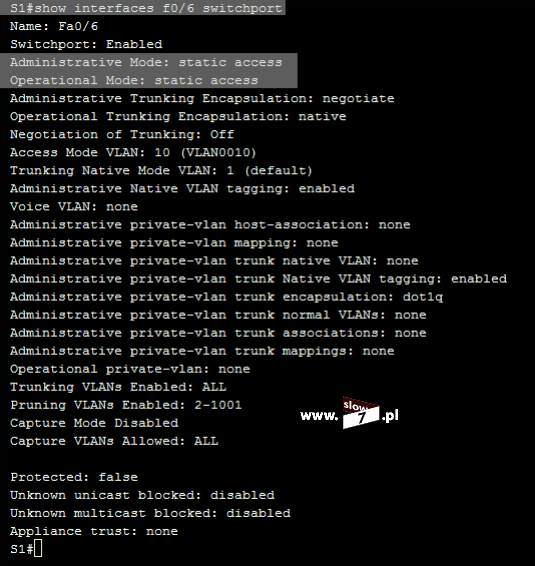
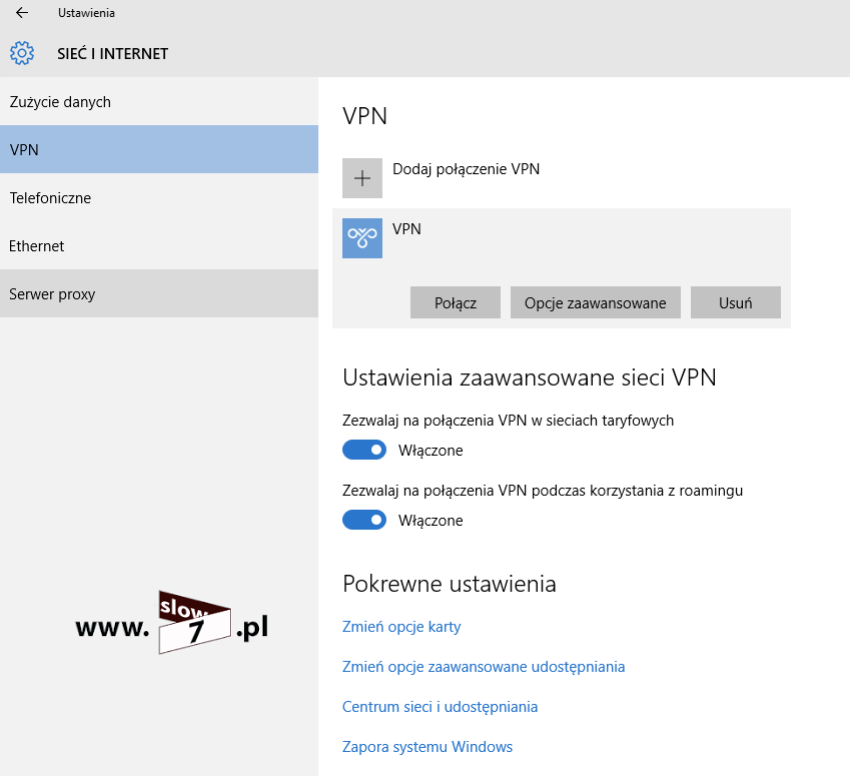
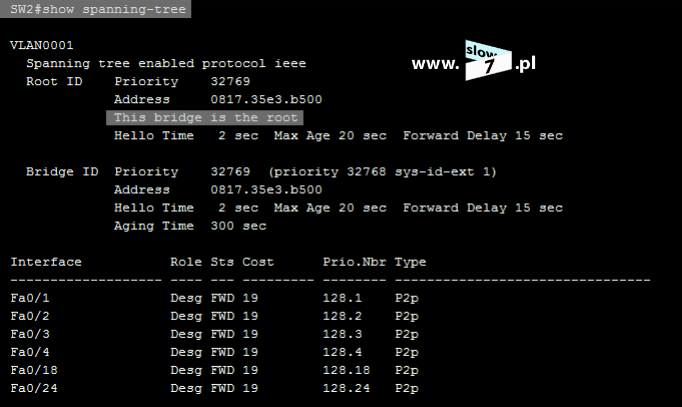
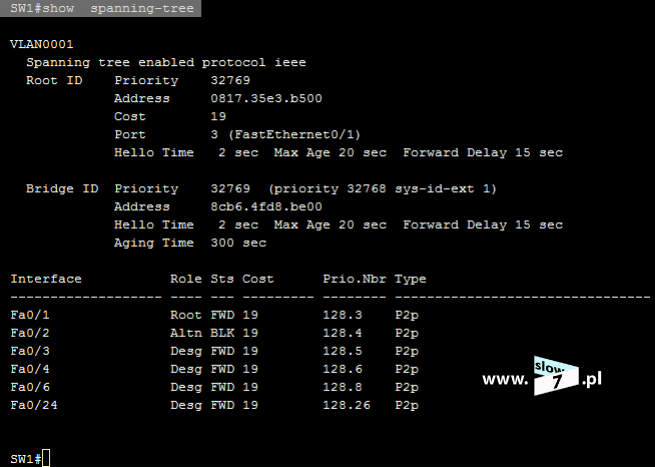
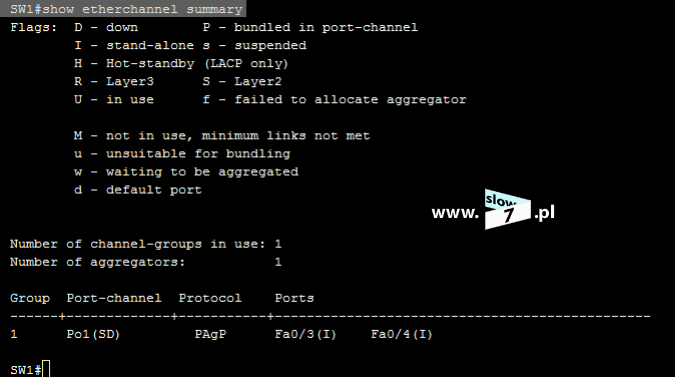
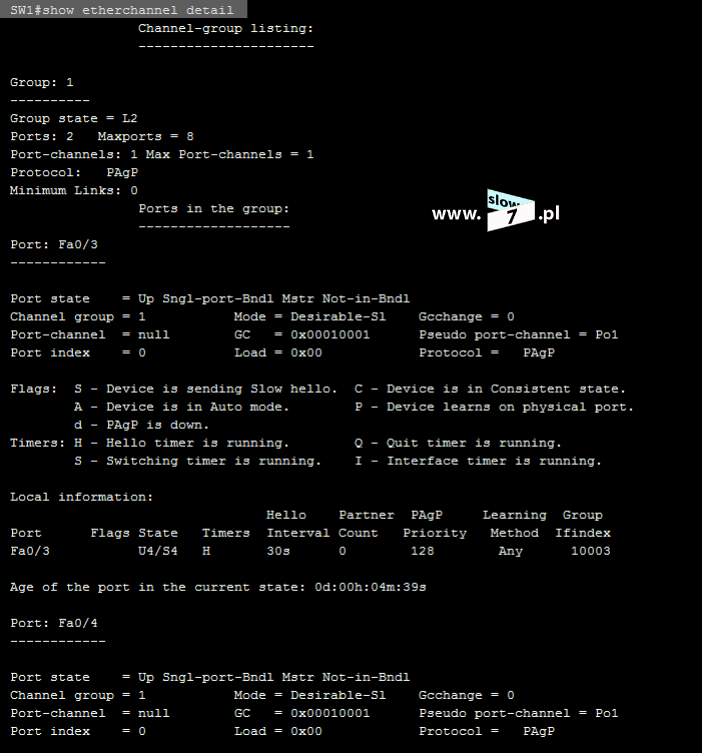
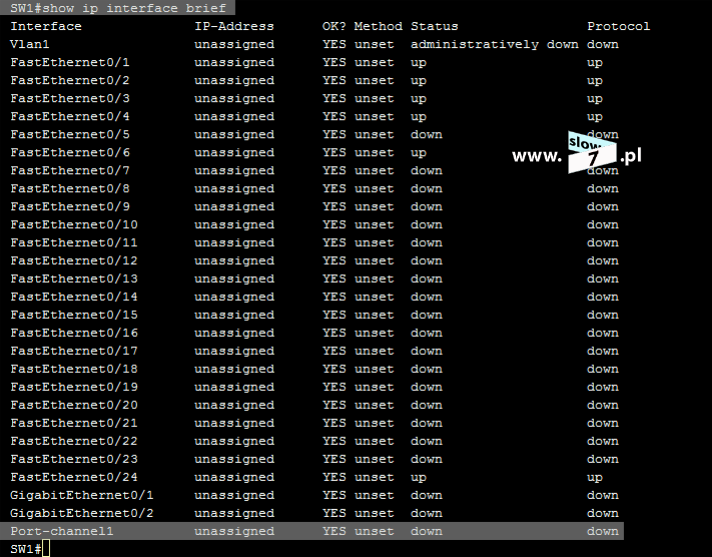
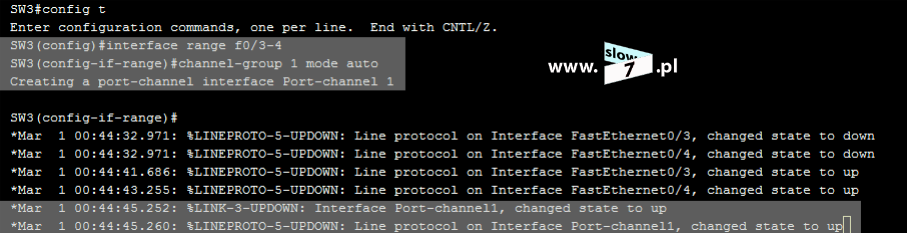
ACL to lista z zdefiniowanymi instrukcjami zezwoleń bądź zakazów, która jest wykonywana sekwencyjnie (od góry do dołu). Instrukcje zawierają informacje o adresach IP, protokołach, numerach portów co do których ma być podjęta decyzja o odrzuceniu bądź przepuszczeniu danego pakietu.
Zastosowanie list ACL sprowadza się do:
Zapewnienie zabezpieczeń podczas dostępu do sieci - główny cel stosowania list ACL czyli kontrola nad dostępnością obszarów naszej sieci bądź usług, mówiąc prościej – tam gdzie jeden host ma umożliwiony dostęp, to drugiemu ten dostęp jest ograniczany. Dzięki listą ACL administrator ma możliwość definiowania obszarów oraz ich dostępności dla poszczególnych urządzeń budujących sieć.
Możliwość decydowania o typie przenoszonego ruchu sieciowego – w ramach listy ACL mogą zostać zdefiniowane dozwolone protokoły oznacza to możliwość przyznawania i odbierania użytkownikom praw dostępu do określonych usług np. dozwolony jest ruch sieciowy w ramach komunikacji WWW ale już ruch FTP nie.
Kontrola nad aktualizacjami tras routingu – listy ograniczają dostarczanie aktualizacji tras w ramach protokołu dynamicznego odpowiedzialnego za routing w sieci.
Ograniczenie ruchu w sieci i zwiększenie wydajności - np. blokada streamingu video spowoduje zmniejszenie obciążenia sieci przez co zwiększy się jej wydajność.
Decyzja o przepuszczeniu bądź odrzuceniu pakietu może być podejmowana w oparciu o takie informacje jak:
- źródłowy adres IP,
- docelowy adres IP,
- źródłowy numer portu,
- docelowy numer portu,
- protokół,
- inne (np. rodzaj wiadomości ICMP).
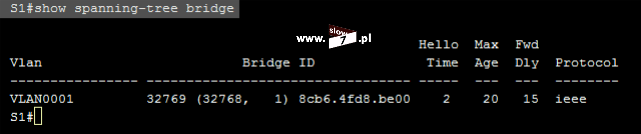
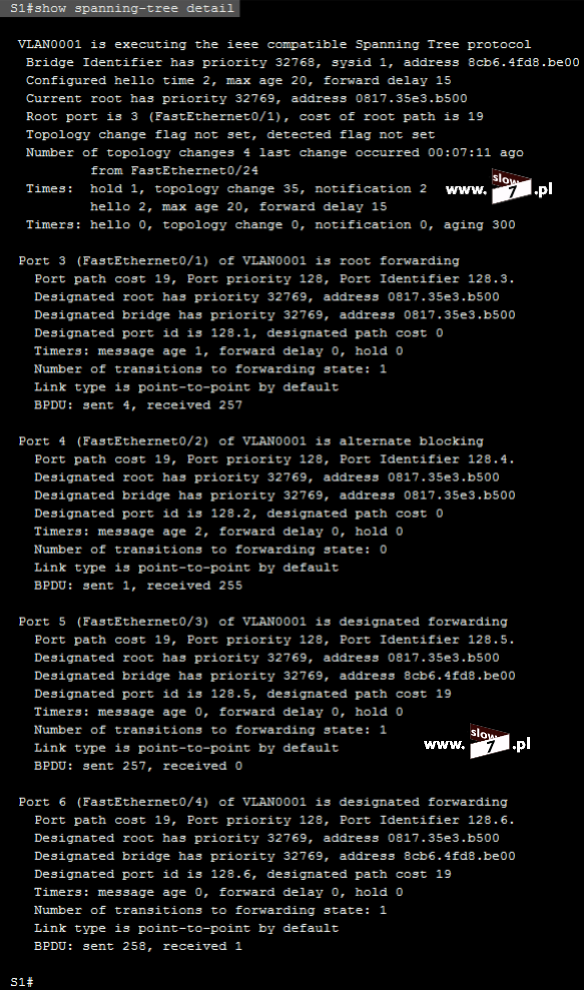
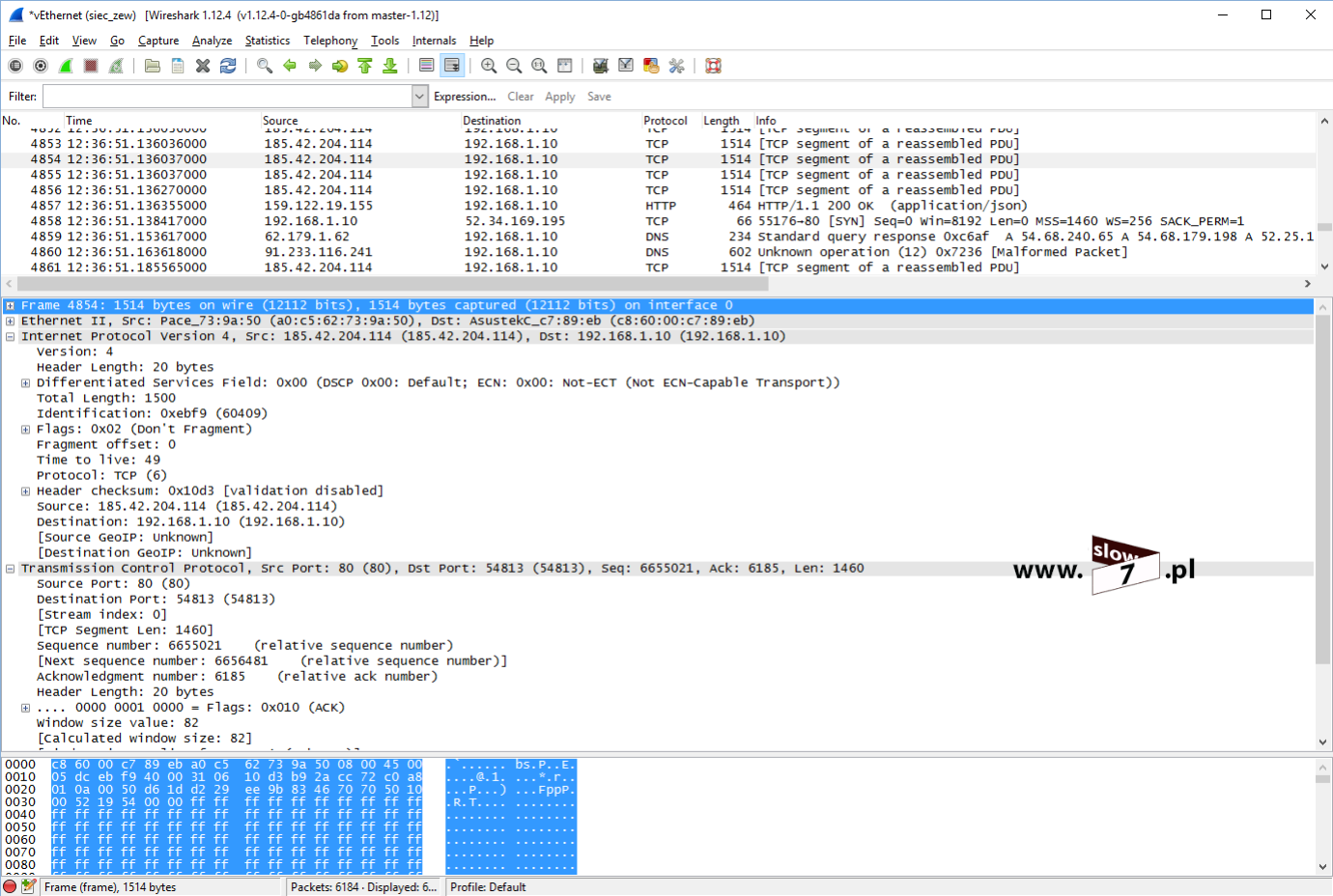
Gdy pakiet przechodzi przez dany interfejs routera do którego została przypisana lista ACL, jest ona przeglądana od góry do dołu, linijka po linijce celem wykrycia dopasowania z informacją zawartą w nagłówku pakietu.
Pierwsza linijka ACL, co do której nastąpi dopasowanie jest stosowana – jeśli w warunku listy została zdefiniowana instrukcja typu permit, pakiet jest przepuszczany, jeśli zaś w warunku istnieje instrukcja typu deny, pakiet jest odrzucany.
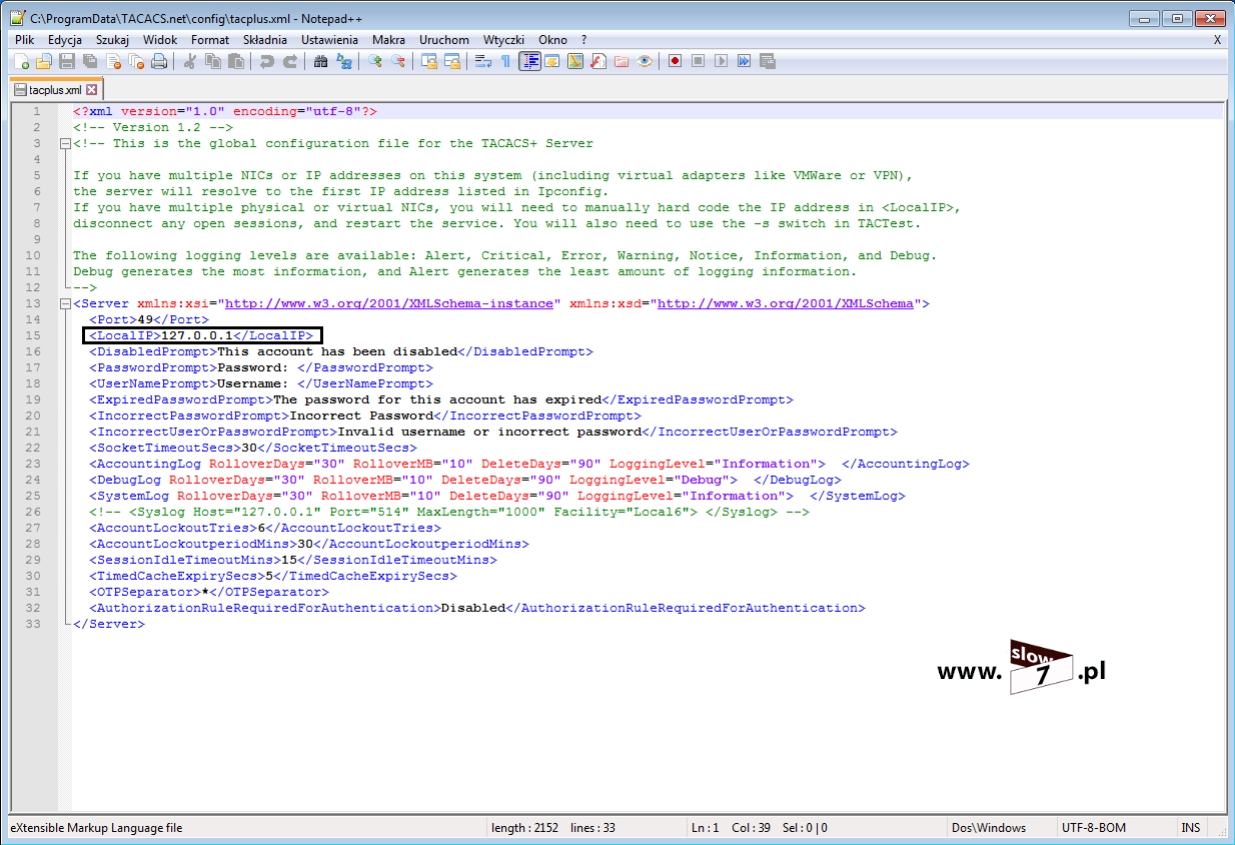
Kolejne warunki listy ACL nie są sprawdzane !!!!!!
Domyślnie na żadnym interfejsie nie ma założonych list ACL.
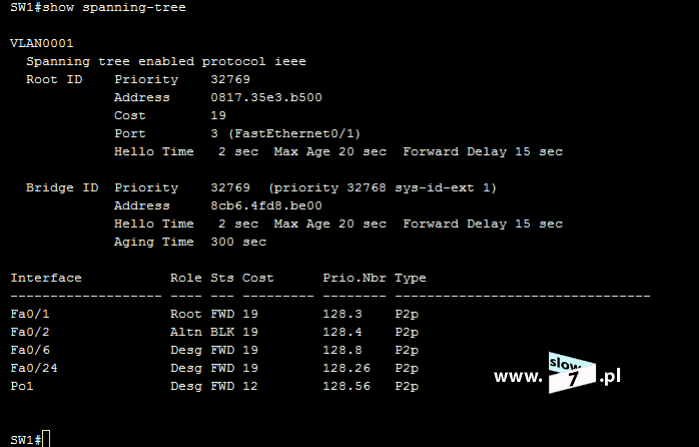
Listy ACL najczęściej zakłada się na routerach brzegowych czyli na styku sieci wewnętrznej a Internetem. Listy ACL również często są definiowane na routerach łączących dwa odrębne obszary sieci - np. sieć dla pracowników i sieć dla uczniów czy pomiędzy sieciami VLAN.
Listy ACL są definiowane osobno dla każdego protokołu (choć przy obecnej dominacji IP nie ma to już tak dużego znaczenia), kierunku oraz interfejsu.
- per protocol – na protokół,
- per direction – na kierunek,
- per interface – na interfejs.
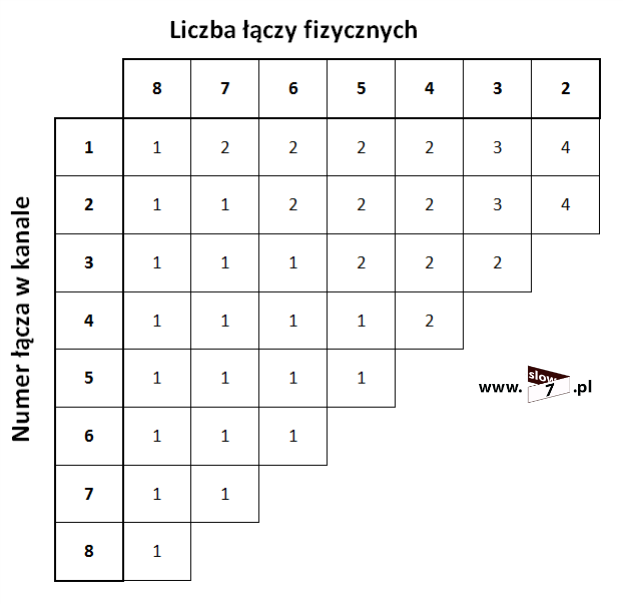
Jedna lista ACL kontroluje ruch na interfejsie w jednym kierunku (wejście: in bądź wyjście: out) dla danego protokołu. Jeśli router ma dwa interfejsy skonfigurowane dla protokołów IP, AppleTalk i IPX, potrzebnych będzie 12 oddzielnych list ACL.
2 interfejsy x 3 protokoły x 2 kierunki = 12 list ACL
Listy ACL są definiowane w trybie konfiguracji globalnej routera.
Podczas konfigurowania listy ACL należy jej nadać unikalny identyfikator (nie mogą istnieć dwie listy o tych samych identyfikatorach). Identyfikatorem listy ACL jest liczba.
Tworzenie listy dostępu następuje z wykorzystaniem polecenia: access-list <numer> <parametry>
Numer listy określa jej rodzaj.
Numery list ACL zostały określone następująco:
<1-99> - standardowa lista dostępu IP
<100-199> - rozszerzona lista dostępu IP
<1000-1099> - lista dostępu IPX SAP
<1100-1199> - rozszerzona lista dostępu 48-bitowych adresów MAC
<1200-1299> - lista dostępu adresu skonsolidowanego IPX
<1300-1999> - standardowa lista dostępu IP (rozszerzony zakres)
<200-299> - lista dostępu typu-kodu protokołu
<300-399> - lista dostępu DECnet
<600-699> - lista dostępu Appletalk
<700-799> - lista dostępu 48-bitowych adresów MAC
<800-899> - standardowa lista dostępu IPX
<900-999> - rozszerzona lista dostępu IPX
<2000-2699> - rozszerzona lista dostępu IP (rozszerzony zakres)
Podczas budowy warunków tworzących daną listę ACL należy zdefiniować sposób działania tzn. czy zezwalamy na dostęp (permit) czy go odbieramy (deny):
access-list numer permit ... lub access-list numer deny ...
Po zdefiniowaniu sposobu działania określamy adres IP lub nazwę hosta.
access-list numer permit A.B.C.D ... lub access-list numer deny A.B.C.D ...
Kolejnym krokiem jest definicja tzw. maski blankietowej określającej zakres adresów co do których warunek listy będzie miał zastosowanie. Lecz tu na chwilę zatrzymajmy się gdyż wprowadzanie na tym etapie pojęcia maski blankietowej zbyt by sprawę zagmatwało i przyjmijmy na ten moment, że lista ACL została zdefiniowana. Do tematu oczywiście wrócimy w dalszej części wpisu.
Po utworzeniu listy ACL nie można zapomnieć o przypisaniu jej do interfejsu routera.
Aby „założyć” listę na danym interfejsie routera przechodzimy do trybu konfiguracji interfejsu i za pomocą komendy: ip access-group <lista_ACL> {in|out} dokonujemy powiązania listy ACL z interfejsem (lista ACL będzie działała na wybranym interfejsie).
ip access-group numer_listy_dostępu in lub ip access-group numer_listy_dostępu out
Określenie in lub out określa listę jako wejściową lub wyjściową.
W routerach Cisco stosowane są dwa zasadnicze rodzaje ACL:
- listy standardowe (ang. standard ACL),
- listy rozszerzone (ang. extended ACL).
Różnica pomiędzy typem użytej listy sprowadza się do:
lista standardowa - jedynym kryterium, na podstawie którego router filtruje pakiety jest źródłowy adres IP,
lista rozszerzona - mają dużo większe możliwości, gdyż budowa warunku listy według, którego będzie prowadzona filtracja pakietów jest możliwa na podstawie: źródłowego adresu IP, docelowego adresu IP, źródłowego bądź docelowego numer portu, protokołu oraz informacji innych jak np. już wyżej wspomniany rodzaj wiadomości ICMP.
Zarówno listy standardowe, jak i rozszerzone mogą być:
Konfigurując numerowaną listę ACL przypisujemy jej numer:
- z zakresów 1-99 lub 1300-1999, jeśli chcemy stworzyć listę standardową,
- z zakresów 100-199 lub 2000-2699 jeśli chcemy stworzyć listę rozszerzoną.
W przypadku list nazywanych każdej liście przypisujemy unikalną nazwę, która powinna składać się ze znaków alfanumerycznych (przyjęło się używanie zapisu wielkimi literami – choć oczywiście to tylko sugestia). Lista nazywana nie może zawierać znaku spacji oraz zaczynać się od cyfry.
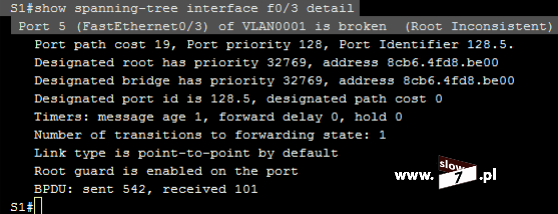
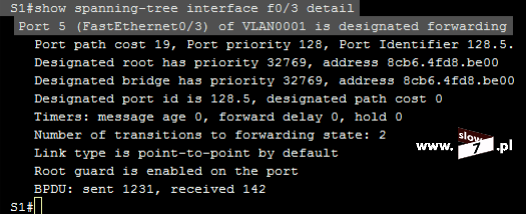
Poniżej na schemacie blokowym przedstawiono schemat działania listy ACL wejściowej (dla tych niewtajemniczonych z algorytmami - prostokąt w schemacie blokowym oznacza wystąpienie czynności zaś romb jest warunkiem, który kończy się podjęciem decyzji - analogią do warunku jest funkcja JEŻELI używana m.in w Excelu). Analizowanie danego pakietu rozpoczyna się gdy pakiet trafia do routera. Porównywane są dane zawarte w pakiecie z instrukcjami zawartymi w liście ACL. Porównywanie danych następuje do pierwszego trafienia. Jeśli takowe dopasowanie następuje to jest dane zawarte w odebranym pakiecie pokrywają się z instrukcjami zawartymi w liście ACL następuje przerwanie przetwarzania listy ACL (reszta warunków tworzących listę ACL jest ignorowana). Co do pakietu następuje decyzja o jego odrzuceniu bądź przekazaniu go dalej - wszystko zależy od treści zdefiniowanej instrukcji. Przetwarzanie listy ACL trwa tak długo aż nastąpi dopasowanie bądź zostanie wyczerpana lista nagłówków. Po sprawdzeniu wszystkich instrukcji i braku wystąpienia dopasowania odebrany pakiet jest odrzucany - pakiet trafia do „kosza” na wskutek działania nie jawnej instrukcji: deny any. Instrukcja ta jest domyślnie dołączana do każdej listy ACL a jej działanie odnosi się do tych pakietów, które nie spełniły żadnego z warunków zdefiniowanych w sprawdzanej liście ACL (brak wystąpienia dopasowania warunku do danych zawartych w nagłówku pakietu).

Oprócz list ACL zdefiniowanych na wejściu są jeszcze te, które mogą być przypisane do interfejsu wyjściowego (lista ACL ma zastosowanie do pakietów opuszczających router). Schemat blokowy działania takiej listy został przedstawiony na schemacie blokowym zamieszczonym poniżej.
Jak można zauważyć schemat podejmowania decyzji w przypadku zastosowania listy ACL na interfejsie wyjściowym przebiega inaczej niż to ma miejsce w przypadku pakietu, który do routera zostaje dostarczony.
Pierwszą decyzją do rozstrzygnięcia pozostaje fakt czy otrzymany pakiet router jest w stanie w ogóle przekazać - czy istnieje droga, którą pakiet mógłby bez przeszkód trafić do adresata. Istnienie drogi router określa na podstawie wpisów zawartych w swojej tablicy routingu. Jeśli otrzymany pakiet nie ma szans dotarcia do odbiorcy z powodu braku wpisu o sposobie jego dotarcia, to po co ma być on analizowany przez listę ACL. Spełnienie warunku routowalności pakietu (czyli istnienia drogi osiągnięcia celu) jest niezbędne by pakiet ten mógł być analizowany przez listę ACL. W przypadku braku wpisu w tablicy routingu o sieci docelowej pakiet zostaje odrzucony. Jeśli na interfejsie wyjściowym została skonfigurowana lista ACL, dane zawarte w nagłówku pakietu są analizowane pod względem ich zgodności z listą instrukcji zdefiniowanych w liście ACL. Przesłanie pakietu dalej jest zależne od spełnienia warunków listy ACL. Tu również ma zastosowanie zasada pierwszego dopasowania a w przypadku jego braku następuje odrzucenie pakietu na wskutek działania nie jawnej instrukcji zabroń.

Ogólny schemat decyzji z uwzględnieniem ewentualnie zdefiniowanych list ACL wejściowych jak i wyjściowych podejmowanych przez router został przedstawiony na schemacie poniżej.

W pierwszej kolejności po odebraniu pakietu sprawdzana jest warstwa druga czyli docelowy adres MAC, jeśli adres MAC nie zgadza się z adresem MAC interfejsu na, którym router odebrał wiadomość pakiet jest odrzucany (no chyba, że mamy do czynienia z ruchem rozgłoszeniowym).
Kolejnym krokiem jest sprawdzenie faktu istnienia listy ACL na interfejsie wejściowym, jeżeli takowa lista ACL została założona następuje sprawdzenie warunków według schematu blokowego opisanego wyżej (patrz schemat dotyczący listy wejściowej). Jeśli zaś listy ACL wejściowej nie ma pakiet danych zostaje przekazany w kierunki interfejsu wyjściowego. I tu podobnie jak w przypadku interfejsu wejściowego jest sprawdzany fakt istnienia listy ACL. W przypadku jej istnienia następuje ciąg czynności i decyzji, które są realizowane według schematu blokowego przynależnego liście wyjściowej. Gdy interfejs wyjściowy pozbawiony jest listy ACL, pakiet jest enkapsulowany do warstw niższych a następnie zostaje wysłany do kolejnego urządzenia (oczywiście pod warunkiem istnienia odpowiednich wpisów w tablicy routingu).
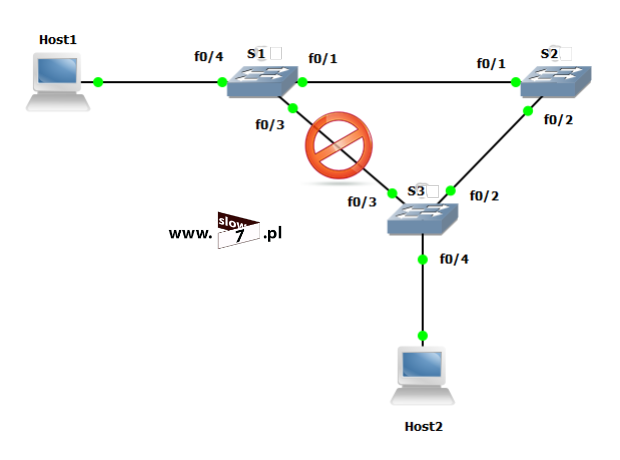
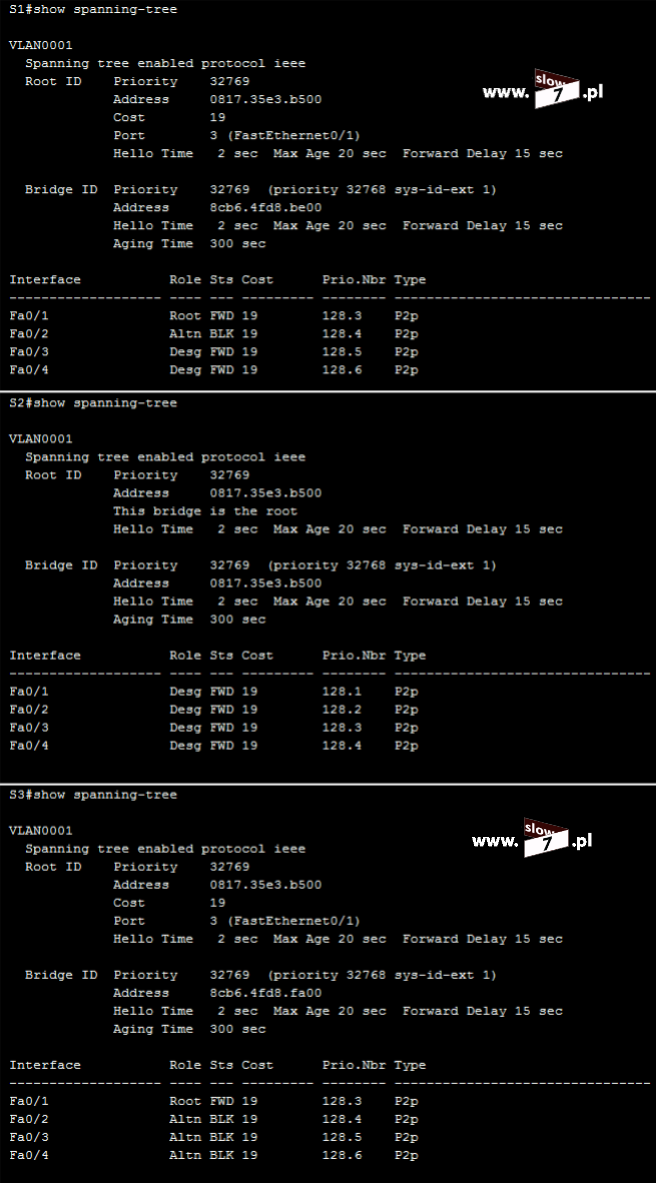
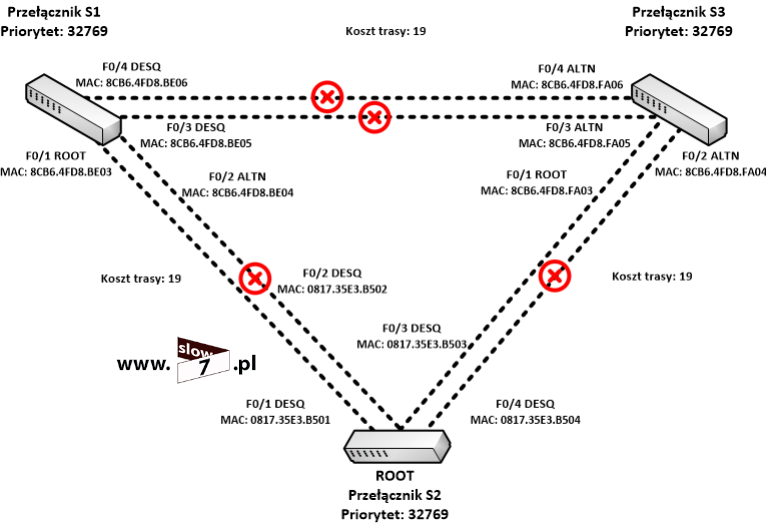
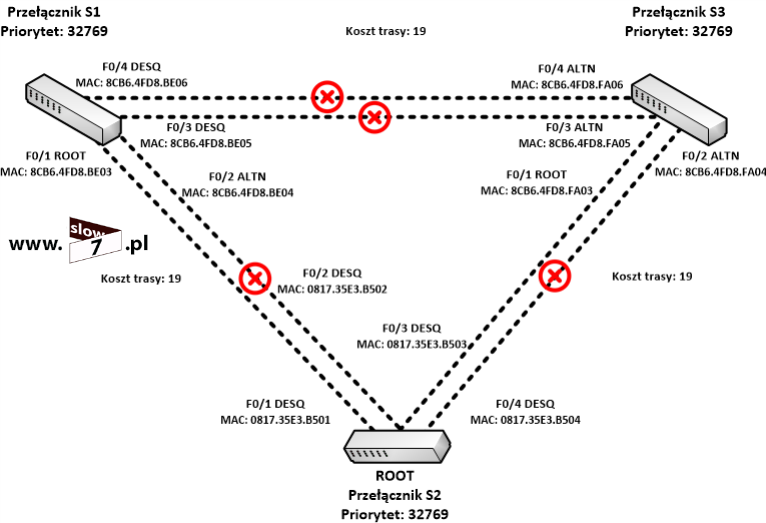
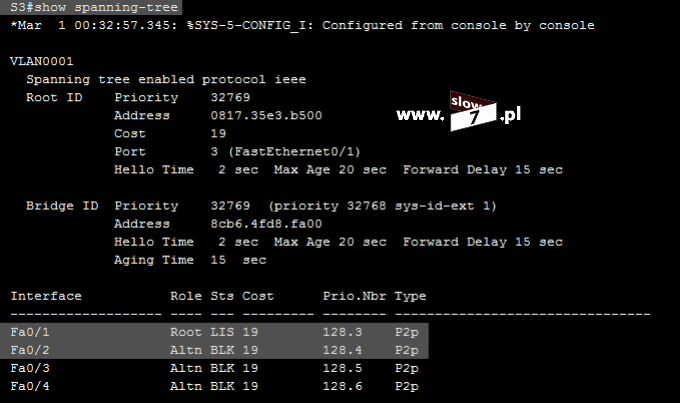
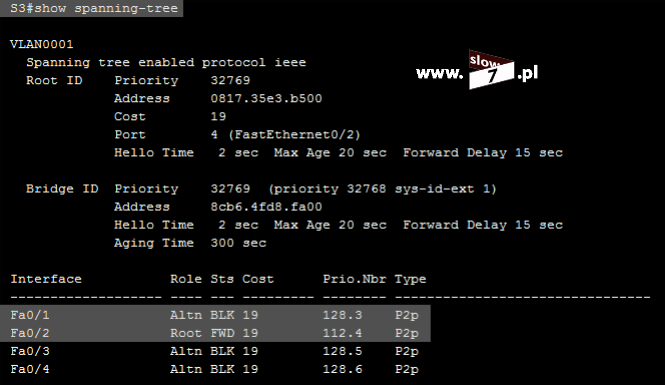
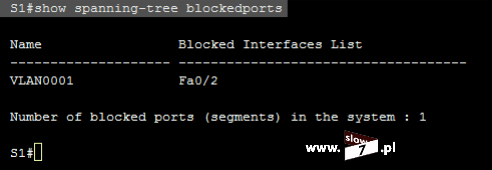
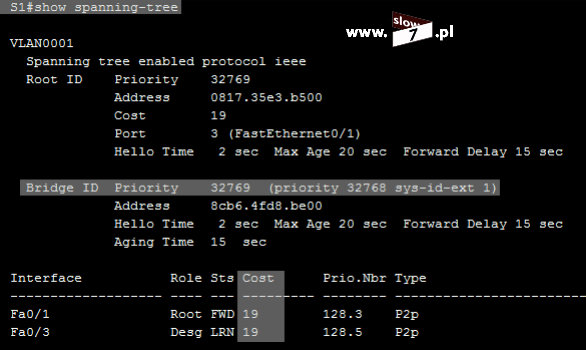
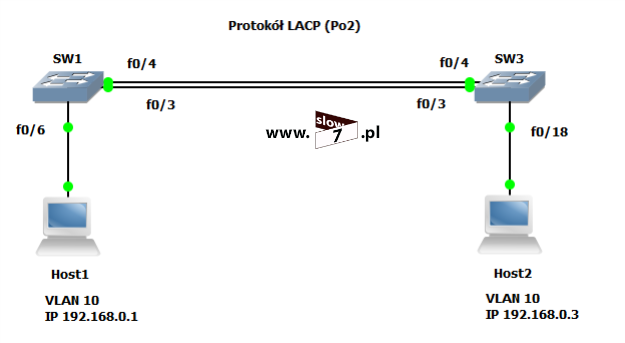
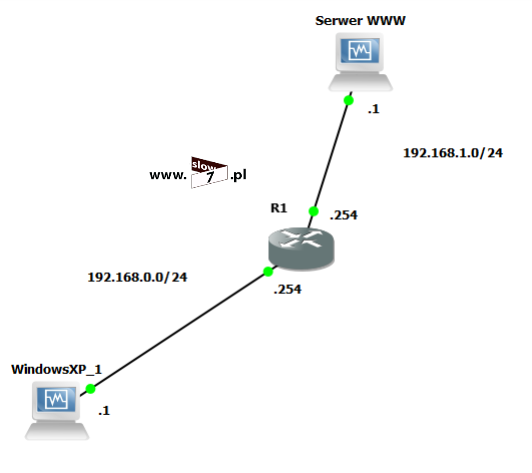
W naszych rozważaniach na temat list ACL posłużymy się topologią sieciową przedstawioną poniżej. Użyte interfejsy wraz z przypisanymi adresami IP oraz adresy sieci zostały przedstawiono również na rysunku poniżej.

Sieć jest zbieżna wszystkie użyte urządzenia mogą ze sobą nawiązać komunikację. Poniżej przedstawiono tablicę routingu wszystkich trzech routerów jak można stwierdzić wszystkie routery są w stanie przekazać pakiety do każdej z sieci. Za aktualizację tablic routingu dba protokół EIGRP.

Rozpoczynamy od pierwszego zadania a naszym celem będzie przy pomocy listy ACL zablokowanie ruchu sieciowego od hosta 10.0.1.10 (WindowsXP_1) do hosta 10.0.3.10 (WindowsXP_3). W przykładzie tym użyjemy standardową listę ACL.
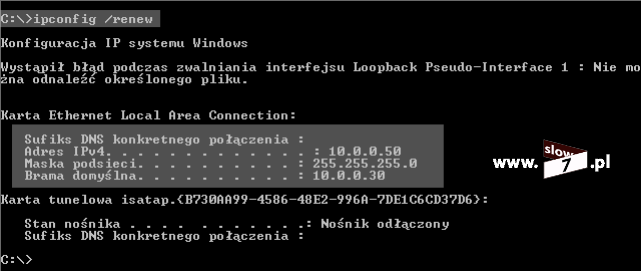
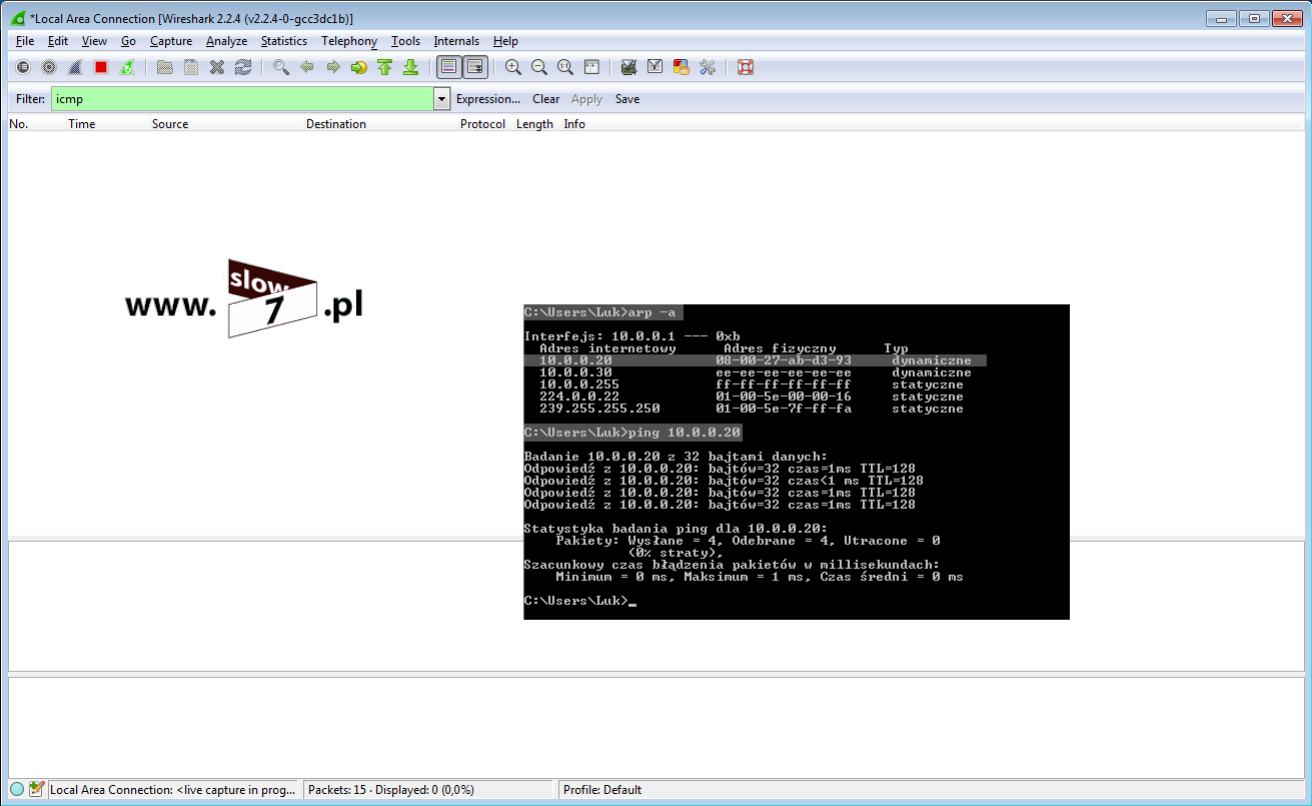
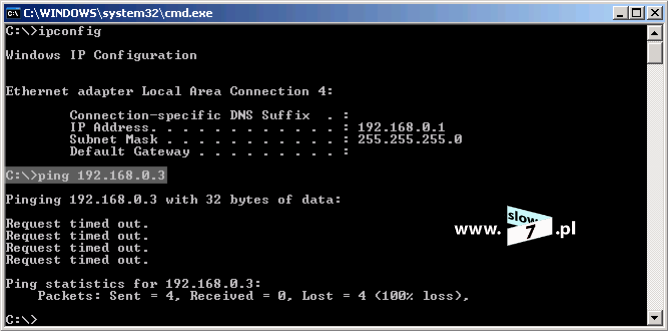
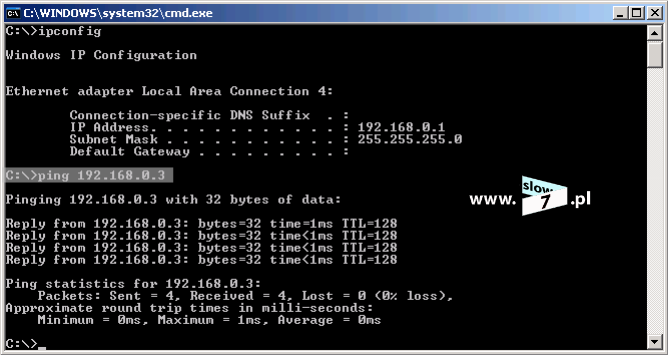
Zanim zaczniemy konfigurować listę ACL sprawdźmy czy hosty mogą ze sobą prowadzić komunikację. Test ping przeprowadzony z hosta o adresie IP 10.0.1.10 w kierunku hosta 10.0.3.10 kończy się sukcesem.

Naszym zadaniem jest uniemożliwienie komunikacji pomiędzy hostami WindowsXP_1 a WindowsXP_3 oczywiście przy założeniu, że możliwość komunikacji pomiędzy pozostałymi urządzeniami sieciowymi nie będzie zakłócona.
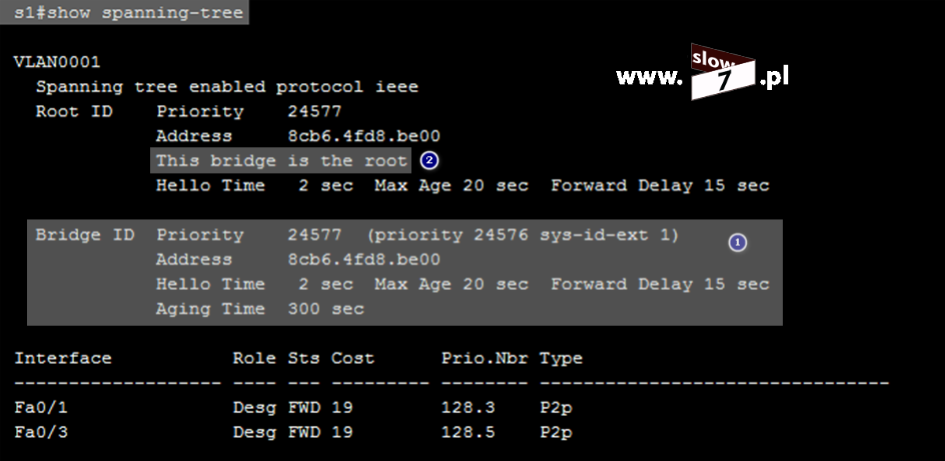
Pierwsze pytanie na które musimy sobie odpowiedzieć - To na którym z trzech ruterów lista ACL ma zostać utworzona? Przyjmijmy, że routerem na którym będzie konfigurowana lista ACL będzie router R1 czyli router najbliższy hostowi WindowsXP_1.
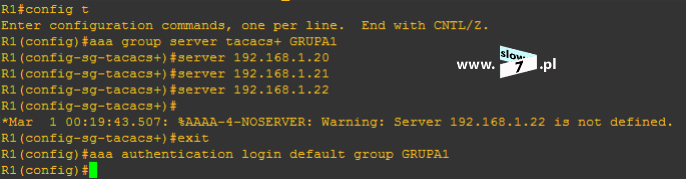
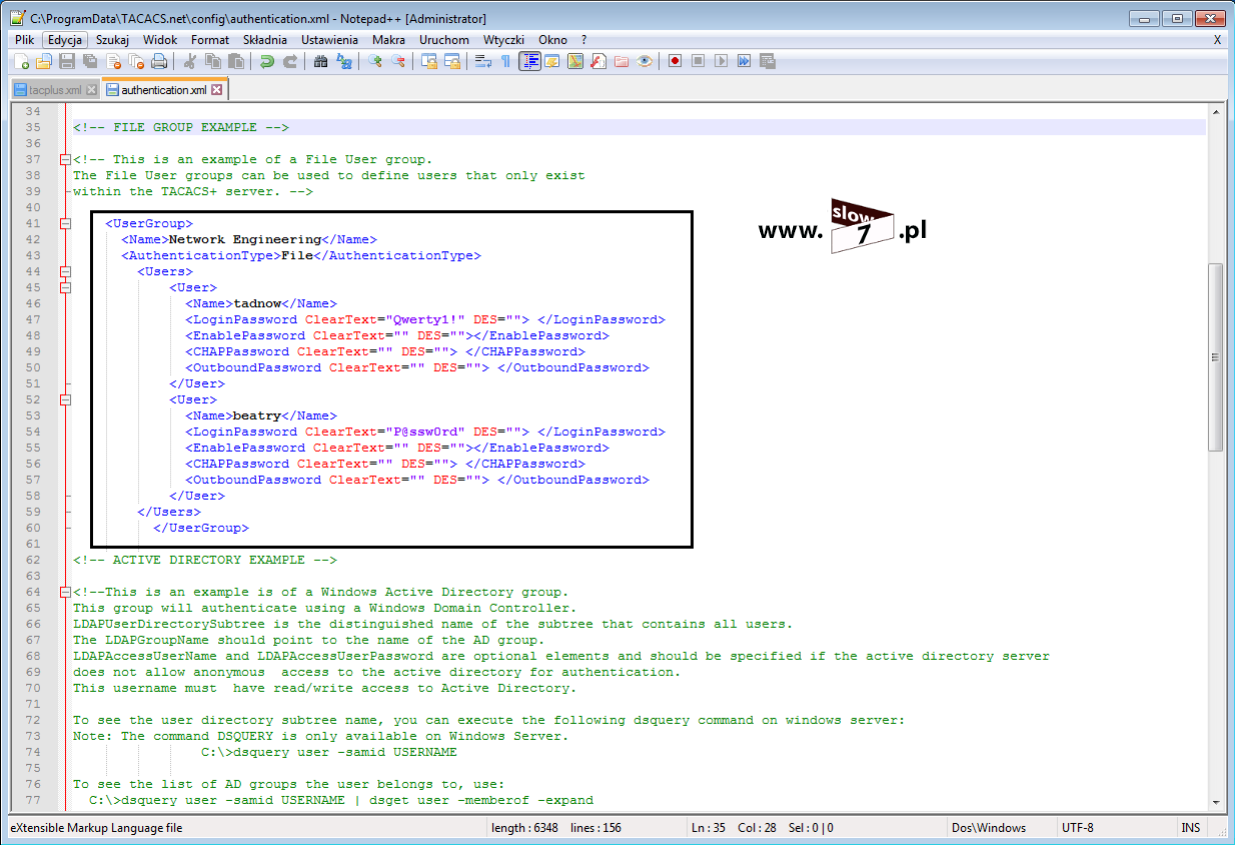
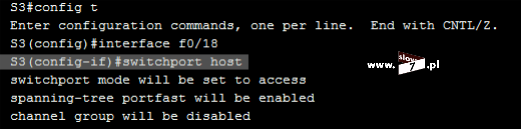
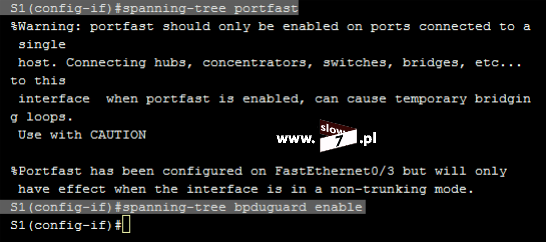
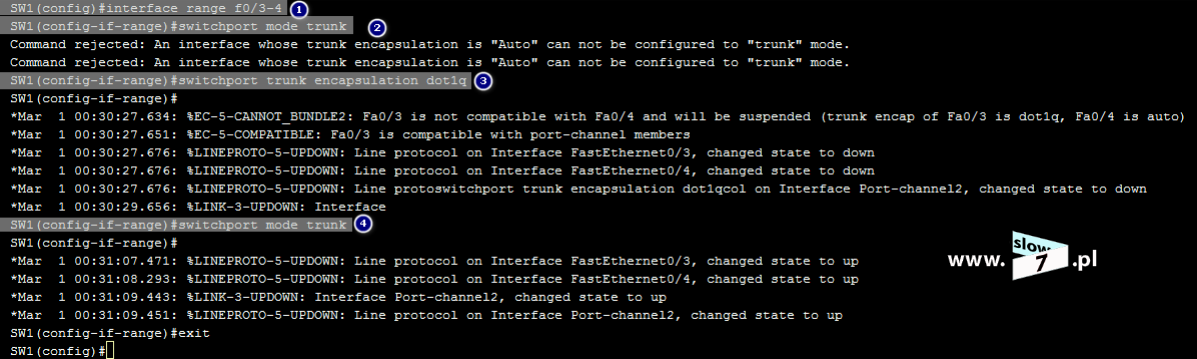
Listę ACL tworzymy w trybie konfiguracji globalnej. Lista ACL zostaje utworzona za pomocą polecenia: access-list 5 deny host 10.0.1.10 Wydanie komendy spowoduje utworzenie standardowej listy ACL o numerze 5. Użyta wartość przypisana jest do zakresu list standardowych. Użycie parametru: deny powoduje zabronienie na prowadzenie komunikacji przez hosta o adresie IP 10.0.1.10. Użycie opcji: host powoduje utworzenie reguły dla pojedynczego komputera.

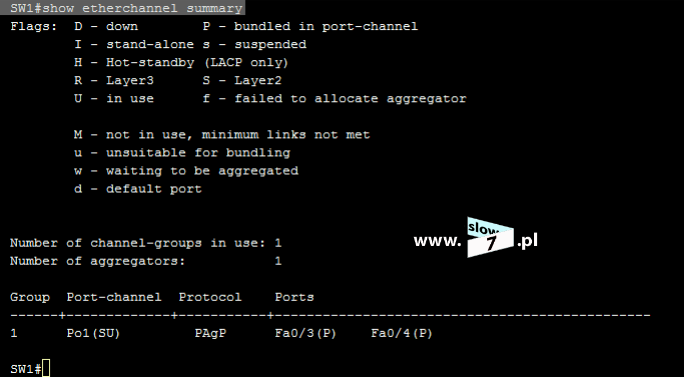
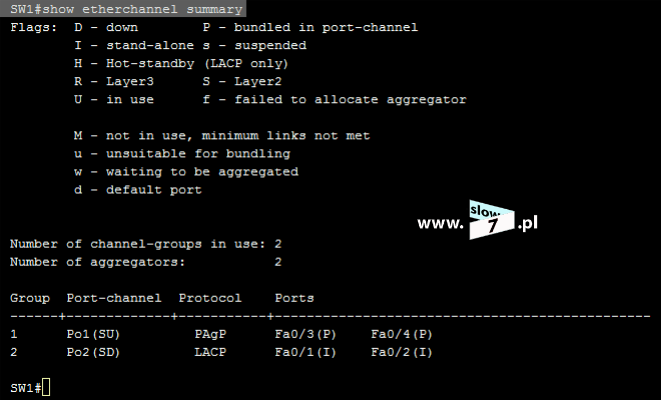
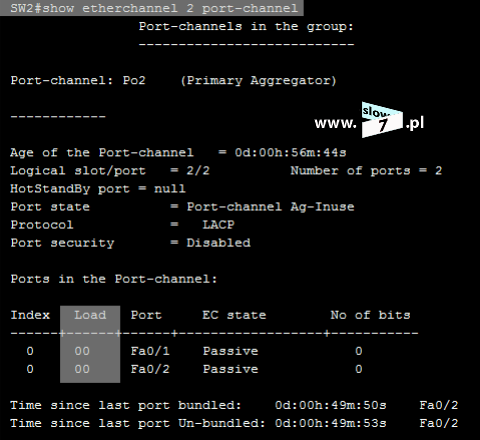
Po zatwierdzeniu polecenia, lista ACL zostaje utworzona. Stan wszystkich list ACL sprawdzimy po wydaniu komendy: show access-list Wydanie polecenia w formacie: show access-list <numer_ACL> spowoduje wyświetlenie ustawień określonej w poleceniu listy.

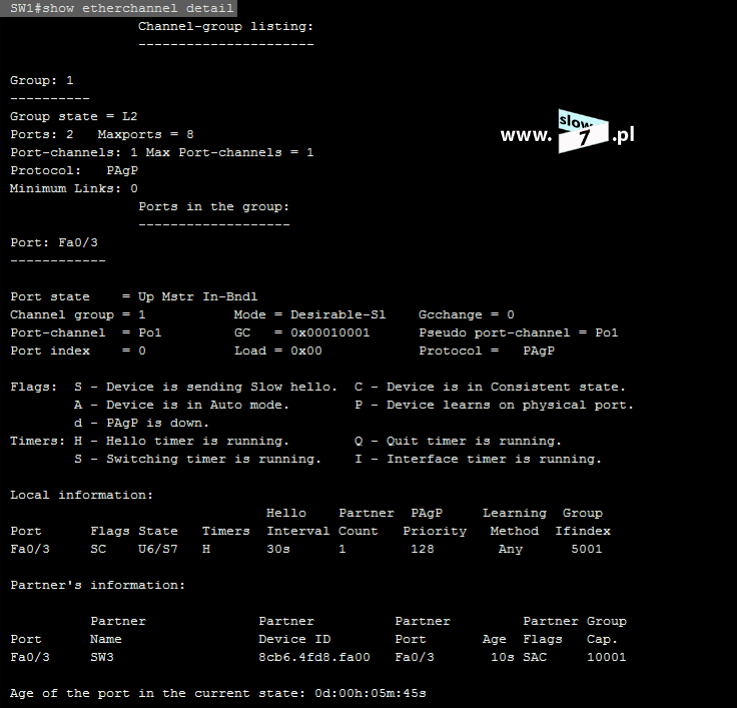
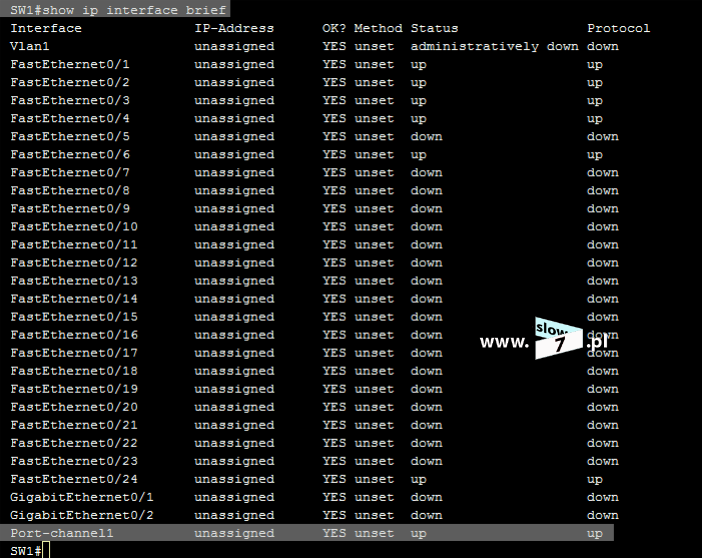
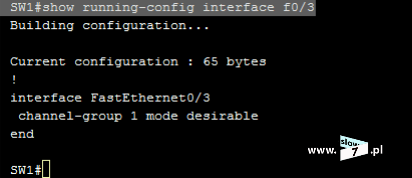
Lecz fakt utworzenia listy nie spowoduje, że będzie ona od razu stosowana. Aby lista mogła spełnić swoje zadanie należy, ją przypisać do interfejsu routera (w naszym scenariuszu jest to router R1). I tu kolejne pytanie - Który interfejs routera R1 wybrać? Decydujemy się na interfejs najbliższy hostowi czyli interfejs f0/0. Przypisanie listy realizujemy za pomocą komendy: ip access-group 5 in. Komendę tą wydajemy oczywiście w trybie konfiguracji interfejsu f0/0. Wydanie polecenia spowoduje przypisanie standardowej listy ACL o numerze 5 do interfejsu f0/0 routera R1. Lista ACL obowiązuje dla ruchu przychodzącego (użyty parametr: in).

Fakt przypisania danej listy do interfejsu sprawdzimy wykorzystując komendę: show running-config

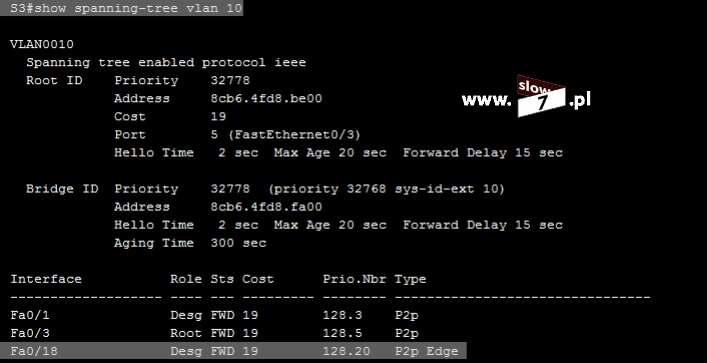
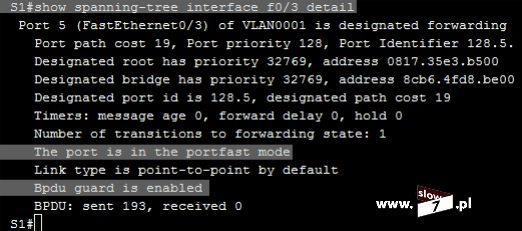
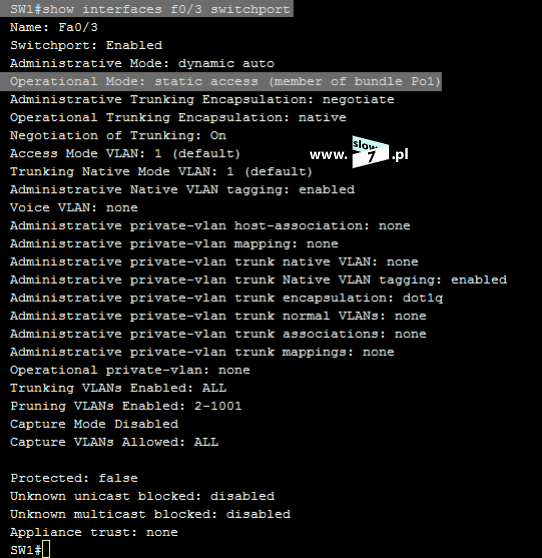
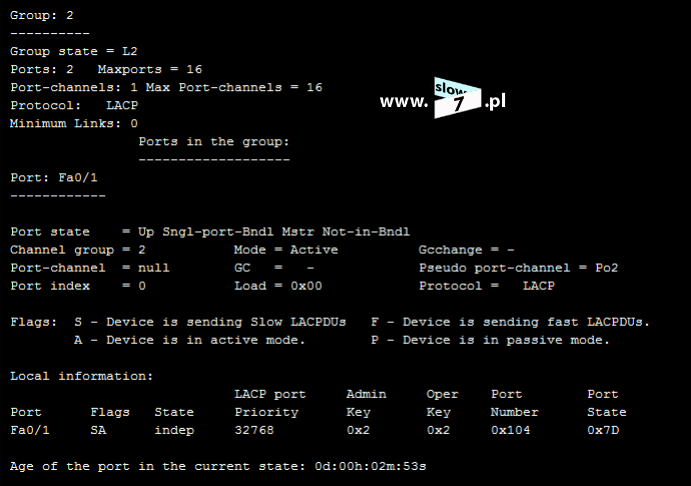
Dodatkowo fakt użycia danej listy również skontrolujemy przy użyciu polecenia: show ip interface <interfejs> Jak widać poniżej nasza lista standardowa o numerze 5 jest przypisana do interfejsu f0/0 a jej działanie obejmuje ruch przychodzący.

Sprawdźmy zatem efekt przeprowadzonej konfiguracji i przeprowadźmy test komunikacji pomiędzy hostami WindowsXP_1 a WindowsXP_3. Jak widać test ping kończy się niepowodzeniem, uzyskaliśmy zamierzony efekt.

Fakt działania listy ACL możemy skontrolować wydając ponownie polecenie: show access-list Nasza lista została użyta 15 razy.

Zadanie zakładało możliwość prowadzenia komunikacji przez inne urządzenia, tak więc wykonajmy sprawdzenie z wykorzystaniem hosta Windows7. Wykonajmy test ping pomiędzy komputerami Windows7 a WindowsXP_3. Test ten kończy się niepowodzeniem a przecież nie o to nam chodziło.

By odpowiedzieć sobie na pytanie - Dlaczego tak się stało? trzeba uzmysłowić sobie w jaki sposób lista ACL jest zbudowana. Każda z list ACL ma wprowadzone przez administratora warunki określające sposób filtrowania ruchu sieciowego. Warunki te są jawne, gdyż zostały utworzone przez administratora. W naszym przykładzie warunkiem jawnym jest wpis zabraniający ruch z hosta 10.0.1.10. Ale każda lista ACL oprócz warunków jawnych posiada domyślne dołączany warunek niejawny: deny any (warunek ten nie jest uwzględniony podczas kontroli listy za pomocą polecenia: show access-lists). Warunek ten zabrania na ruch sieciowy każdemu. Listy ACL przetwarzanie warunków przeprowadzają od góry do pierwszego dopasowania i dlatego też hostowi Windows7 uniemożliwiono przeprowadzenie komunikacji. Dane zawarte w pakiecie wysłanym z komputera Windows7 nie zostały dopasowane do żadnego wpisu jawnego a więc zastosowany został ostatni nie jawny warunek: zabroń
W przypadku testu ping z hosta WindowsXP_1 komunikacja została zablokowana poprzez warunek jawny: deny host 10.0.1.10 natomiast za brak komunikacji pomiędzy hostami Windows7 a WindowsXP_3 odpowiada warunek niejawny: deny any

Co należy wykonać aby umożliwić komunikację pozostałym urządzeniom przypisanym do sieci 10.0.1.0/24? Poprawienie konfiguracji sprowadza się do wydania jednego, dodatkowego polecenia umożliwiającego na przeprowadzenie komunikacji. Tak więc wprowadźmy poprawkę.
Aby inne hosty mogły nawiązać połączenie do już istniejącej listy ACL wprowadźmy dodatkowy warunek - warunek ten zezwoli na nawiązanie połączenia. Aby komputery uzyskały dostęp do hosta WindowXP_3 należy wydać polecenie: access-list 5 permit any - punkt 1.
Wydanie komendy spowoduje dopisanie warunku: permit any (zezwól wszystkim) do już istniejącej listy ACL 5 - punkt 2.

Sprawdźmy efekt wprowadzonej poprawki.
W pierwszej kolejności test ping przeprowadzony z hosta WindowsXP_1 - test zakończony niepowodzeniem - ruch sieciowy został zablokowany poprzez warunek: deny host 10.0.1.10

Test drugi przeprowadzony z hosta Windows7 - test zakończony powodzeniem - zastosowanie pierwszego wpisu: deny 10.0.1.10 do hosta Windows7 nie ma zastosowania ze względu na brak dopasowania (adres IP hosta Windows7 to 10.0.1.20). Zezwolenie na przeprowadzenie komunikacji zostaje udzielone dzięki warunkowi: permit any. Ponieważ lista ACL swe działanie przerywa po dokonaniu dopasowania dlatego też warunek niejawny: deny any nie jest brany pod uwagę.

Efekt działania listy ACL i budujących ją warunków jak już wiesz Czytelniku sprawdzimy dzięki poleceniu: show access-lists

Wydaje się, że osiągnęliśmy zamierzony cel - Ale czy na pewno? Do tej pory wszystko działa jak należy. Host WindowsXP_1 nie ma możliwości komunikacji z komputerem WindowsXP_3, zaś inni pozostali tak. Ale podsieć 10.0.3.0/24 nie jest jedyną siecią w naszej topologii. Sprawdźmy zatem przebieg komunikacji z hostem WindowsXP_2, który należy do sieci 10.0.2.0/24. Sprawdzenia w pierwszej kolejności dokonamy z hosta Windows7. Test ping kończy się sukcesem. Jak na razie wszystko przebiega po naszej myśli.

Kolejny test przeprowadzimy z wykorzystaniem hosta WindowsXP_1. Próba ta niestety jak widać na poniższym zrzucie kończy się niepowodzeniem a niestety nie o to nam chodziło.

Przeprowadzona konfiguracja nie dała nam rozwiązania postawionego przed nami zadania. Zablokowaliśmy komunikację hosta WindowsXP_1 z hostem WindowsXP_3 ale także z innymi urządzeniami poza siecią 10.0.1.0/24 a nie takie były założenia zadania.
Tu Czytelniku przyznam się że specjalnie dobrałem taki wariant rozwiązania zadania i tak poprowadziłem nasze rozważania by pokazać na jakie błędy jesteśmy narażeni przy wdrażaniu mechanizmu ACL.
Nasze zadanie od początku było skazane na porażkę, gdyż już w pierwszym kroku podjęta decyzja o umiejscowieniu listy ACL była decyzją błędną.
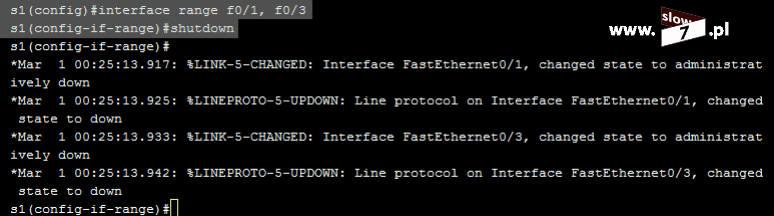
Rozpoczynamy od początku (tym razem już poprawnie) i wracamy do ustawień początkowych. Aby powrócić do ustawień startowych należy usunąć bieżącą konfigurację. Powrót do ustawień początkowych rozpoczynamy od usunięcia listy ACL 5. Usunięcie listy przeprowadzimy za pomocą polecenia: no access-list <numer_listy>

Aby zachować porządek w ustawieniach nie zapominamy o skasowaniu listy ACL na interfejsie f0/0. Przypisaną listę ACL 5 usuniemy za pomocą komendy: no ip access-group <numer_listy> <kierunek>

Powróciliśmy do ustawień startowych.
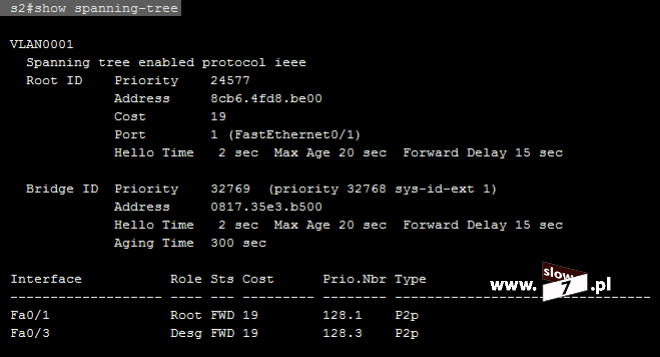
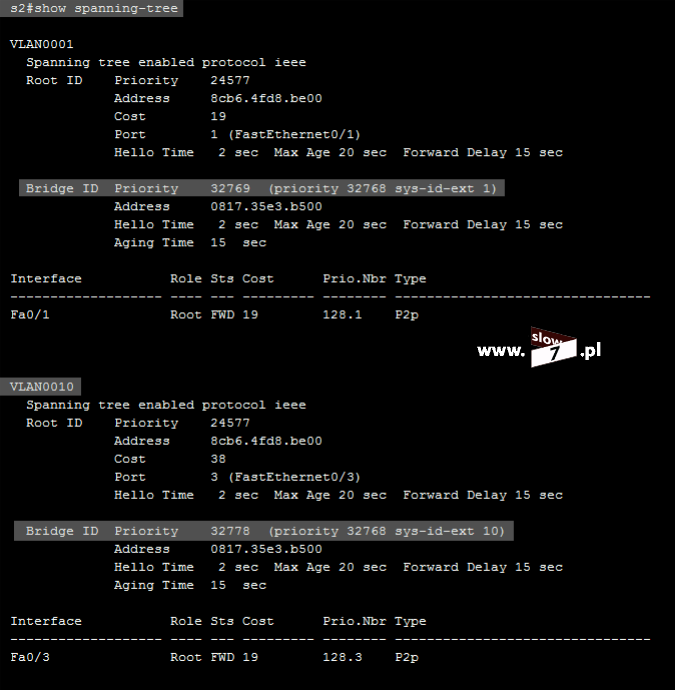
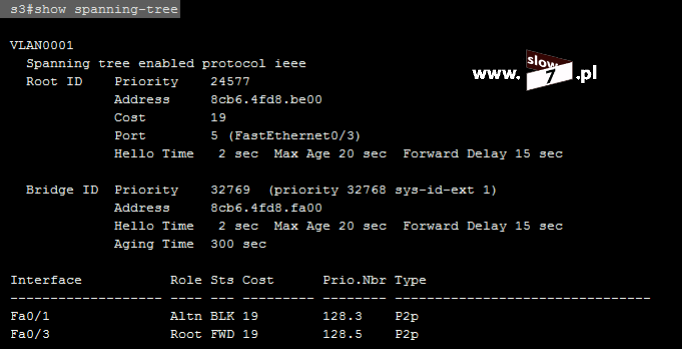
Zamierzone cele osiągniemy tylko wtedy gdy listę ACL umieścimy na routerze R3. I tu dochodzimy do jednej z ważniejszych zasad, którą musimy przestrzegać: Listy standardowe umieszczamy najbliżej celu, którego lista dotyczy. W naszym przypadku celem jest uniemożliwienie komunikacji hosta 10.0.1.10 z hostem 10.0.3.10. Najbliżej celu czyli komputera WindowsXP_3 znajduje się router R3. Tak więc lista ACL powinna zostać skonfigurowana na tym routerze.
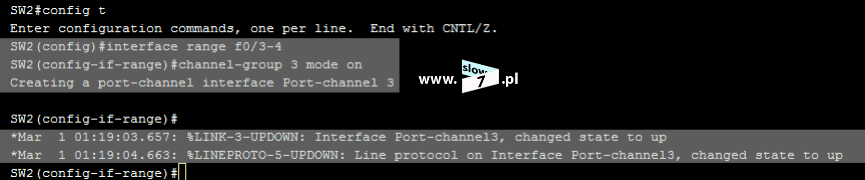
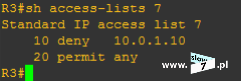
Warunki zapisane wewnątrz listy ACL będą tożsame z tymi zdefiniowanymi na routerze R1. Tym razem konfigurowana standardowa lista ACL przyjmie numer 7 (tak by nam się nie myliło).
Rozpoczynamy od zablokowania komunikacji pomiędzy hostami WindowsXP_1 a WindowsXP_3 – warunek: deny host 10.0.1.10 – punkt 1.
Mając na uwadze istnienie niejawnego warunku: deny any poprzez wydanie polecenia: access-list 7 permit any zezwalamy na łączność pozostałym hostom – punkt 2.
Punkt 3 jest sprawdzeniem poprawności warunków zawartych w tworzonej liście ACL.

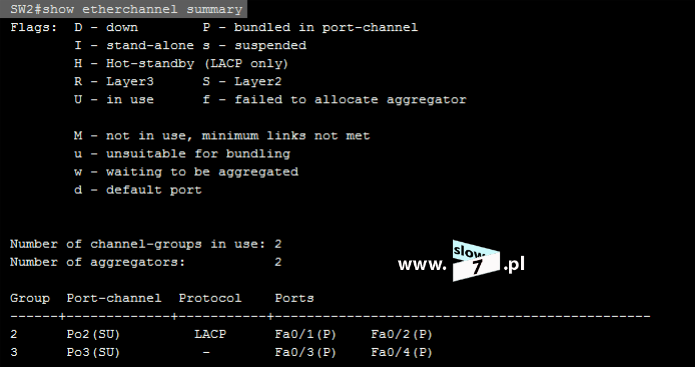
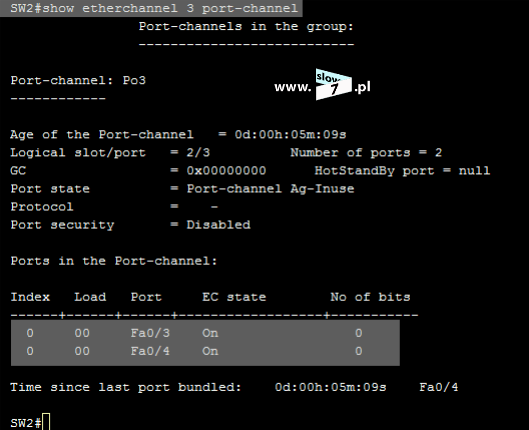
Lista ACL o numerze 7 została utworzona. Aby lista mogła pełnić swoją rolę należy ją oczywiście przypisać do interfejsu routera R3. W grę wchodzą dwa interfejsy (gdyż w przyjętej topologii router R3 ma dwa aktywne interfejsy sieciowe) f0/0 oraz s0/1. Przy wyborze interfejsu kierujemy się znaną nam już zasadą – wybieramy ten, który znajduje się najbliżej celu. Tak więc po analizie topologii stwierdzamy, iż najbliżej celu znajduje się interfejs f0/0. Na interfejsie tym zostaje skonfigurowana lista ACL 7.
Polecenie łączące interfejs z listą ACL wymaga od nas zdefiniowanie kierunku działania listy, ponowna analiza topologii sieci przekonuje nas iż kierunek działania listy musi zostać ustawiony na wyjście.

Lista ACL została skonfigurowana i przypisana do interfejsu. Sprawdźmy zatem jak będzie przebiegać komunikacja po zastosowaniu poprawek.
Pierwszy test zostanie przeprowadzony z komputera WindowsXP_1. Test kończy się sukcesem – niemożliwa jest komunikacja z blokowanym przez listę ACL hostem WIndowsXP_3 przy zachowaniu możliwości nawiązania połączenia z innymi urządzeniami w naszej sieci (test ping pomiędzy WindowsXP_1 a WindowsXP_2 kończy się sukcesem).

Test drugi to sprawdzenie komunikacji pomiędzy komputerem Windows7 a hostami WindowsXP_2 oraz WindowsXP_3. Test ten również kończy się powodzeniem.

Założenia zadania zostały spełnione. Komunikacja pomiędzy hostem WindowsXP_1 a WindowsXP_3 została zablokowana, lista ACL działa prawidłowo.
W złożonej topologii sieciowej może istnieć wiele list ACL, które mogą być umiejscowione na różnych urządzeniach. Dlatego warto w sobie wyrobić nawyk opisywania tworzonych list ACL.
Aby dodać komentarz do listy ACL należy skorzystać z polecenia: access-list <numer_listy> remark <komentarz> Poniżej przykład dodania komentarza do utworzonej w poprzednim kroku listy ACL.

Komentarz do listy ACL możemy sprawdzić przeglądając konfigurację bieżącą routera. Opis listy ACL nie jest wyświetlany po wydaniu komendy: show access-list

Dosyć częstą praktyką przy opisywaniu list ACL jest dodanie komentarza, który odsyła nas do pliku zewnętrznego a dopiero w tym pliku zawarty jest dokładny opis i przeznaczenie listy ACL. Metoda ta poniekąd zwiększa bezpieczeństwo naszej sieci gdyż w razie przejęcia przez atakującego kontroli nad routerem, poznanie sposobu działania naszej sieci nie przyjdzie mu tak łatwo. Komentarze do list ACL są bogatym źródłem wiedzy dla hakera.
Podczas definicji list ACL użyteczną opcją może być zastosowanie parametru: log który powoduje wyświetlenie w konsoli komunikatu związanego z dopasowaniem. Oznacza to, że gdy wystąpi spełnienie warunku zdefiniowanego na liście ACL zostaniemy o tym poinformowani stosownym komunikatem.
Logowanie informacji o zdarzeniu może nastąpić w:
- linii poleceń konsoli,
- wewnętrzny bufor,
- serwer syslog.
Informacje, które podlegają rejestrowaniu to:
- akcja – zezwól (permit) lub zablokuj (deny),
- użyty protokół - TCP, UDP lub ICMP,
- adres źródłowy i docelowy,
- w przypadku TCP oraz UDP – numer portu źródłowego i docelowego,
- w przypadku ICMP – typy wiadomości.
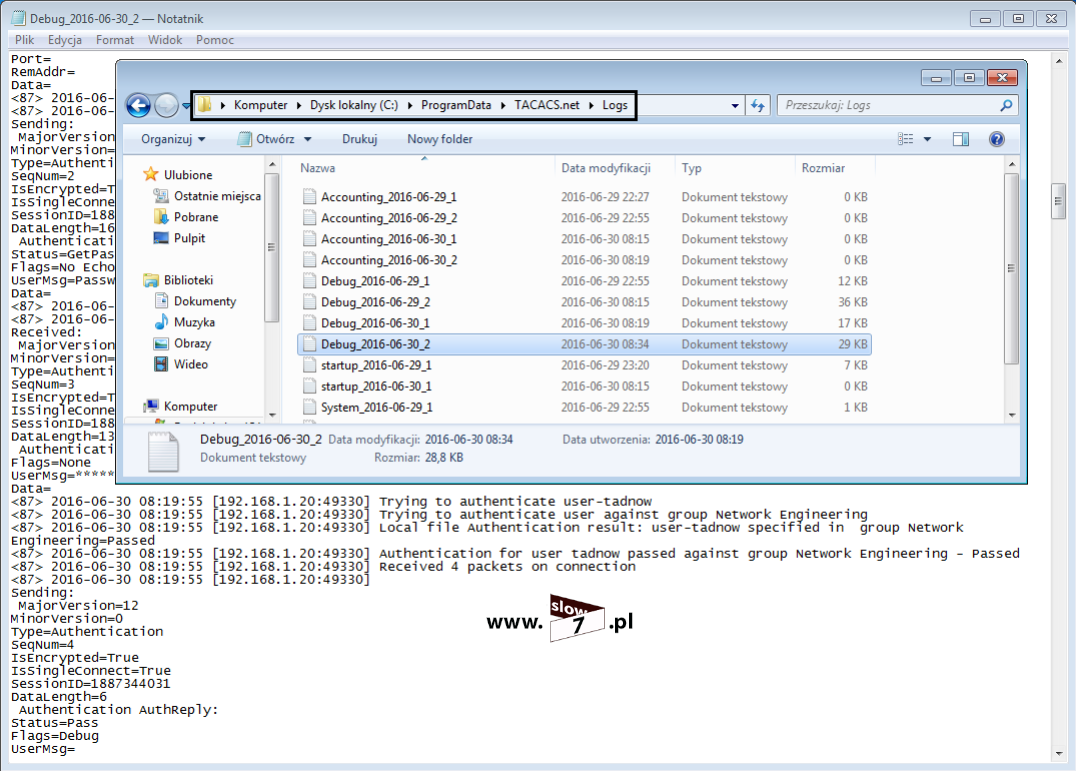
Aby włączyć logowanie informacji o wystąpieniu zdefiniowanego warunku listy ACL po definicji warunku dodajemy flagę: log – pozostajemy przy przykładzie w którym blokujemy ruch z hosta 10.0.1.10

Logowanie warunku zabraniającego na połączenie pomiędzy hostem 10.0.1.10 a siecią 10.0.3.0/24 zostało włączone.
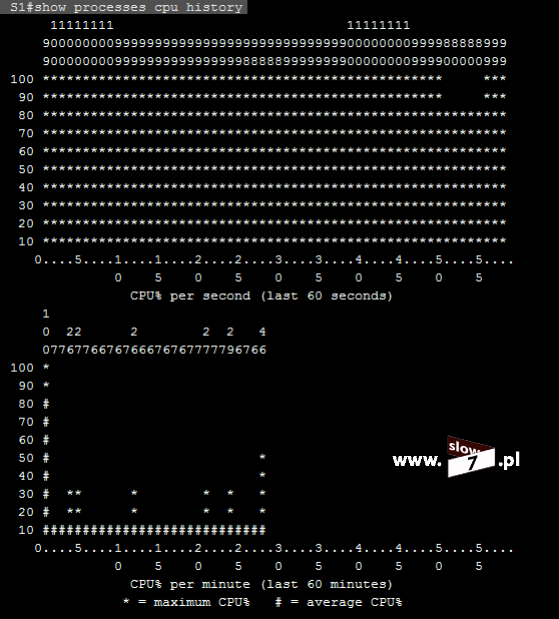
W przypadku wystąpienia zdarzenia zostaniemy o nim powiadomieni. Logi są generowane przy wystąpieniu zdarzenia (pierwszy pakiet, który spełnia warunek) a następnie w pięciominutowych odstępach po wystąpieniu zdarzenia.
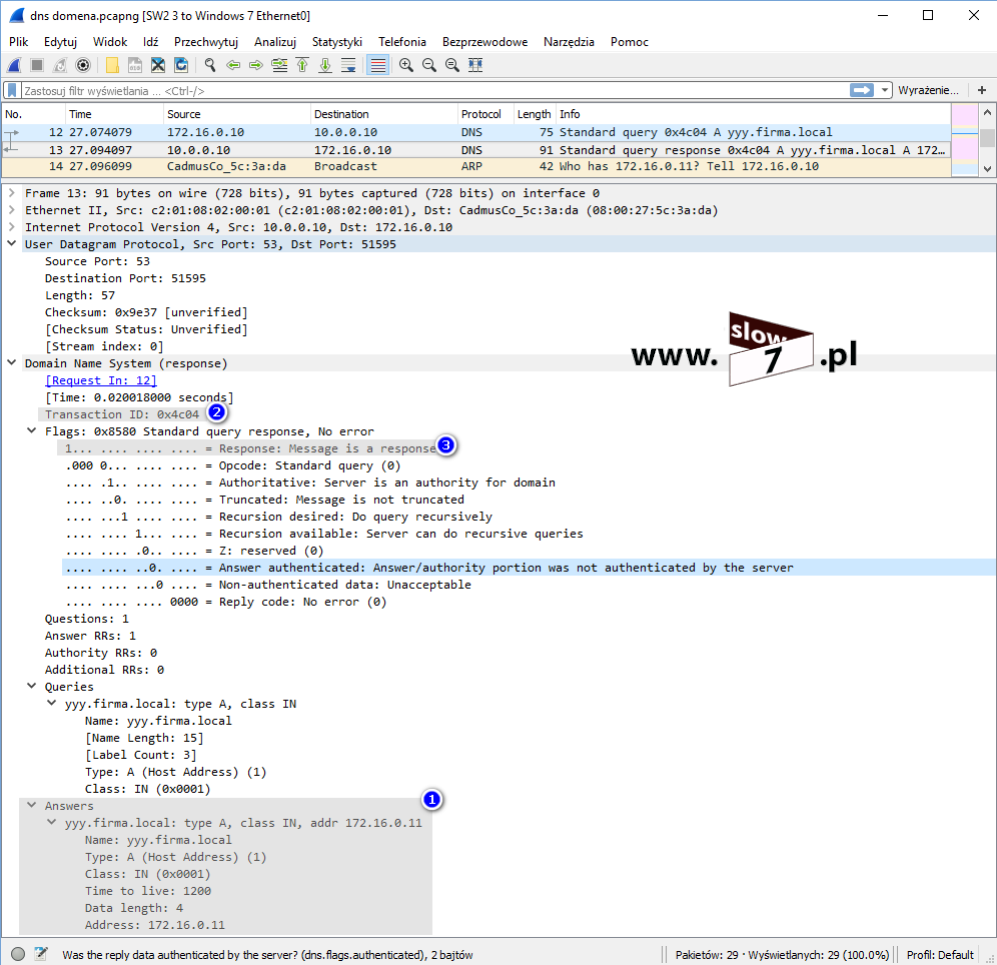
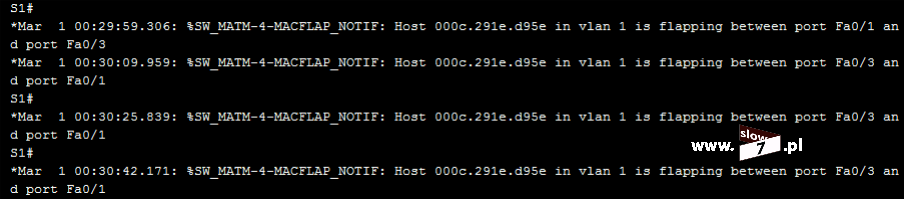
Poniżej na wskutek próby nawiązania połączenia z hostem 10.0.3.10 został wygenerowany komunikat o zaistniałym zdarzeniu – nastąpiło dopasowanie informacji zawartych w nagłówku pakietu z warunkiem listy ACL, który podlega logowaniu.

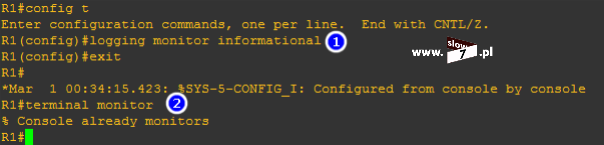
Jeśli sprawdzamy poprawność działania zdefiniowanych list ACL warto posłużyć się komendą: show log Wydanie polecenie uwidoczni nam historię zdarzeń.
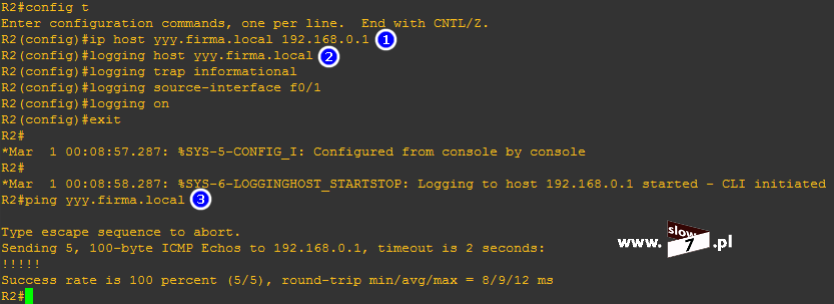
Lecz zanim zaczniemy używać wspomnianego wyżej polecenia należy w konfiguracji globalnej urządzenia wydać polecenie: logging console informational Komenda ta spowoduje zapisanie informacji o zdarzeniu jakim jest wystąpienie dopasowania – brak wydania tego polecenia uniemożliwi sprawdzenie historii zdarzeń (informacja o zdarzeniu pojawi się w wierszu poleceń konsoli lecz fakt jej zaistnienia nie zostanie zapisany). Polecenie te związane jest z konfiguracją zapisu zdarzeń i dokładny opis sposobu działania komendy trochę wybiega poza tematykę tego wpisu (logowanie zdarzeń będzie tematem kolejnego artykułu i w nim użycie tego polecenia opiszę szerzej).

W przypadku spodziewania się dużej ilości wpisów warto również pomyśleć o tym by nie zabrakło miejsca na ich zapisanie dlatego dobrze jest zwiększyć rozmiar bufora odpowiedzialnego za zapisywanie tych danych. Ilość dostępnego miejsca na zapis logów zwiększymy za pomocą polecenia: logging buffered <rozmiar_bajty>

Po przeprowadzonej konfiguracji wydanie polecenia: show log spowoduje wypisanie zaistniałych zdarzeń wśród, których znajdziemy informację o zdarzeniach związanych z logowanymi warunkami list ACL.

Aby wykasować liczniki, korzystamy z polecenia: clear ip access-list counter <numer_listy_ACL> a w przypadku listy nazywanej: clear ip access-list counter <nazwa_listy_ACL>
Jest jeszcze jeden parametr którego użycie zapewni nam dostarczenie większej ilości informacji na temat zaistniałych zdarzeń dotyczących list ACL. Aby uzyskane dane były bardziej szczegółowe zamiast flagi: log możemy użyć opcję: log-input
Poniżej przykład listy ACL, która zabrania tak jak poprzednio na komunikację pomiędzy hostem 10.0.1.10 a siecią 10.0.3.0 – w przykładzie tym użyto rozszerzoną listę ACL, która nie została jeszcze omówiona. W ćwiczeniu tym przede wszystkim chodzi o pokazanie możliwości uzyskania informacji o sposobie działania list ACL tak więc wybacz Czytelniku iż wybiegam trochę na przód. Spowodowane to jest faktem iż opcja: log-input została zarezerwowana tylko dla list rozszerzonych. Nie martw się gdy poniższe zapisy będą dla Ciebie niezrozumiałe (na razie) gdyż na tą chwilę nie jest to tematem naszych rozważań (do list rozszerzonych przejdę już za chwilę). Do przykładu tego zachęcam wrócić po dalszej lekturze wpisu.

Po zdefiniowaniu listy ACL, lista oczywiście zostaje przypisana do interfejsu i zostaje ustalony kierunek jej działania (rozważania na tematy interfejsu i routera na którym została utworzona lista ACL zostaw na później - w tym momencie nie ma to znaczenia).

W momencie gdy warunek listy ACL będzie miał zastosowanie zostaniemy o tym poinformowani. Poniżej przykład uzyskania informacji o nie udzieleniu dostępu do sieci 10.0.3.0/24 – host, który inicjował połączenie to komputer o adresie IP 10.0.1.10 Porównując dane uzyskane dzięki zastosowaniu opcji: log-input z tymi otrzymanymi dzięki opcji: log na pierwszy rzut oka widać, iż są to informacje bardziej szczegółowe (w logach m.in. znajdziemy dane o adresie MAC a w przypadku użycia protokołów TCP bądź UDP również będzie zawarta informacja o portach).

Efekty działania listy ACL możemy również sprawdzić za pomocą procesu debugowania. Aby uruchomić proces dotyczący danej listy ACL należy wydać polecenie: debug ip packet <numer_listy_ACL> detail

Po uruchomieniu procesu możemy obserwować efekt podejmowanych decyzji jakie podejmuje router względem otrzymanych pakietów a odnoszących się do wywołanej listy ACL.
Poniżej przykład w którym host o adresie 10.0.1.10 przeprowadza test względem hosta 10.0.3.10. Ponieważ komunikacja dzięki zastosowaniu listy ACL dla hosta 10.0.1.10 została zablokowana tak więc router odsyła informację ICMP typ 3 - Destination Unreachable

Podczas tworzenia wpisów list ACL na pewno nie raz przydarzy nam się sytuacja w której popełnimy błąd – Jak sobie z tym problemem poradzić? Proponuję trzy rozwiązania. Pierwsze z nich opiera się na bezpośredniej edycji listy ACL drugie na skopiowaniu ustawień listy ACL, poprawieniu błędów, wykasowaniu błędnie skonfigurowanej listy ACL i wprowadzeniu nowych ustawień, trzecie zaś na użyciu narzędzia CCP(Cisco Configuration Professional)
Prześledźmy zatem zaproponowane rozwiązania na tym przykładzie, rozpoczniemy od edycji listy ACL.
Poniżej na zrzucie została przedstawiona używana przez nas lista ACL 7, lecz jak można zauważyć w liście tej został błędnie skonfigurowany adres IP hosta – zamiast adresu 10.0.10.10 powinien być 10.0.1.10

Aby móc poprawić błędny wpis należy przejść do trybu konfiguracji globalnej urządzenia i wydać polecenie: ip access-list {standard | extended} <numer_listy> - punkt 1 (w naszym przypadku mamy do czynienia z standardową listą ACL tak więc używamy argumentu: standard w przypadku listy rozszerzonej należy użyć flagi: extended).
Po zatwierdzeniu komendy przejdziemy do trybu konfiguracji listy ACL (zapis: config-std-nacl). Błędny wpis adresu IP został powiązany z numerem sekwencyjnym listy, wartość tego numeru wynosi 10. Aby wpis usunąć należy wydać polecenie: no <numer_sekwencyjny> - punkt 2.

Błędny wpis został usunięty, fakt wykonania operacji możemy sprawdzić wyświetlając ustawienia listy ACL.

Po usunięciu wpisu należy wprowadzić nowy. Polecenie nakazujące dodanie nowego wpisu oczywiście wydajemy w trybie konfiguracji danej listy ACL. A wpis dodamy za pomocą polecenia: <numer_sekwencyjny> <parametry_listy_ACL> w naszym przypadku komenda przyjęła postać: 10 deny host 10.0.1.10

Po wprowadzeniu zmian, sprawdzamy fakt ich wykonania. Jak widać poniżej lista ACL została poprawiona.
Domyślne po zdefiniowaniu warunku listy ACL trafia on na koniec listy. Bez numerów sekwencyjnych, jedyną opcją dodania wpisu pomiędzy dwa już istniejące, było skasowanie ACL i zdefiniowanie jej od nowa. Sytuacja ta powtarzała się również w przypadku gdy chcieliśmy wykasować warunek.
Numery sekwencyjne dają nam możliwość edycji interesującego nas wpisu a także na dodanie nowego w dowolne miejsce listy ACL. Możliwe jest to dzięki przyjętemu numerowaniu kolejnych wpisów tworzących daną listę ACL. Domyślnie, numery sekwencyjne rozpoczynają się od wartości 10 a kolejny wpis powiększa tą wartość o 10.
Do bezpośredniej edycji listy ACL możemy podejść trochę inaczej a mianowicie dodać poprawny wpis. W naszym przypadku użyty numer sekwencyjny musi być niższy od następnego czyli od 20. Dodanie wpisu o numerze sekwencyjnym wyższym niż 20 spowoduje dopisanie warunku powyżej tego numeru a co za tym idzie wpis ten nigdy nie będzie miał zastosowania gdyż znajdzie się on za wpisem zezwalającym na ruch sieciowy wszystkim (20 permit any). Pamiętaj, że listy ACL są przetwarzane od góry do pierwszego dopasowania. W scenariuszu padło na wartość 15 (15 jest mniejsze od 20 tak więc nowo dodany wpis znajdzie się przed warunkiem z numerem sekwencyjnym równym 20) – punkt 1. Po wprowadzeniu nowego warunku pamiętamy o wykasowaniu tego błędnie zdefiniowanego – punkt 2. Po całości wykonanych zmian ostatnią czynnością jest ich sprawdzenie – punkt 3 – Wszystko się zgadza (dla przypomnienia dodanie do polecenia parametru: do nakazuje wykonanie polecenia dostępnego w trybie konfiguracji poziomu wyżej – zauważ, że polecenie zostało wydane w trybie konfiguracji globalnej zaś komenda: show access-list powinna zostać wydana w trybie uprzywilejowanym).

Przechodzimy zatem do drugiego ze sposobów.
W pierwszej kolejności rozpoczynamy od wyświetlenia ustawień listy ACL. Wpisy budujące listę ACL możemy wyświetlić przy wykorzystaniu polecenia zaprezentowanego na zrzucie poniżej (pełna składnia polecenia: show running-config | include access-list 7 – wyświetl ustawienia listy ACL 7 zawarte w konfiguracji bieżącej urządzenia – parametr: include odpowiada za wyświetlenie tylko tych wierszy zawierających zdefiniowaną po nim wartość).

Wyświetloną konfigurację po zaznaczeniu kopiujemy klawiszem Enter (do zestawienia sesji z routerem zostało użyte narzędzie PuTTY) a następnie wklejamy w dowolnym edytorze tekstowym i nanosimy niezbędne poprawki.

Po dokonaniu korekty ustawień i skopiowaniu ich do schowka po wciśnięciu PPM zawartość schowka zostaje wklejona do narzędzia PuTTY. Przy wklejaniu poleceń należy zwrócić uwagę by znajdować się w odpowiednim trybie konfiguracji routera (w przypadku list ACL jest to tryb konfiguracji globalnej). Przed skopiowaniem ustawień należy pamiętać o usunięciu błędnie zdefiniowanej listy ACL.

Taki sposób wprowadzania ustawień można wykorzystać nie tylko przy tworzeniu/edytowaniu list ACL ale również do konfiguracji wszystkich poleceń routera/przełącznika. Przypuśćmy, że mamy skonfigurowany router i dodajemy drugi, którego ustawienia nieznacznie się różnią od pierwszego. Możemy konfigurację oczywiście przeprowadzić ręcznie poprzez wprowadzenie wszystkich poleceń ale również poprzez skopiowanie całej konfiguracji bieżącej routera pierwszego, naniesieniu niezbędnych poprawek i wklejeniu ustawień do routera drugiego.
Ostatni sposób opiera się na użyciu narzędzia CCP. Narzędzie te umożliwia nam przeprowadzenie konfiguracji urządzeń sieciowych firmy CISCO z wykorzystaniem graficznego interfejsu użytkownika. Użycie aplikacji opiera się na przeglądarce Internet Explorer (najlepiej działa z tą przeglądarką) wraz z zainstalowanym oprogramowaniem Flash i Java (bez instalacji tych komponentów nie będzie można uruchomić CCP).
O ile jestem zwolennikiem jednak korzystania z CLI to o tyle w przypadku edycji bądź definicji nowych list ACL narzędzie CCP świetnie się sprawdza gdyż w prosty i szybki sposób umożliwia nam na wykonanie zadań związanych z listami ACL (przebiega to po prostu bardziej sprawnie, szczególnie gdy musimy zarządzać złożonymi listami ACL bądź ich dużym zbiorem).
Po uruchomieniu programu i połączeniu się z routerem (jak skonfigurować router aby współpracował z CCP opisałem tu: Dostęp zdalny oraz prawa użytkownika w urządzeniach CISCO). Przechodzimy do gałęzi: ACL/ACL Editor Po wybraniu jej z prawej strony ukaże się nam zbiór list ACL. Jak widać lista ACL 7 zawiera zdefiniowany przez nas na potrzeby ćwiczenia błąd. Aby rozpocząć edycję listy ACL należy ją zaznaczyć i wybrać przycisk: Edit

Po wybraniu opcji edytowania listy w nowo otwartym oknie Edit a Rule wybieramy wpis, który ma podlegać modyfikacji i ponownie wybieramy Edit (punkt 1).
W kolejnym oknie nanosimy niezbędne poprawki i zatwierdzamy je przyciskiem OK (dwa razy) – punkt 2.

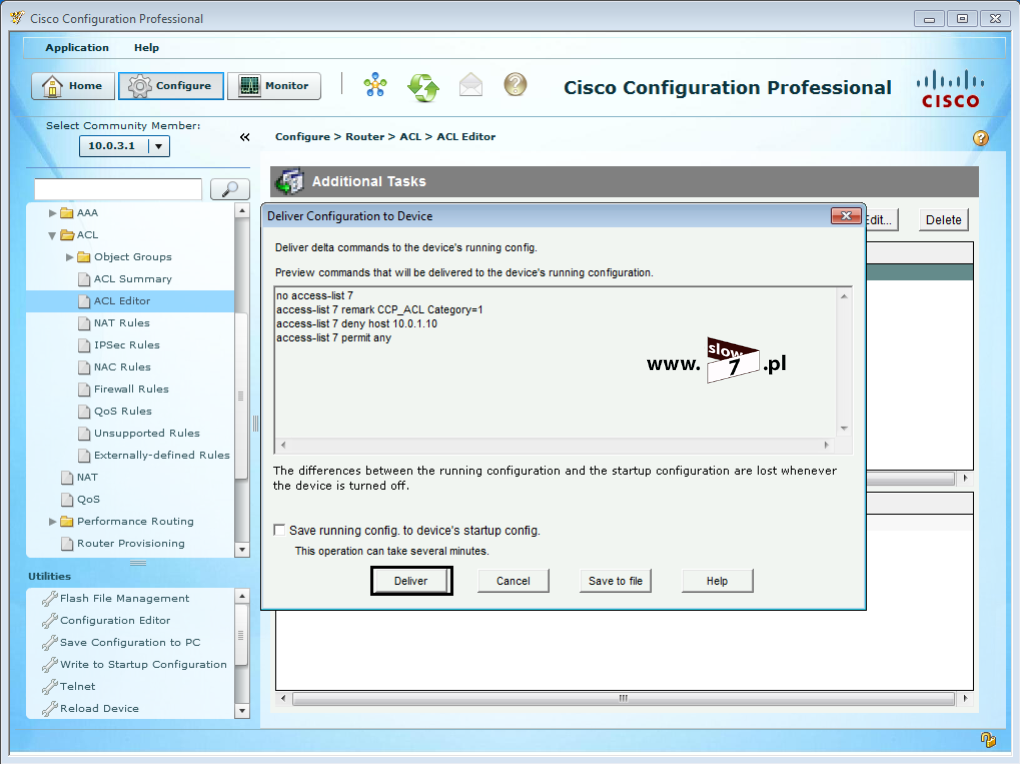
Po zatwierdzeniu zmian zostanie wyświetlone okno: Deliver Configuration to Device odpowiedzialne za wysłanie odpowiednich poleceń do konfigurowanego urządzenia. Na tym etapie możemy podejrzeć jakie polecenia będą na zdalnym urządzeniu wydane. Zaznaczenie „ptaszka” przy opcji Save running config. to device’s startup config. spowoduje automatyczne zapisanie ustawień bieżących urządzenia jako konfigurację startową. Aby zastosować zmiany w konfiguracji wybieramy Deliver
Odpowiednie ustawienia zostały wprowadzone do konfiguracji urządzenia. Stan ustawień listy ACL sprawdzimy wybierając ponownie daną listę ACL.

Myślę, że omówione sposoby edycji list ACL są wystarczające a tylko od Ciebie zależy, którą z nich użyjesz.
Pytanie na koniec tego zadania, jakie możemy sobie zadać brzmi – Czy zastosowana lista ACL pomimo spełnienia założeń ćwiczenia, ze względu na wydajność sieci jest zasadna?
Dociekliwy Czytelnik szybko dojdzie do wniosku, że przy użyciu tak skonfigurowanej standardowej listy ACL marnotrawione jest pasmo oraz użycie procesorów routerów. Spójrzmy jeszcze raz na naszą topologię z zaznaczoną drogą pakietów i spróbujmy uzasadnić powyższe stwierdzenie.

Jak widać stwierdzenie jest zasadne gdyż – pakiet opuszczający hosta WindowsXP_1 a podróżujący w kierunku komputera WindowsXP_3, wędruje przez całą sieć (jest przekazywany przez kolejne routery) by i tak na końcu swojej drogi zostać zablokowany przez skonfigurowaną listę ACL. Tu na tym przykładzie widać jak na dłoni iż stosowanie standardowych list ACL (przy założeniach tego ćwiczenia) jest mało efektywne.
Tak więc jak najbardziej na miejscu jest pytanie – Co z tym fantem możemy zrobić i czy jest jakiś bardziej efektywny sposób osiągnięcia naszego celu? Rozwiązaniem będzie zastosowanie rozszerzonej listy ACL.
Ogólna składnia definicji rozszerzonej listy ACL wygląda następująco: access-list <nr_listy> {permit | deny} <protokół> <definicja_punktu_źródłowego> <definicja_punktu_docelowego>
Rozszerzone listy ACL umożliwiają nam prowadzenie większego zakresu kontroli ponieważ nasz warunek możemy zbudować m.in. w oparciu o źródłowy i docelowy adres IP pakietów a dodatkowo pozwalają również na określenie protokołów i numerów portów co do których lista ACL będzie miała zastosowanie. Tak więc nasze definicje blokujące bądź przepuszczające ruch sieciowy są określane na podstawie adresów nadawcy i odbiorcy pakietu, typu protokołu oraz portu.
Zakres użytych parametrów definiujemy sami według potrzeby i uznania oznacza to, że lista ACL może zawierać instrukcje odwołujące się tylko do adresów IP (wraz z użytym protokołem) a gdy jest potrzeba zawężenia listy możemy dodać dodatkowe parametry odwołujące się do np. numerów portów. Pojedyncza rozszerzona lista ACL może konfigurować wiele instrukcji.
Numery list rozszerzonych ACL są zawarte w zakresie od 100 do 199 a także od 2000 do 2699 (dla protokołu IP).
Prześledźmy zatem sposób konfiguracji takiej listy.
Tak jak w przypadku listy standardowej rozpoczynamy od wydania w trybie konfiguracji globalnej polecenia: access-list po którym to określamy numer listy a także warunek przepuszczający bądź odrzucający pakiet. Nasza lista może więc przyjąć postać:
R1(config)#access-list 111 deny ...
bądź
R1(config)#access-list 111 permit ...
W kolejnym kroku ustalamy rodzaj protokołu, dla którego będzie realizowane dopasowanie:
R1(config)#access-list 111 deny <protokół> ...
R1(config)#access-list 111 permit <protokół> ...
Protokół określamy poprzez definicję jego nazwy lub poprzez podanie numeru. Poniżej na rysunku zostały przedstawione nazwy najczęściej używanych protokołów.

Lista dostępnych numerów wraz z przypisanym do numeru protokołem została zamieszczona w tabeli poniżej (źródło: http://www.iana.org/assignments/protocol-numbers/protocol-numbers.xhtml).
| Decimal |
Keyword |
Protocol |
| 0 |
HOPOPT |
IPv6 Hop-by-Hop Option |
| 1 |
ICMP |
Internet Control Message |
| 2 |
IGMP |
Internet Group Management |
| 3 |
GGP |
Gateway-to-Gateway |
| 4 |
IPv4 |
IPv4 encapsulation |
| 5 |
ST |
Stream |
| 6 |
TCP |
Transmission Control |
| 7 |
CBT |
CBT |
| 8 |
EGP |
Exterior Gateway Protocol |
| 9 |
IGP |
any private interior gateway (used by Cisco for their IGRP) |
| 10 |
BBN-RCC-MON |
BBN RCC Monitoring |
| 11 |
NVP-II |
Network Voice Protocol |
| 12 |
PUP |
PUP |
| 13 |
ARGUS (deprecated) |
ARGUS |
| 14 |
EMCON |
EMCON |
| 15 |
XNET |
Cross Net Debugger |
| 16 |
CHAOS |
Chaos |
| 17 |
UDP |
User Datagram |
| 18 |
MUX |
Multiplexing |
| 19 |
DCN-MEAS |
DCN Measurement Subsystems |
| 20 |
HMP |
Host Monitoring |
| 21 |
PRM |
Packet Radio Measurement |
| 22 |
XNS-IDP |
XEROX NS IDP |
| 23 |
TRUNK-1 |
Trunk-1 |
| 24 |
TRUNK-2 |
Trunk-2 |
| 25 |
LEAF-1 |
Leaf-1 |
| 26 |
LEAF-2 |
Leaf-2 |
| 27 |
RDP |
Reliable Data Protocol |
| 28 |
IRTP |
Internet Reliable Transaction |
| 29 |
ISO-TP4 |
ISO Transport Protocol Class 4 |
| 30 |
NETBLT |
Bulk Data Transfer Protocol |
| 31 |
MFE-NSP |
MFE Network Services Protocol |
| 32 |
MERIT-INP |
MERIT Internodal Protocol |
| 33 |
DCCP |
Datagram Congestion Control Protocol |
| 34 |
3PC |
Third Party Connect Protocol |
| 35 |
IDPR |
Inter-Domain Policy Routing Protocol |
| 36 |
XTP |
XTP |
| 37 |
DDP |
Datagram Delivery Protocol |
| 38 |
IDPR-CMTP |
IDPR Control Message Transport Proto |
| 39 |
TP++ |
TP++ Transport Protocol |
| 40 |
IL |
IL Transport Protocol |
| 41 |
IPv6 |
IPv6 encapsulation |
| 42 |
SDRP |
Source Demand Routing Protocol |
| 43 |
IPv6-Route |
Routing Header for IPv6 |
| 44 |
IPv6-Frag |
Fragment Header for IPv6 |
| 45 |
IDRP |
Inter-Domain Routing Protocol |
| 46 |
RSVP |
Reservation Protocol |
| 47 |
GRE |
Generic Routing Encapsulation |
| 48 |
DSR |
Dynamic Source Routing Protocol |
| 49 |
BNA |
BNA |
| 50 |
ESP |
Encap Security Payload |
| 51 |
AH |
Authentication Header |
| 52 |
I-NLSP |
Integrated Net Layer Security TUBA |
| 53 |
SWIPE (deprecated) |
IP with Encryption |
| 54 |
NARP |
NBMA Address Resolution Protocol |
| 55 |
MOBILE |
IP Mobility |
| 56 |
TLSP |
Transport Layer Security Protocol using Kryptonet key management |
| 57 |
SKIP |
SKIP |
| 58 |
IPv6-ICMP |
ICMP for IPv6 |
| 59 |
IPv6-NoNxt |
No Next Header for IPv6 |
| 60 |
IPv6-Opts |
Destination Options for IPv6 |
| 61 |
|
any host internal protocol |
| 62 |
CFTP |
CFTP |
| 63 |
|
any local network |
| 64 |
SAT-EXPAK |
SATNET and Backroom EXPAK |
| 65 |
KRYPTOLAN |
Kryptolan |
| 66 |
RVD |
MIT Remote Virtual Disk Protocol |
| 67 |
IPPC |
Internet Pluribus Packet Core |
| 68 |
|
any distributed file system |
| 69 |
SAT-MON |
SATNET Monitoring |
| 70 |
VISA |
VISA Protocol |
| 71 |
IPCV |
Internet Packet Core Utility |
| 72 |
CPNX |
Computer Protocol Network Executive |
| 73 |
CPHB |
Computer Protocol Heart Beat |
| 74 |
WSN |
Wang Span Network |
| 75 |
PVP |
Packet Video Protocol |
| 76 |
BR-SAT-MON |
Backroom SATNET Monitoring |
| 77 |
SUN-ND |
SUN ND PROTOCOL-Temporary |
| 78 |
WB-MON |
WIDEBAND Monitoring |
| 79 |
WB-EXPAK |
WIDEBAND EXPAK |
| 80 |
ISO-IP |
ISO Internet Protocol |
| 81 |
VMTP |
VMTP |
| 82 |
SECURE-VMTP |
SECURE-VMTP |
| 83 |
VINES |
VINES |
| 84 |
TTP |
Transaction Transport Protocol |
| 84 |
IPTM |
Internet Protocol Traffic Manager |
| 85 |
NSFNET-IGP |
NSFNET-IGP |
| 86 |
DGP |
Dissimilar Gateway Protocol |
| 87 |
TCF |
TCF |
| 88 |
EIGRP |
EIGRP |
| 89 |
OSPFIGP |
OSPFIGP |
| 90 |
Sprite-RPC |
Sprite RPC Protocol |
| 91 |
LARP |
Locus Address Resolution Protocol |
| 92 |
MTP |
Multicast Transport Protocol |
| 93 |
AX.25 |
AX.25 Frames |
| 94 |
IPIP |
IP-within-IP Encapsulation Protocol |
| 95 |
MICP (deprecated) |
Mobile Internetworking Control Pro. |
| 96 |
SCC-SP |
Semaphore Communications Sec. Pro. |
| 97 |
ETHERIP |
Ethernet-within-IP Encapsulation |
| 98 |
ENCAP |
Encapsulation Header |
| 99 |
|
any private encryption scheme |
| 100 |
GMTP |
GMTP |
| 101 |
IFMP |
Ipsilon Flow Management Protocol |
| 102 |
PNNI |
PNNI over IP |
| 103 |
PIM |
Protocol Independent Multicast |
| 104 |
ARIS |
ARIS |
| 105 |
SCPS |
SCPS |
| 106 |
QNX |
QNX |
| 107 |
A/N |
Active Networks |
| 108 |
IPComp |
IP Payload Compression Protocol |
| 109 |
SNP |
Sitara Networks Protocol |
| 110 |
Compaq-Peer |
Compaq Peer Protocol |
| 111 |
IPX-in-IP |
IPX in IP |
| 112 |
VRRP |
Virtual Router Redundancy Protocol |
| 113 |
PGM |
PGM Reliable Transport Protocol |
| 114 |
|
any 0-hop protocol |
| 115 |
L2TP |
Layer Two Tunneling Protocol |
| 116 |
DDX |
D-II Data Exchange (DDX) |
| 117 |
IATP |
Interactive Agent Transfer Protocol |
| 118 |
STP |
Schedule Transfer Protocol |
| 119 |
SRP |
SpectraLink Radio Protocol |
| 120 |
UTI |
UTI |
| 121 |
SMP |
Simple Message Protocol |
| 122 |
SM (deprecated) |
Simple Multicast Protocol |
| 123 |
PTP |
Performance Transparency Protocol |
| 124 |
ISIS over IPv4 |
|
| 125 |
FIRE |
|
| 126 |
CRTP |
Combat Radio Transport Protocol |
| 127 |
CRUDP |
Combat Radio User Datagram |
| 128 |
SSCOPMCE |
|
| 129 |
IPLT |
|
| 130 |
SPS |
Secure Packet Shield |
| 131 |
PIPE |
Private IP Encapsulation within IP |
| 132 |
SCTP |
Stream Control Transmission Protocol |
| 133 |
FC |
Fibre Channel |
| 134 |
RSVP-E2E-IGNORE |
|
| 135 |
Mobility Header |
|
| 136 |
UDPLite |
|
| 137 |
MPLS-in-IP |
|
| 138 |
manet |
MANET Protocols |
| 139 |
HIP |
Host Identity Protocol |
| 140 |
Shim6 |
Shim6 Protocol |
| 141 |
WESP |
Wrapped Encapsulating Security Payload |
| 142 |
ROHC |
Robust Header Compression |
| 143-252 |
|
Unassigned |
| 253 |
|
Use for experimentation and testing |
| 254 |
|
Use for experimentation and testing
|
| 255 |
Reserved |
|
Następnie podawany jest adres nadawcy z maską blankietową, a po nim — adres odbiorcy (również z maską blankietową). Cóż takiego jest ta maska blankietowa? W tym momencie wybacz Czytelniku jeszcze tego tematu nie rozwinę ale powrócimy do niego dosłownie za chwilę – opisu szukaj kilka wierszy poniżej.
R1(config)#access-list 111 deny <protokół> <adres_nadawcy> <adres_odbiorcy>
R1(config)#access-list 111 permit <protokół> <adres_nadawcy> <adres_odbiorcy>
Uzbrojeni w tą wiedzę spróbujmy zatem zdefiniować rozszerzoną listę ACL, która zablokuje nam ruch sieciowy pochodzący od hosta 10.0.1.10 a wysyłany w kierunku hosta 10.0.3.10
Lista ACL przyjmie zatem postać:

Punkt 1 – numer listy został określony jako 111 czyli mamy do czynienia z listą rozszerzoną, chcemy zablokować ruch sieciowy a więc musimy użyć parametru: deny, blokowanym protokołem jest protokół IP, adres nadawcy został określony poprzez definicję: host 10.0.1.10 gdyż to pakiety wysłane od tego hosta mają być blokowane, aby zaś host mógł nawiązać połączenie z innymi komputerami wewnątrz sieci 10.0.3.0/24 oprócz hosta 10.0.3.10 poprzez definicję: host 10.0.3.10 został określony adres docelowy.
Punkt 2 – instrukcja zezwalająca (parametr: permit) na ruch sieciowy pozostałym hostom (parametr: any any – czytaj z dowolnego adresu źródłowego do dowolnego adresu docelowego). Gdyby tej instrukcji zabrakło inne komputery będące przypisane do sieci 10.0.1.0/24 nie mogłyby nawiązać połączenia gdyż zadział by domyślny warunek: deny any
Lista ACL rozszerzona została utworzona, czas ją przypisać do interfejsu routera i tu rodzi się kolejne pytanie – Który router i interfejs wybrać? W przypadku list rozszerzonych zasada ich umiejscowienia brzmi następująco – Listy ACL rozszerzone umieszczamy najbliżej źródła. Mamy tu do czynienia z sytuacją odwrotną niż w przypadku list ACL standardowych. Zasadę tą ilustruje rysunek poniżej – blokowany pakiet nie musi przejść całej drogi do celu by i tak ostatecznie zostać zablokowanym (sytuacja występuje w przypadku list ACL standardowych) lecz jest odrzucany przy pierwszej nadarzającej się okazji.

Tak więc naszą listę ACL należy umieścić najbliżej źródła czyli jest to interfejs f0/0 routera R1. Pakiet trafia do routera tak więc kierunek działania listy musi być ustalony na: in Przypisanie rozszerzonej listy ACL następuje w ten sam sposób jak listy standardowej.

Rozszerzona lista ACL została skonfigurowana. Czas by sprawdzić efekt przeprowadzonej konfiguracji. Pierwszy test zostanie przeprowadzony z hosta 10.0.1.10 – test zakończony powodzeniem, ruch sieciowy został zablokowany.

Test drugi – tym razem pakiet ping zostanie wysłany z hosta 10.0.1.20. Jak widać poniżej próba komunikacji zakończyła się sukcesem. Lista ACL działa poprawnie.

Informacje o zdefiniowanej, rozszerzonej liście ACL uzyskamy dzięki poleceniom:
1 - show access-lists,
2 - show running-config,
3 - show ip interface <interfejs>

Zadanie pierwsze wraz z informacjami dodatkowymi uważam za zakończone, idziemy dalej.
Przykład drugi polega na zablokowaniu ruchu całej sieci 10.0.1.0/24 do sieci 10.0.3.0/24. Zadanie te wykonamy przy pomocy listy ACL standardowej jak i rozszerzonej.
Rozpoczynamy od użycia listy ACL standardowej.
Teoretycznie można by było do tego zadania wykorzystać listę ACL w której zdefiniowalibyśmy wiele warunków z których każdy miałby za zadanie zablokować ruch sieciowy pochodzący od jednego z hosta. W sieci 10.0.1.0/24 do wykorzystania jest 254 unikatowych adresów IP, które mogą zostać przypisane hostom (adresy od 10.0.1.1 do 10.0.1.254 - istnieją jeszcze dwa adresy IP ale jeden z nich 10.0.0.0 jest adresem sieci natomiast 10.0.0.255 obsługuje broadcast). Nasza lista ACL musiałaby by więc zawierać aż 254 wpisów, których zadaniem byłoby zablokowanie całego ruchu pochodzącego od strony sieci 10.0.1.0/24 W przypadku standardowej listy ACL miałaby ona postać:
deny host 10.0.1.1
deny host 10.0.1.2
deny host 10.0.1.3
.
.
.
deny host 10.0.1.254
Jak można wywnioskować lista zbudowana w ten sposób jest nader skomplikowana a przy jej tworzeniu łatwo o błąd a dodatkowo im więcej warunków zawiera lista ACL tym bardziej obciążamy router. Tak więc musi istnieć jakiś inny sposób, który pozwoli nam na definicję listy i wykonanie zadania. Oczywiście i takowy istnieje. Definicja list ACL tego typu sprowadza się do wykorzystania tzw. wildcard mask (w literaturze maska ta definiowana jest jako maska wieloznaczna, maska odwrócona bądź maska blankietowa zaś potocznie administratorzy często określają ją jako „dziką” maskę).
W masce standardowej (masce podsieci) bit 1 wymusza dopasowanie zaś bit 0 oznacza brak dopasowania w przypadku wildcard mask sytuacja zaś ma się odwrotnie:
bit 0 wildcard mask - wykonaj dopasowanie,
bit 1 wildcard mask - zignoruj.
Więc zadajmy pytanie – Jakiej więc wartości wildcard mask użyć? W naszym przykładzie mamy sytuację prostą wystarczy wykonać odejmowanie: od wartości 255.255.255.255 odejmujemy maskę podsieci (w naszym przypadku maska podsieci przyjęła wartość 255.255.255.0 – CIDR /24).
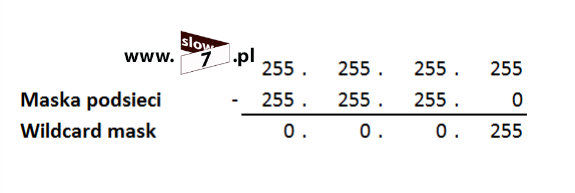
Po wykonaniu działania wartość maski odwróconej przyjmuje wartość: 0.0.0.255
Oczywiście analogicznie postępujemy w przypadku innych sieci np. dla sieci 255.255.255.252 – CIDR /30 (takie podsieci mamy pomiędzy routerami) wartość wildcard mask wyniesie: 0.0.0.3

Wracając do naszego przykładu aby zabronić na ruch sieciowy między siecią 10.0.1.0/24 a 10.0.3.0/24 przy wykorzystaniu listy ACL standardowej należy użyć warunku: deny 10.0.1.0 0.0.0.255 – punkt 1
Po określeniu pierwszego wpisu został zdefiniowany kolejny, który pozwala na ruch sieciowy pochodzący od innej sieci niż: 10.0.1.0/24 (punkt 2).
Ostatnią czynnością (punkt 3) jest sprawdzenie poprawności listy.

Po definicji warunków listy ACL nie można zapomnieć o powiązaniu jej z interfejsem routera, ponieważ jest to lista standardowa zostanie ona umieszczona najbliżej celu czyli na interfejsie f0/0 routera R3.

Zadanie wykonane, czas na testy. Test z wykorzystaniem hosta 10.0.1.10 kończy się sukcesem, ruch sieciowy jest zablokowany.
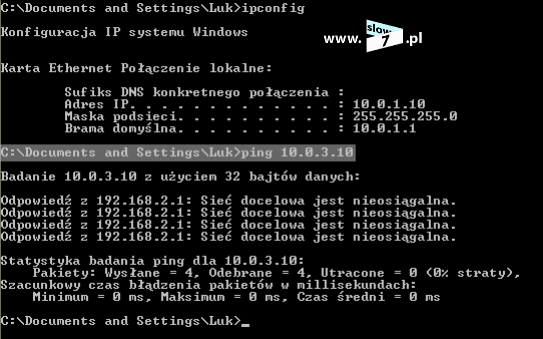
Również test przeprowadzony z hosta 10.0.1.20 kończy się sukcesem – pakiety ICMP nie docierają do celu.

Ostatnia próba zostanie przeprowadzona z wykorzystaniem komputera WindowsXP_2 i tu również pełny sukces - pakiety osiągają docelową sieć 10.0.3.10 (instrukcja: deny 10.0.1.0 0.0.0.255 dla sieci 10.0.2.0 nie ma zastosowania).

Sprawdzenie listy ACL uwidacznia ilość dokonanych dopasowań do zdefiniowanych warunków. Lista ACL działa poprawnie.

Jak już umiemy definiować rozszerzone listy ACL spróbujmy te same zadanie wykonać z ich wykorzystaniem.
Aby zabronić na ruch sieciowy od sieci 10.0.1.0/24 do sieci 10.0.3.0/24 należy utworzyć warunek, który ruch wychodzący z sieci 10.0.1.0/24 zablokuje. Rozpoczynamy od wydania polecenia access-list wraz z numerem należącym do zakresu przypisanego listom rozszerzonym. Pakiety mają zostać zablokowane tak więc niezbędne będzie dodanie flagi: deny. W kolejnym kroku definiujemy adres źródłowy - blokowane mają być wszystkie adresy IP wchodzące w skład sieci 10.0.1.0/24 tak więc niezbędne będzie dodanie do polecenia adresu sieci 10.0.1.0 wraz z maską blankietową 0.0.0.255 Gdy zostały określone źródłowe adresy IP czas zdefiniować adresy docelowe - blokujemy możliwość komunikacji z siecią docelową 10.0.3.0/24 tak więc definicja obejmująca ten zakres adresów IP przyjmie postać: 10.0.3.0 0.0.0.255 Składnia całego polecenia została pokazana na rysunku poniżej - punkt 1.
Po definicji listy ACL przypisujemy ją do interfejsu f0/0 routera R1. Dlaczego został wybrany ten interfejs i ten router? - to już Czytelniku mam nadzieję, że jest dla Ciebie jasne. Dla przypomnienia (nie zaszkodzi powtórzyć) - rozszerzoną listę ACL przypisujemy najbliżej źródła – punkt 2.
Po wydaniu wszystkich poleceń nie zaszkodzi sprawdzić ich poprawności - punkt 3.

Po określeniu pierwszego wpisu oczywiście musiał zostać zdefiniowany kolejny warunek (punkt 4), który zezwala na ruch sieciowy do innych sieci (w przypadku jego braku hosty z sieci 10.0.1.0/24 nie mogłyby się skomunikować np. z siecią 10.0.2.0/24).
Po dokonanej konfiguracji listy ACL przyszedł czas by sprawdzić efekt jej działania.
Pierwszy test został wykonany z hosta 10.0.1.10, drugi zaś z hosta 10.0.1.20 - oba zakończyły się sukcesem ruch sieciowy z sieci 10.0.1.0/24 został zablokowany.

Aby sprawdzić do końca działanie zdefiniowanej listy sprawdźmy jeszcze łączność z siecią 10.0.2.0/24 Test wykonany z hosta 10.0.1.20 zakończył się sukcesem tak więc nasza lista ACL działa poprawnie.

Zanim przejdziemy dalej i spróbujemy wykonać kolejne zadanie zatrzymajmy się jeszcze chwilkę przy wildcard mask.
Kilka wierszy powyżej napisałem iż bit 0 w wildcard mask oznacza dopasowanie zaś bit 1 zignoruj. Tę zasadę ilustruje rysunek poniżej.

Została przedstawiona przykładowa sieć 192.168.1.0 z zdefiniowaną maską odwrotną 0.0.0.255 (obszar maski zaznaczony na żółto) – czyli w ramach tych bitów adresu ma nastąpić dopasowanie (liczy się pierwsze 24 bity zajęte przez wartości 0) Jeśli 0 oznacza dopasowanie porównując adres sieci z adresem z pierwszego przykładu (adres IP 192.168.1.20) widzimy iż dopasowanie na wszystkich 24 bitach zostało zachowane. Brak dopasowania zachodzi dopiero na 28 bicie ale ponieważ 28 bit został odznaczony przez maskę jako 1 - brak dopasowania nie ma tu znaczenia. Co za tym idzie lista ACL i połączony z nią warunek dla tego adresu IP będzie miał zastosowanie.
W drugim przykładzie (adres 192.168.2.1) dopasowanie jest zachowane do 22 bitu adresu (bit 23 zawiera wartość 1 a powinien 0) oznacza to iż adres ten nie spełnia wymogów zdefiniowanego warunku (przypisana instrukcja do tego adresu IP nie będzie miała zastosowania).
W przykładzie trzecim mamy tą samą sytuację co w drugim z tą różnicą, że w tym przykładzie dopasowanie jest zachowane do bitu 12.
Przy definicji list ACL jak już pewnie zauważyłeś stosowaliśmy dwa specjalne parametry, mowa tu o fladze any oraz fladze host.
Opcja any wymusza zastosowanie maski 255.255.255.255. Użycie takie maski powoduje ignorowanie całego adresu IP bądź inaczej akceptację dowolnego.
Zasadę działania flagi any zobrazowano na rysunku poniżej.

Ponieważ maska odwrotna poprzez użycie any (co równe jest zapisowi 255.255.255.255) została zdefiniowana jako ciąg bitów przyjmujących wartość 1 to połączenie każdego z adresów IP powoduje jego akceptację. W przypadku połączenia z instrukcją: deny (warunek: deny any) tak zdefiniowana lista spowoduje zablokowanie całego ruchu sieciowego zaś w przypadku instrukcji: permit zezwolenie na ruch sieciowy z dowolnego adresu IP.
Opcja host zastępuje maskę 0.0.0.0. Maska ta powoduje sprawdzenie wszystkich bitów adresu i bity te muszą wykazać pełną zgodność. Zastosowanie parametru host spowoduje dopasowanie tylko jednego adresu IP.
I już tradycyjne rysunek poniżej.

Wildcard mask w której pojawia się flaga: host (co równe jest zapisowi: 0.0.0.0) oznacza wykonanie pełnego dopasowania gdyż wszystkie bity maski są zdefiniowane jako 0. Ten warunek zostanie tylko spełniony przez jeden pojedynczy adres IP - w przykładzie powyżej adres IP 192.168.1.1 został połączony z maską odwrotną 0.0.0.0 tak więc tylko taki adres spełni warunek dopasowania.
Pozostając jeszcze przez chwilę przy temacie maski odwrotnej zastanówmy się jaką by należało przyjąć maskę gdybyśmy chcieli wykonać zadanie, które polegałoby na zablokowaniu ruchu sieciowego od adresu IP 192.168.0.1 do 192.168.0.5? W ramach tego krótkiego ćwiczenia dla ułatwienia rozważań przyjmijmy, że mamy do czynienia z topologią przedstawioną na rysunku poniżej:

Zależy nam na tym aby hosty od adresu IP 192.168.0.1 do 192.168.0.5 nie mogły komunikować się z siecią 192.168.1.0/24 zaś hosty począwszy od adresu 192.168.0.6 już tak.
Pierwsze rozwiązanie tego problemu jakie każdemu powinno się nasunąć to zbudowanie listy ACL złożonej z 5 warunków w postaci: deny host 192.168.0.x gdzie x jest liczbą od 1 do 5 i jednego warunku: permit any
Oczywiście jest to wyjście z sytuacji i w tym ćwiczeniu jak najbardziej zdałoby egzamin - Ale czy postąpilibyśmy tak samo gdyby zakres blokowanych adresów IP wynosiłby powiedzmy adresy od 192.168.0.1 do 192.168.0.80? Już nie.
A więc co należy wykonać by podany zakres adresów IP zablokować? Pierwszą czynność jaką musimy przeprowadzić jest wyznaczenie adresu podsieci i maski do której blokowane hosty należą. Potrzebne nam dane odnajdziemy wykonując tzw. sumaryzację bądź podsumowanie (zagadnienie wykorzystywane również w routingu celem zmniejszenia rozmiarów tablic routingu).
Rozpiszmy nasze adresy IP binarnie (w gwoli ścisłości wystarczyłoby by rozpisać pierwszy i ostatni adres IP):

Następnie poruszamy się od lewej strony do prawej szukając dopasowania - miejsca w którym wszystkie adresy są ze sobą zgodne. Gdy dotrzemy do miejsca w którym zgodność nie jest zachowana, mówi się że znaleźliśmy granicę podsumowania. Jak widać nasza granica znajduje się przy 29 bicie gdyż porównując bit 30 dopasowanie nie jest już zachowane. Liczba 29 jest maską podsieci dla sieci sumarycznej. Maska /29 odpowiada adresowi 255.255.255.248. By odnaleźć adres sieci, przepisujemy bity do granicy podsumowania bez zmian natomiast resztę pozostałych bitów dopełniamy zerami. W naszym przykładzie 1100000.10101000.00000000.00000000, co odpowiada adresowi IP 192.168.0.0.
A więc adresem podsumowującym hosty jest podsieć: 192.168.0.0 255.255.255.248.
Mając maskę łatwo możemy przeliczyć ją na maskę odwrotną.
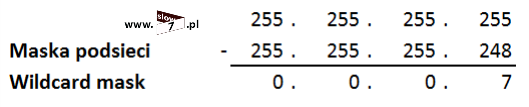
A więc przy budowie listy ACL należy użyć adresu 192.168.0.0 z wildcard mask o wartości 0.0.0.7
Zdobytą wiedzę wykorzystajmy w działaniu i zdefiniujmy standardową listę ACL.

Tak utworzoną listę oczywiście należy przypisać do interfejsu po stronie sieci 192.168.1.0/24

Lista ACL została skonfigurowana sprawdźmy zatem efekt naszych poczynań. W pierwszej kolejności host 192.168.0.1

Wszystko się zgadza host nie może skomunikować się z siecią 192.168.1.0/24
Czas na hosta 192.168.0.6

I w tym przypadku już tak kolorowo nie jest (a miało być tak pięknie). Host 192.168.0.6 również nie może skomunikować się z siecią 192.168.1.0/24 co jest sprzeczne z przyjętymi założeniami ćwiczenia. Cóż takiego się stało, że i temu hostowi została odebrana możliwość komunikacji?
Odpowiedź jest prosta. Host o adresie IP 192.168.0.6 tak jak hosty o adresach od 192.168.0.1 do 192.168.0.5 również należy do podsieci 192.168.0.0 255.255.255.248 (CIDR: /29) a co za tym idzie wykorzystując wyliczoną maskę wieloznaczną 0.0.0.7 również hostowi 192.168.0.6 zostanie odebrana możliwość komunikacji z żądaną siecią. Sytuacja ta dotyczy również hosta o adresie IP 192.168.0.7. Dopiero host z adresem IP 192.168.0.8 poprawnie nawiąże połączenie z siecią 192.168.1.0/24

Mam nadzieję, że zaistniały fakt i powstałe wątpliwości rozjaśni rysunek poniżej.

Jak można zauważyć dwa wspomniane adresy IP tj. 192.168.0.6 i 192.168.0.7 również spełniają warunek zgodności zachodzący do 29 bitu adresu (do granicy podsumowania) a dopiero adres IP 192.168.0.8 warunku dopasowania nie spełnia.
Tak więc co należy wykonać aby nasze ćwiczenie wykonać prawidłowo? Należy poprawić listę ACL poprzez utworzenie osobnych warunków dla dwóch problematycznych adresów IP.
Nasza lista ACL przyjmie postać:

1 - definicja zezwalająca na ruch sieciowy z hostów o adresach IP 192.168.0.6 oraz 192.168.0.7,
2 - definicja zabraniająca na ruch sieciowy hostom od 192.168.0.1 do 192.168.0.7 (wpis ten nie będzie miał zastosowania do hostów 192.168.0.6 oraz 192.168.0.7 gdyż wykluczenie tych adresów zostało zdefiniowane w punkcie 1),
3 - definicja zezwalająca na ruch sieciowy pozostałym hostom (od 192.168.0.8 do 192.168.0.255),
4 - przypisanie listy ACL do interfejsu.
Nie pozostaje nam nic innego jak dokonanie sprawdzenia.
I tak jak poprzednio zaczynamy od hosta 192.168.0.1

Test zakończony pomyślnie.
Czas na hosta 192.168.0.6

Łączność z siecią 192.168.1.0/24 jest możliwa. Test zakończony powodzeniem.
Nasza lista ACL działa poprawnie.

Na koniec rozważań dotyczących wildcard mask chcę cię Czytelniku pozostawić z pytaniem – Czy nasza lista ACL mogłaby zostać zdefiniowana tak jak na rysunku poniżej i czy gwarantuje to poprawność wykonania zadania? (jeśli Ci się nie uda odpowiedzieć na pytanie nie martw się – odpowiedź znajdziesz na końcu wpisu).

Przejdźmy zatem do kolejnego przykładu zastosowania list ACL. Funkcja pełniona przez listę ACL jest bardzo podobna do tej z ćwiczenia pierwszego z tą małą różnicą iż będziemy blokować ruch sieciowy pomiędzy hostem o adresie IP 10.0.1.10 (WindowsXP_1) a hostem 10.0.2.10 (WindowsXP_2). W przykładzie pierwszym do wykonania zadania użyliśmy m.in. standardowej listy ACL w tym przykładzie również takową listę użyjemy lecz tym razem będzie to tzw. standardowa lista ACL nazywana.
W przykładzie tym jak i następnym wracamy do naszej bazowej topologii więc by nie przewijać na sam początek artykułu jeszcze raz dla przypomnienia.

Nazwane listy ACL dla protokołu IP wprowadzono w wersji 11.2 systemu Cisco IOS.
Podczas pracy z listami ACL przekonasz się nie raz, że komentarz, który zawiera opis działania listy ACL znacznie ułatwi Ci zrozumienie sposobu działania danej listy. Jeśli konfigurowana lista ACL znajduje się w środowisku sieciowym w którym pełnisz rolę administratora już od dłuższego czasu zapoznanie się z takim opisem natychmiast przypomni Ci dlaczego została ona skonfigurowana. Jeśli zaś środowisko sieciowe w którym pracujesz jest dla Ciebie „dziewiczym” obszarem to będziesz wdzięczny poprzedniemu administratorowi, że zawarł wskazówki, które obszar ten pozwolą Ci poznać. Aby ułatwić sobie rozeznanie co do zasadności stosowania danych list ACL można je nazywać. Nazwa listy ACL w postaci: blokadaSieciBiuro da Ci więcej informacji o pełnionej przez listę ACL funkcji niż suchy opis w postaci jej numeru. Dlatego też oprócz stosowania standardowych list ACL numerowanych można posłużyć się listą nazywaną.
Po analizie ćwiczenia pierwszego już wiesz że listę standardową umieszczamy najbliżej celu. Zależy nam na blokadzie ruch pomiędzy hostem WindowsXP_1 a WindowsXP_2 tak by host o adresie IP 10.0.1.10 nie mógł skomunikować się z hostem 10.0.2.10 Najbliżej naszego celu (host WindowsXP_2) znajduje się interfejs f0/0 routera R2 tak więc to na tym interfejsie założymy listę ACL.
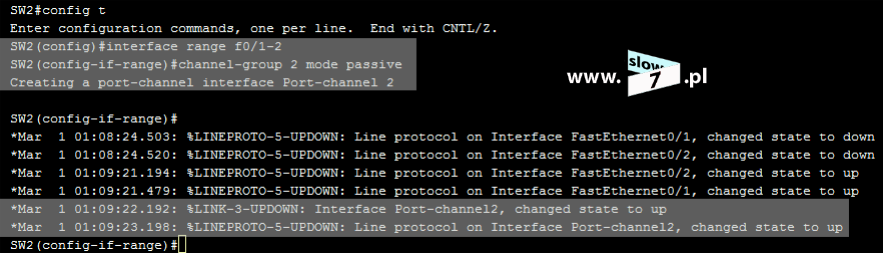
Aby zdefiniować nazywaną standardową listę ACL przechodzimy do trybu konfiguracji globalnej routera R2 i wydajemy polecenie: ip access-list standard <nazwa_listy> (w przypadku konfiguracji listy rozszerzonej zamiast parametru: standard używamy parametr: extended). A następnie w trybie konfiguracji listy ACL definiujemy jej warunki – punkt 1. Ostatnią czynność jaką musimy wykonać by lista ACL mogła zacząć działać jest jej powiązanie z danym interfejsem. W naszym scenariuszu lista ACL blokadaWinXP1 została przypisana do interfejsu f0/0. Kierunek działania listy oczywiście został określony jako: out

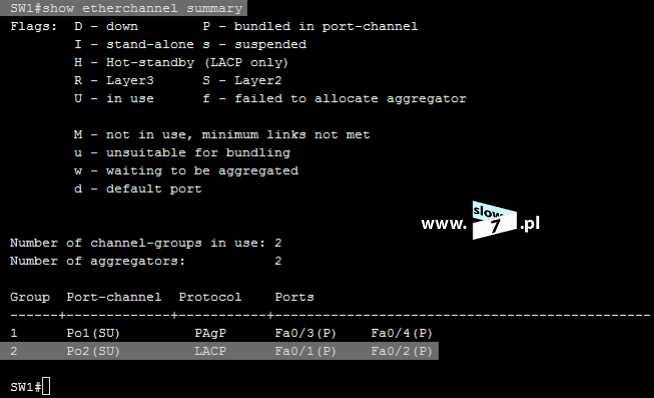
Sprawdźmy zatem działanie listy ACL.
Test ping przeprowadzony z hosta 10.0.1.10 kończy się sukcesem – brak jest połączenia z adresem 10.0.2.10

Zaś test komunikacji wykonany z hosta Windows7 również kończy się sukcesem – połączenie z hostem 10.0.2.10 zostaje nawiązane.

Zdefiniowana lista ACL została skonfigurowana prawidłowo.

W kolejnym ćwiczeniu zajmiemy się dalszą konfiguracją list ACL lecz tym razem filtrowanie ruchu skonfigurujemy w oparciu o numery portów.
Ćwiczenie polega na skonfigurowaniu listy ACL w ten sposób aby tylko host 10.0.1.20 (dla pozostałych adresów IP z podsieci 10.0.1.0/24 łączność ma być blokowana) mógł sesję SSH z routerem R3 nawiązać.
Aby wykonać to zadanie w definiowanych warunkach listy ACL musimy umieścić informację o numerze portu.
Numery portów mogą odnosić się do adresu źródłowego jak i docelowego.
Ponieważ kontrola dostępu będzie prowadzona w oparciu o numery portów należy użyć listy rozszerzonej a konfigurowanym protokołem jest TCP bądź UDP.
Prześledźmy taki o to warunek: access-list 180 permit tcp any any eq 80 Warunek ten zezwala na nawiązanie sesji z dowolnego adresu źródłowego do dowolnego adresu docelowego pod warunkiem iż nawiązywany ruch odnosi się do portu 80. W powyższej instrukcji zapis: eq 80 należy odczytać jako: równa się 80
Warunek definicji portu w powyższej liście ACL odnosi się oczywiście do adresu docelowego. Aby określić adres źródłowy nasza lista przyjęła by postać: access-list 180 permit tcp any eq 80 any Oczywiście dozwolona jest sytuacja w której zostaje zdefiniowany port w adresie źródłowym jak i docelowym. Warunek: access-list 180 permit tcp any eq 1566 any eq 80 pozwala na nawiązanie połączenia z dowolnym hostem na porcie 80 z dowolnego hosta pod warunkiem iż połączenie te inicjowane jest z wykorzystaniem portu 1566.
Nie jest tajemnicą iż port 80 odnosi się do ruchu WWW tak więc zamiast określać numer portu możemy użyć nazwę usługi. Zapis: access-list 180 permit tcp any any eq 80 będzie tożsamy z access-list 180 permit tcp any any eq www
Dostępnych jest wiele nazw usług, których zamiennie możemy użyć zamiast numeru portu, poniżej została przedstawiona lista tych najczęściej używanych (nazwy dotyczą protokołu TCP).

W przypadku protokołu UDP do dyspozycji mamy następujące zmienne:

Oprócz warunku równości portu do dyspozycji mamy jeszcze następujące zmienne:
gt - dopasowywanie tylko pakietów z większym numerem portu, warunek: access-list 180 permit tcp any any gt 80 oznacza możliwość nawiązania połączenia z hostem docelowym pod warunkiem iż połączenie nawiązywane jest z portem o numerze wyższym niż 80,
lt - dopasowywanie tylko pakietów z mniejszym numerem portu, warunek: access-list 180 permit tcp any any lt 80 oznacza możliwość nawiązania połączenia z hostem docelowym pod warunkiem iż połączenie nawiązywane jest z portem o numerze niższym niż 80,
neq - dopasowywanie tylko pakietów, których port nierówna się, warunek: access-list 180 permit tcp any any neq 80 oznacza możliwość nawiązania połączenia z hostem docelowym pod warunkiem iż połączenie nie jest nawiązywane z portem o numerze 80 (wszystkie numery portów są dozwolone tylko nie port 80),
range - dopasowywanie tylko pakietów, których numer znajduje się w zdefiniowanym zakresieportu z mniejszym numerem portu, warunek: access-list 180 permit tcp any any range 80 100 oznacza możliwość nawiązania połączenia z hostem docelowym pod warunkiem iż połączenie nawiązywane jest z portem o numerze, który mieści się w zakresie od 80 do 100 (do zakresu port 80 oraz 100 również się wlicza).
Wszystko już wiemy zatem przechodzimy do przykładu.
Usługa dostępu dla protokołu zdalnego z wykorzystaniem SSH została skonfigurowana na routerze R3 – jak wykonać taką konfigurację odsyłam do wpisu: Dostęp zdalny oraz prawa użytkownika w urządzeniach CISCO
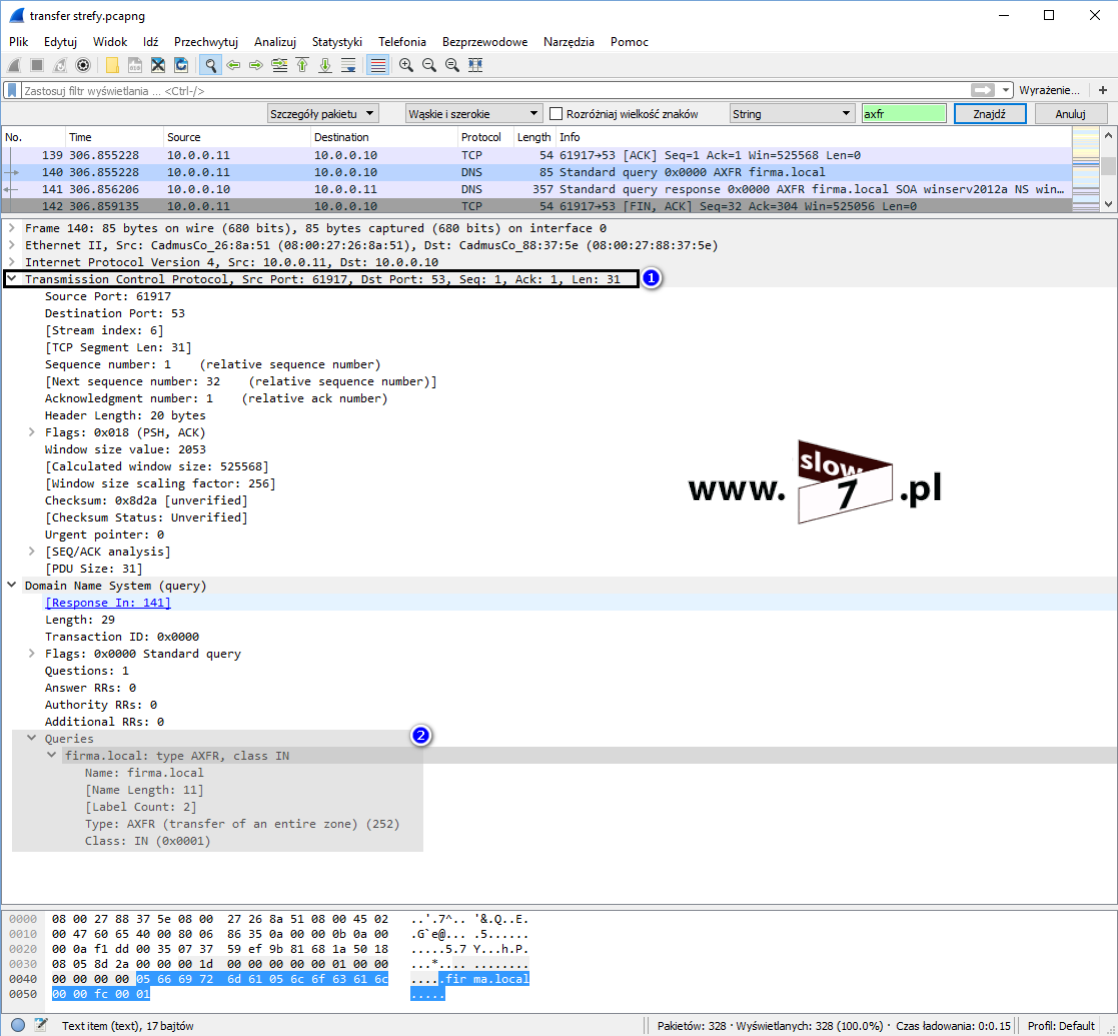
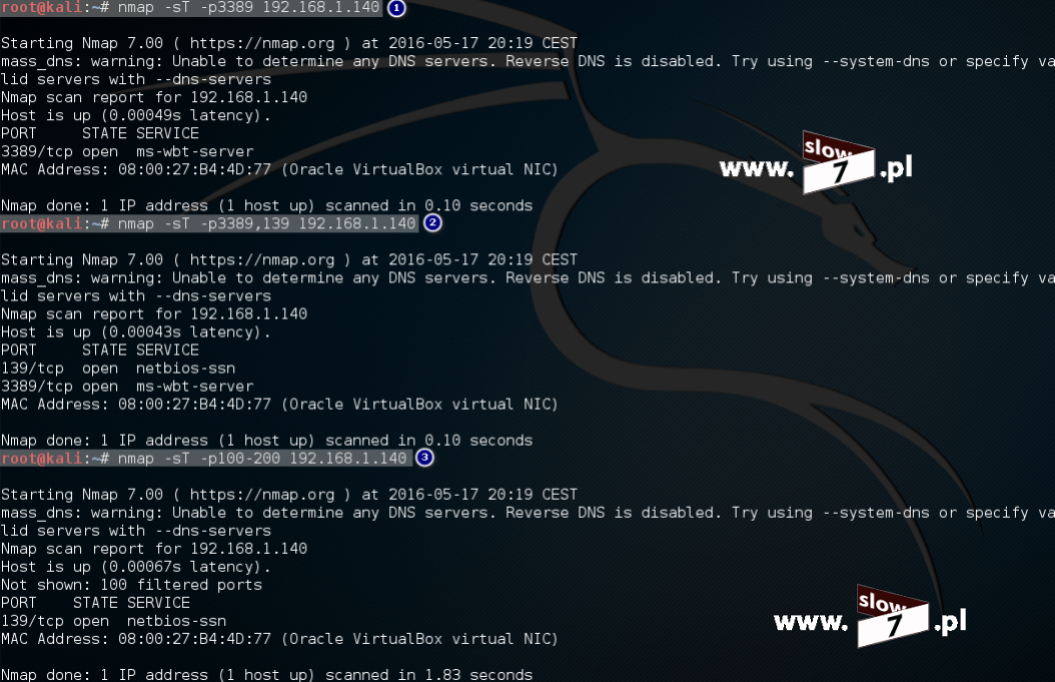
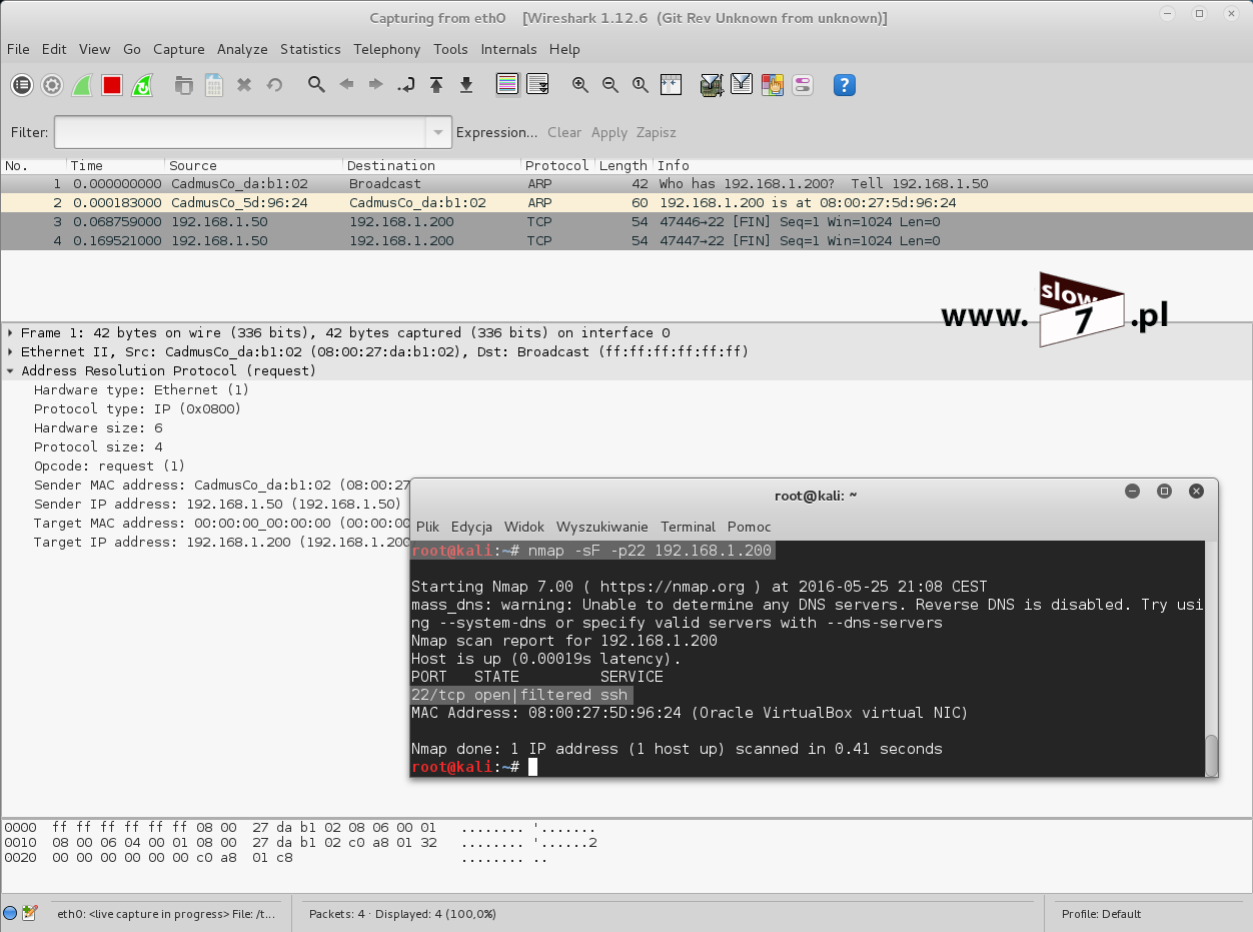
Wykonajmy sprawdzenie dostępności portu dla usługi SSH z wykorzystaniem narzędzia NMap. Użyta komenda wykona skanowanie TCP portu 22 (jeśli chcesz poznać bardziej zaawansowane techniki skanowania zapraszam tym razem do zapoznania się z tym artykułem: Co w sieci siedzi. Skanowanie portów).Jak widać poniżej test kończy się sukcesem – port jest otwarty i czeka na nawiązanie połączenia.
Połączenie z routerem następuje przy wykorzystaniu programu OpenSSH, po wywołaniu polecenia oraz podaniu danych uwierzytelniających połączenie zostaje zestawione (przy pierwszym połączeniu trzeba zaakceptować tzw. „odcisk palca”). Łączność z routerem została ustanowiona z hosta 10.0.1.20 (Windows7).

W tym momencie, jeszcze żadna lista ACL ograniczająca możliwość nawiązania połączenia nie została zdefiniowana tak więc połączenie może być zestawione z dowolnego komputera. Jak widać poniżej test połączenia z hosta 10.0.1.10 (WindowsXP_1) również kończy się sukcesem.

Celem ćwiczenia jest skonfigurowanie takiej listy ACL, która pozwoli na nawiązanie sesji SSH tylko z hosta 10.0.1.20 (reszcie komputerów z podsieci 10.0.1.0/24 prawo to ma być odebrane). Lista ACL wykonująca to zadanie została przedstawiona na zrzucie poniżej (zadanie wykonamy przy wykorzystaniu listy ACL rozszerzonej, nazywanej):
punkt 1 - rozpoczynamy od utworzenia listy ACL o nazwie ruchSSH,
punkt 2 - utworzony warunek zezwala na ruch TCP (zapis: permit tcp) z hosta o adresie IP 10.0.1.20 (zapis: host 10.0.1.20) do hosta o adresie IP 10.0.3.1 (zapis: host 10.0.3.1) pod warunkiem iż ruch ten dotyczy portu 22 (zapis: eq 22),
punkt 3 - ponieważ router R3 posiada w naszej sieci dwa aktywne interfejsy sieciowe tak więc połączenie SSH może zostać nawiązane z dowolnym z nich, aby host 10.0.1.20 mógł sesje SSH zestawić z interfejsem po stronie sieci 192.168.2.0/30 trzeba mu na to pozwolić. Warunek zezwalający na połączenie SSH przyjmie tę samą postać co w punkcie 2 z drobną różnicą dotyczącą hosta docelowego – zapis: host 192.168.2.1
punkt 4 - w założeniu ćwiczenia reszcie hostów, prawo nawiązania połączenia SSH ma zostać odebrane tak więc dzięki definicji warunku: deny tcp any any eq 22 łączność z routerem R3 zostaje zablokowana. A gwoli ścisłości żaden host z sieci 10.0.1.0/24 nie będzie mógł nawiązać sesji SSH z żadnym z hostów zdalnych (bardziej zasadne byłyby warunki ograniczające ten zakaz do sieci 10.0.3.0/24 oraz 192.168.2.0/30 – deny tcp any 10.0.3.0 0.0.0.255 eq 22 oraz deny tcp any 192.168.2.0 0.0.0.3 eq 22),
punkt 5 - ostatnią czynnością jest przypisanie listy do interfejsu, ponieważ listę rozszerzoną nieważne czy jest to lista numerowana czy nazywana zakładamy najbliżej celu to łączem do którego będziemy listę przypisywać jest interfejs f0/0 routera R1. O tym jeszcze nie wspominałem ale przy nazywanej liście ACL wielkość liter ma znaczenie oznacza to, ni mniej ni więcej iż nazwa listy ruchSSH nie jest tożsama z nazwą ruchssh.

Po skonfigurowaniu listy ACL przechodzimy do jej przetestowania, test rozpoczynamy od hosta 10.0.1.20. Jak widać poniżej hostowi udało się połączenie SSH z routerem nawiązać.

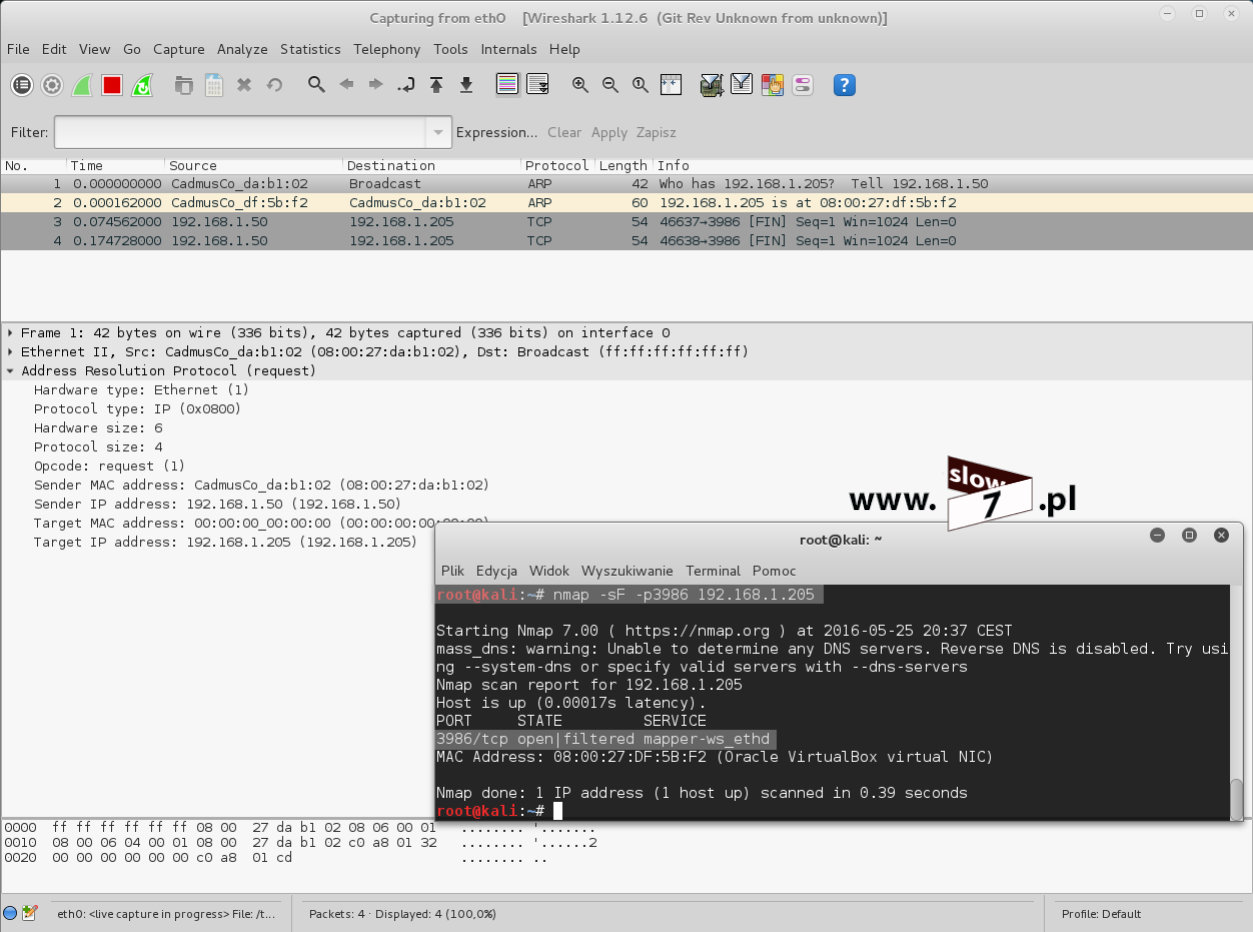
Pora na komputer o adresie IP 10.0.1.10. W tym przypadku dostęp do routera okazał się niemożliwy.

Aby faktycznie potwierdzić możliwość zestawienia poprawnego połączenia SSH został wykonany skan portu 22 interfejsu routera R1. Skan pierwszy odbył się z hosta 10.0.1.20 i jak widać port został zidentyfikowany jako: open Oznacza to możliwość nawiązania połączenia. Drugi skan przeprowadził komputer 10.0.1.10, tym razem status portu został określony jako: filtered co oznacza iż port jest filtrowany. Status taki najczęściej pojawi się w przypadku hosta znajdującego się za zaporą sieciową bądź innym mechanizmem kontrolującym ruch sieciowy. W naszym przypadku jest to lista ACL.

Aby faktycznie sprawdzić działanie listy ACL sprawdźmy jej stan. Wywołanie polecenia: show access-lists uwidoczni ilość dopasowań. Lista ACL działa jak należy.

Listy ACL standardowe oraz rozszerzone nie są jedynym dostępnym arsenałem, który pozwoli nam na kontrolowanie ruchu w naszej sieci. Opisane wyżej typy list ACL nie są w stanie zapewnić nam rozwiązania wszystkich problemów na jakie możemy natknąć się podczas sprawowania kontroli nad zarządzaną siecią. Dlatego też powstały dodatkowe rozwiązania, które pozwalają nam na wprowadzenie mechanizmów odpowiedzialnych za usprawnienie przepływu pakietów generowanych przez zarządzaną sieć.
Nie jest tajemnicą i stwierdzenie tym „Ameryki nie odkryję” że we współczesnych sieciach komputerowych dąży się do rozwiązań w których niepożądany ruch sieciowy pochodzący z zewnątrz (czytaj - ruch sieciowy pochodzący z obszarów nad którymi nie sprawujemy kontroli - najczęściej Internet) powinien zostać odfiltrowany (zablokowany) zanim zostanie przekazany do wnętrza sieci.
Oczywiście istnieją odstępstwa od tej reguły gdyż nie wszystkie pakiety, które pochodzą z zewnątrz są niepożądane i co ważne nie mogą podlegać blokowaniu. Jak więc sprawować kontrolę nad tym co trafia do naszej sieci tak by jej użytkownicy mogli realizować swoje zadania a jednocześnie nie narażać się na atak.
Jeśli znamy charakterystykę ruchu, który nie zagraża naszej sieci poprzez odpowiednią definicję list ACL możemy jawnie zezwolić na pożądany ruch. Sytuacja trochę się gmatwa gdy do końca nie jesteśmy w stanie określić charakterystyki pakietów, które do sieci mogą trafić a które powinny być blokowane.
Bardzo często spotykamy się z sytuacją w której użytkownik sieci chce nawiązać połączenie z hostem znajdującym się np. w Internecie ale okazuje się to niemożliwe gdyż lista ACL założona na routerze brzegowym na takie połączenie zabrania.
Aby rozwiązać ten problem wdrożono mechanizmy, które umożliwią nam na poprawne zestawienie połączenia (niezbędne pakiety przez listę ACL zostaną przepuszczone) ale tylko pod warunkiem iż jest to ruch powrotny, który zainicjowany został wewnątrz sieci.
Istnieją następujące rozwiązania filtrowania ruchu:
- TCP Established
- Zwrotne (reflexive) ACL
Rozpocznijmy zatem od TCP Established. Mechanizm ten zaimplementowano w urządzeniach CISCO w roku 1995 a dał on możliwość filtracji pakietów w oparciu o definicję listy rozszerzonej w połączeniu z protokołem TCP. Użycie tego mechanizmu sprowadza się do dodania w definicji warunku listy ACL parametru: established.
Dodanie flagi: established do warunku spowoduje blokadę ruchu sieciowego pochodzącego z niezaufanej sieci z wyjątkiem odpowiedzi TCP związanych z zestawionymi połączeniami, zainicjowanymi wewnątrz sieci.
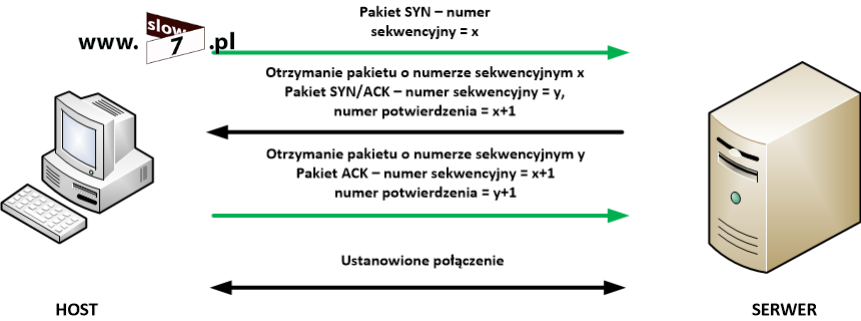
Działanie tego mechanizmu opiera się o proces nawiązywania połączenia TCP, gdyż użycie parametru: established wymusza na routerze sprawdzanie faktu ustawienia w nagłówku pakietu flag kontrolnych ACK lub RST. Jeśli jest ustawiona flaga ACK ruch TCP jest przepuszczany. W przeciwnym przypadku router zakłada, że ruch jest inicjowany na zewnątrz sieci i następuje jego blokada. Aby dokładnie zrozumieć sposób działania tej funkcji i dlaczego tak naprawdę router zezwoli bądź zabroni na przepuszczenie danego pakietu trzeba mieć wiedzę na temat etapów nawiązywania połączenia z wykorzystaniem protokołu TCP wtedy powyższy opis stanie się jasny. Aby ponownie nie opisywać tych samych zagadnień odsyłam do wpisu: Co w sieci siedzi. Skanowanie portów w którym to zawarłem dokładny opis ustanawiania sesji TCP.
Aby dokładnie zrozumieć sposób działania tego mechanizmu przyjmijmy w naszym ćwiczeniu topologię, która została przedstawiona na rysunku poniżej. Przy czym zakładamy (dla ułatwienia naszych rozważań) iż host Serwer WWW jest komputerem znajdującym się w sieci Internet zaś host WindowsXP_1 jest komputerem w sieci wewnętrznej.
Po skonfigurowaniu wszystkich funkcji wraz z adresami IP wykonujemy próbę połączenia z hosta WindowsXP_1 z serwerem www. Jak widać poniżej wprowadzenie adresu IP 192.168.1.1 w pasku adresu przeglądarki powoduje wyświetlenie domyślnej strony WWW serwera IIS. Połączenie WWW pomiędzy hostami zostało ustanowione.

Przyjęliśmy założenie iż serwer WWW znajduje się w sieci Internet tak więc aby odseparować nasza sieć wewnętrzną 192.168.0.0/24 od sieci zewnętrznej na routerze R1 została zdefiniowana lista ACL zabraniająca na wszelki kontakt z siecią lokalną 192.168.0.0/24 Założona na routerze lista ACL 100 zabrania na połączenia wykonywane w ramach protokołu IP (access-list 100 deny ip any any) – lista na interfejsie została skonfigurowana w ten sposób iż blokowany jest ruch wejściowy (ip access-group 100 in).

Po tak skonfigurowanej liście ACL żadne połączenie z sieci Internet z naszą wewnętrzną siecią nie może być ustanowione (oczywiście warunek ten dotyczy protokołu IP).
Próba ponownego połączenia z serwerem WWW kończy się niepowodzeniem. Pakiety wysłane z hosta WindowsXP_1 do serwera WWW docierają bez problemu lecz pakiety pochodzące od serwera są blokowane prze listę ACL czego konsekwencją jest brak możliwości zestawienia połączenia. Serwer WWW w tej konfiguracji jest nieosiągalny.

Oczywiście sytuacja taka jest nie do zaakceptowania gdyż uniemożliwienie użytkownikom na korzystanie z sieci WWW na pewno jako administratorowi przysporzy Ci wielu problemów. Jak więc pogodzić funkcjonalność z bezpieczeństwem naszej sieci? Należy zdefiniować nową listę ACL w której to pozwolimy na ruch WWW lecz tylko pod warunkiem iż to użytkownik go zainicjuje.
Aby wywołane przez użytkownika sieci wewnętrznej połączenie z serwerem WWW mogło dojść do skutku należy pozwolić na ruch powrotny przesyłany od strony serwera. Bądź mówiąc krócej - ruch ten nie może być blokowany przez listę ACL.
Aby wykonać zadanie należy poprawić zdefiniowaną w poprzednim kroku listę ACL. W nowej liście ACL został zdefiniowany warunek (access-list 100 permit tcp any eq 80 192.168.0.0 0.0.0.0 established), który pozwala na nawiązanie połączenia TCP z dowolnym hostem pod warunkiem iż połączenie jest nawiązywane z docelowym portem 80 a ruch ten pochodzi z sieci o prefiksie 192.168.0.0/24. Dodanie parametru: established zezwala na ruch powrotny. Gdyż ruchem dozwolonym jest tylko ruch WWW, kolejny warunek (access-list 100 deny ip any any) zabrania na nawiązanie jakichkolwiek innych połączeń. Lista tak jak poprzednia jest założona w kierunku wejściowym na interfejsie od strony Internetu.

Po skorygowaniu listy ACL połączenie z serwerem WWW zostało przywrócone.

Sprawdzenie listy ACL przy wykorzystaniu polecenia: show access-lists przekonuje nas o tym iż lista działa.

Mechanizm ten nie jest doskonały gdyż należy mieć świadomość iż użycie parametru: established pozwoli na ruch sieciowy każdemu segmentowi TCP, który będzie miał ustawioną odpowiednią flagę kontrolną a wykorzystanie go ogranicza się tylko do protokołu TCP.
Niestety nie przewidziano przechowywania informacji o stanie pakietów, które w wyniku działania mechanizmu trafiły do naszej sieci tak by stwierdzić, czy przepuszczony ruch był związany z nawiązanym połączeniem czy też nie.
Rok później po wprowadzeniu list TCP Established wprowadzono kolejny wariant list ACL, których zadaniem jest oczywiście filtrowanie pakietów – są to tzw. listy zwrotne (reflexive). Tak jak w przypadku rozwiązania opisanego wyżej administratorzy sieci wykorzystują zwrotne ACL, aby zezwolić na ruch IP (nie tylko TCP) pochodzący z ich sieci i zabronić na ruch IP zainicjowany z zewnątrz.
Wadą mechanizmu ACL established jest brak wsparcia dla innych protokołów niż TCP co jest dość poważnym ograniczeniem . W rozwiązaniu reflexive ACL filtrowanie ruchu odbywa się w oparciu o adresy źródłowe i docelowe oraz numery portów. Takie podejście do sprawy umożliwia wykorzystanie tego rozwiązania do filtrowania ruchu sieciowego w oparciu o protokół UDP czy ICMP.
W zwrotnych listach ACL dodatkowo zaimplementowano tzw. filtry tymczasowe, których zadaniem jest zezwolenie na ruch powrotny. Tworzenie filtrów tymczasowych odbywa się poprzez analizę ruchu wyjściowego (podczas rozpoczęcia nowej sesji IP) a wpisy są usuwane po zakończeniu sesji.
Aby pokazać sposób działania list zwrotnych ACL i ich konfigurację wykonajmy ćwiczenie w którym pozwolimy na łączność WWW i DNS - ruch musi być zainicjowany po stronie sieci lokalnej. Ruch sieciowy pochodzący z zewnątrz ma zostać zablokowany.
Etapy konfiguracji list zwrotnych przedstawiają się następująco (do omówienia tego typu list ACL została użyta ta sama topologia sieciowa co w przykładzie wyżej):
Krok 1.
Rozpoczynamy od utworzenia wewnętrznej listy ACL (jest to lista rozszerzona), której zadaniem jest sprawdzanie połączeń wyjściowych - punkt 1 (lista ta przyjęła nazwę WEW_ACL). W scenariuszu szukanymi połączeniami będę te, które odpowiadają za ruch związany z przeglądaniem stron internetowych i rozwiązywaniem nazw domenowych (DNS) - punkt 2 (korzystanie z usługi DNS zostało ustalone na 5 sekundowy timeout).
Stworzenie wewnętrznej ACL, która szuka nowych połączeń wyjściowych i tworzy tymczasowe zwrotne ACE (wpisy do ACL)
Krok 2.
Aby połączenie doszło do skutku musimy pozwolić na ruch powrotny dlatego w tym celu została utworzona zewnętrzna lista ACL (lista ta przyjęła nazwę ZEW_ACL) - punkt 3. Podczas definicji warunków określających dozwolony ruch sieciowy został użyty parametr: reflect Zadaniem tej opcji jest przekazanie informacji o ruchu wyjściowym tak by poprzez utworzenie odpowiednich wpisów tymczasowych ruch powrotny nie był blokowany. Ruch związany z WWW zostaje przekazany do zmiennej WWW zaś informacja o ruchu domenowym do zmiennej DNS (punkt 2). W zewnętrznej liście ACL dzięki użyciu flagi: evaluate następuje definicja zmiennych WWW oraz DNS - punkt 4.
Dzięki takiej konfiguracji będą mogły zostać utworzone wpisy tymczasowe, które router utworzy automatycznie dzięki analizie połączeń (informacji zawartych w nagłówkach pakietów) a których zadaniem jest zezwolenie na ruch pakietów od strony Internetu do naszej sieci wewnętrznej. Inny ruch sieciowy od strony Internetu do sieci wewnętrznej nie będzie przepuszczony gdyż nie jest on częścią połączenia, które zostało zainicjowane po stronie sieci lokalnej. Warunek: deny ip any any jawnie zabrania na jakąkolwiek komunikację z wykorzystaniem protokołu IP.
Krok 3.
Ostatnią czynnością jest umieszczenie utworzonych list ACL na odpowiednich interfejsach. Ponieważ lista ACL WEW_ACL zezwala na połączenia WWW oraz DNS zostaje ona umieszczona na interfejsie po stronie Internetu w kierunku wyjściowym (punkt 5) zaś w liście ACL ZEW_ACL będą tworzone wpisy tymczasowe zezwalające na ruch powrotny to kierunek działania tej listy został zdefiniowany na: in (wejście) - punkt 6.
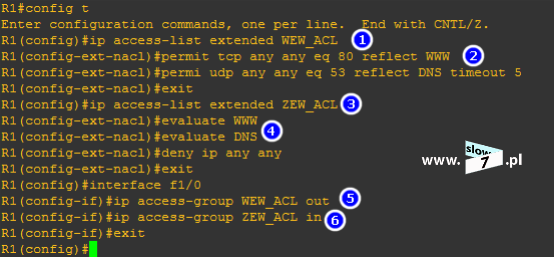
Listy zwrotne ACL zostały skonfigurowane, sprawdźmy zatem efekt przeprowadzonej konfiguracji. Host 192.168.0.1 znajduje się w sieci lokalnej i powinien mieć możliwość komunikacji z serwerem www. Jak widać poniżej po wprowadzeniu adresu serwera w oknie przeglądarki połączenie WWW zostaje nawiązane. Test ping pomiędzy hostem a serwerem kończy się niepowodzeniem gdyż ruch ICMP nie pasuje do zdefiniowanych reguł i dlatego jest blokowany.

Wydanie polecenia: show access-lists ukaże nam ilość zastosowania warunków. Jak można stwierdzić poniżej ruch WWW i DNS opuszczający naszą sieć lokalną jest prawidłowo przesyłany dalej.

Zwrotne listy ACL dla początkujących mogą stanowić pewne wyzwanie tak więc spróbujmy prześledzić jeszcze jeden przykład. Bazujemy na tej samej topologii i spróbujmy wykonać przykład w którym będzie można wykonać test przy użyciu polecenia: ping Założenie ćwiczenia jest takie, że wykorzystujemy zwrotną listę ACL; test ping następuje z sieci 192.168.0.0/24 do sieci 192.168.1.0/24 Sieć 192.168.1.0/24 oczywiście nie może bezpośrednio skomunikować się z siecią 192.168.0.0/24 przy użyciu protokołu ICMP; inny ruch jest dozwolony.
Tak jak w poprzednim przykładzie rozpoczynamy od definicji warunków listy ACL, która będzie sprawdzać ruch wyjściowy – lista ACL została nazwana: PING_OUT W warunkach listy została zdefiniowana reguła ICMP_POWROT odpowiedzialna za utworzenie wpisów pozwalających na powrót pakietów ICMP. Wpis: permit ip any any zezwala na ruch związany z protokołem IP (punkt 1).
W drugiej liście ACL za pomocą słowa evaluate określono regułę zwrotną ICMP_POWROT odpowiedzialną za przepuszczenie ruchu sieciowego ICMP pochodzącego z zewnątrz a będący odpowiedzią na ruch zainicjowany z sieci lokalnej. Jeśli router poprzez analizę danych zawartych w nagłówku pakietu nie dopasuje go do reguły ICMP_POWROT nastąpi próba dopasowania do warunków zdefiniowanych dalej. Warunek: deny icmp ip any any jawnie zabrania na ruch ICMP, który nie spełnia wymogów ruchu zwrotnego (punkt 2).
Ostatnią czynnością jest przypisanie utworzonych list do interfejsu oraz określenie kierunku ich działania. Ponieważ lista PING_OUT odpowiada za ruch wychodzący jej kierunek działania został zdefiniowany na wyjście. Natomiast lista ACL jest listą analizującą ruch powrotny tak więc kierunek działania został ustalony na wejście (punkt 3).

Nie pozostaje nam nic innego jak sprawdzić efekt działania zdefiniowanych list ACL.
Przeprowadźmy test z ping z hosta 192.168.0.1 w kierunku hosta 192.168.1.1 Jak można stwierdzić po analizie zrzutu poniżej test kończy się sukcesem. Powrotny ruch ICMP został przepuszczony gdyż był on częścią sesji króra została zapoczątkowywana po stronie sieci 192.168.0.0/24

Ruch ICMP w drugim kierunku (od hosta 192.168.1.1 w kierunku hosta 192.168.0.1) jest blokowany gdyż router wie iż ruch ten nie stanowi części komunikacji.

Przy definicji warunku: deny icmp ip any any użyliśmy parametru log, który pozwoli nam na uzyskanie więcej szczegółów na temat zablokowanych pakietów. Jak widać zablokowane pakiety zostały wysłane z hosta 192.168.1.1 a zgodnie z zdefiniowanymi listami ACL pakiety te mają być blokowane.

Dzięki zaś zezwoleniu na dowolny ruch IP (warunki: permit ip any any) komunikacja z hostami zostaje zachowana – próba skopiowania pliku pomiędzy hostami kończy się sukcesem.

Aby użytkownicy mogli uzyskać dostęp do chronionych przez listę ACL obszarów sieci administrator może wykorzystać do tego celu tzw. listy dynamiczne (ang. dynamic ACL). Ten typ list nazywany jest również listami lock-and-key (zamek i klucz). Zadaniem tego typu list jest uwierzytelnienie użytkownika i po prawidłowym przeprowadzeniu tego procesu użytkownik uzyskuje dostęp do chronionego obszaru sieci (możliwość nawiązania połączenia z hostem lub całą podsiecią. Dostęp jest przyznawany przez ograniczony czas.
Sposób działania list dynamicznych opiera się o takie mechanizmy jak:
- łączność telnet bądź SSH,
- uwierzytelnianie lokalne lub zdalne,
- rozszerzone ACL.
Sposób działania oraz konfiguracja dynamicznej listy ACL można opisać w następujących krokach:
- rozpoczynamy od zdefiniowania rozszerzonej listy ACL, której zadaniem jest blokada ruchu sieciowego z wyjątkiem połączeń Telnet bądź SSH,
- użytkownicy, którzy chcą połączyć się z siecią, która jest chroniona przez listę ACL są tak długo blokowani, dopóki nie wykonają połączenia Telnet. Nawiązanie połączenia oczywiście musi zakończyć się sukcesem tzn. by połączenie doszło do skutku należy poprawnie się uwierzytelnić,
- po nawiązaniu połączenia Telnet (bądź SSH). Połączenie zostaje zakończone automatycznie,
- poprawne uwierzytelnienie spowoduje dodanie jednego dynamicznego warunku do już istniejącej listy ACL,
- dodany wpis umożliwia nawiązanie połączenia z siecią, która w normalnych warunkach jest niedostępna. Dodatkowo możliwe jest określenie czasu bezczynności oraz timeout.
Dynamiczne listy ACL stosujemy w celu:
- aby zapewnić użytkownikowi bądź grupie użytkowników zdalnych dostęp do sieci wewnętrznej,
- aby hosty w sieci lokalnej miały dostęp do hostów w sieci zdalnej, chronionej przez firewall.
Konfigurację listy dynamicznej rozważymy na już znanej nam topologii sieciowej, która dla przypomnienia została przedstawiona poniżej. Celem naszego ćwiczenia jest umożliwienie hostowi 192.168.0.1 nawiązanie połączenia z komputerem 192.168.1.1. Zadanie ma być wykonane oczywiście przy wykorzystaniu listy dynamicznej ACL.
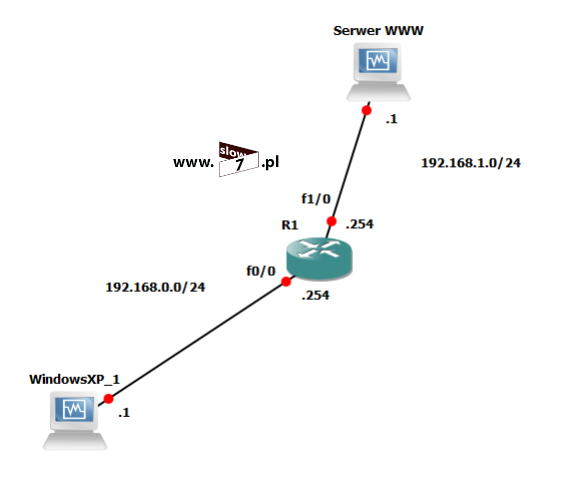
Kolejną czynnością jest definicja listy ACL. W pierwszym kroku zezwalamy na nawiązanie połączenia Telnet z interfejsem routera – punkt 2. Interfejs routera z którym będzie nawiązywane połączenie Telnet oczywiście dla hosta 192.168.0.1 musi być osiągalne. Dlatego też interfejs routera został ustalony na 192.168.0.254 gdyż oba adresy IP leżą w wspólnej przestrzeni adresowej IP.
Kolejny warunek listy ACL jest wpisem dynamicznym o nazwie DOSTEP Wpis ten zawiera warunek zezwalający na łączność pomiędzy sieciami 192.168.0.0/24 a 192.168.1.0/24 Wpis ten zostanie dodany po nawiązaniu połączenia Telnet i poprawnym uwierzytelnieniu – punkt 3.
Po definicji listy ACL następuje jej powiązanie z interfejsem f0/0 routera R1.
Aby lista ACL zadziałała musimy oczywiście zezwolić na nawiązanie połączenia Telnet. Tak więc kolejny krok (punkt 4) odpowiada za konfigurację linii VTY tak by sesja Telnet mogła zostać z routerem prawidłowo nawiązana. Zostaje ustawione uwierzytelnienie, które ma być przeprowadzone przy wykorzystaniu lokalnej bazy użytkowników.

Ponieważ na zrzucie powyżej nie wszystkie polecenia zostały uwidocznione poniżej jeszcze raz została przedstawiona konfiguracja dynamicznej listy ACL.

Sprawdźmy zatem dostępność sieci 192.168.1.1/24 z poziomu hosta 192.168.0.1 i wykonajmy test ping. Jak widać brak jest możliwości nawiązania połączenia pomiędzy obiema sieciami – host 192.168.0.1 nie może skomunikować się z hostem 192.168.1.1

Aby hosty mogły swobodnie między sobą prowadzić wymianę danych należy dodać warunek do listy ACL, który na taką komunikację pozwoli. Warunek ten zostanie dodany dynamicznie po poprawnym uwierzytelnieniu się za pomocą usługi Telnet. Nawiążmy więc połączenie Telnet z routerem R1.
Jak widać po kolejnym zrzucie połączenie zostało nawiązane i po podaniu prawidłowych danych użytkownika automatycznie zamknięte.

Sprawdźmy stan listy ACL. Rysunek poniżej przedstawia listę ACL przed nawiązaniem połączenia Telnet (punkt 1) i po nawiązaniu połączenia – punkt 2. Różnica pomiędzy oboma stanami listy ACL tkwi w dodaniu jednego warunku do listy ACL po nawiązaniu połączenia Telnet. Warunek ten zezwala na komunikację pomiędzy sieciami.

Ponowne wykonanie testu ping zostaje zakończone sukcesem, hosty nawiązały między sobą komunikację.
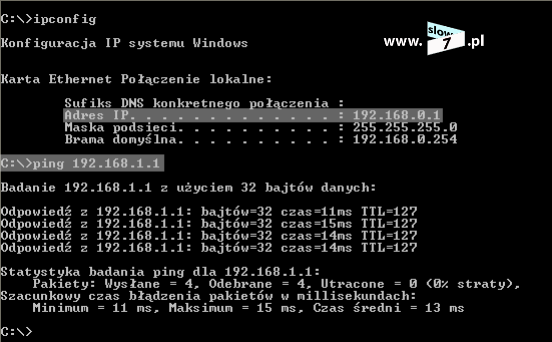
Sprawdzenie listy ACL da nam informację o ilości dopasowań oraz czasie aktywności dynamicznego wpisu.

Dynamiczna lista ACL została skonfigurowana prawidłowo.
Istnieje jeszcze jeden typ list ACL są to tzw. listy ACL czasowe (ang. time-based). Listy te pozwalają nam prowadzić kontrolę dostępu w oparciu o czas. Czasowe listy ACL są wygodnym mechanizmem gdyż z ich wykorzystaniem możemy dostęp do sieci przyznawać bądź odbierać w zależności od dnia tygodnia czy godziny.
Standardowo aby wytłumaczyć implementację czasowej listy ACL wykonajmy ćwiczenie, którego założenie jest następujące – Zabrońmy na komunikację pomiędzy sieciami 192.168.0.0/24 a 192.168.1.0/24 w każdy czwartek pomiędzy godziną 21:40 a 21:50. Oczywiście bazujemy nadal na tej samej topologii sieciowej co w poprzednich ćwiczeniach.
Aby zaimplementować time-based ACL rozpoczynamy od utworzenia zakresu czasu (time-range), który definiuje czas w którym lista ACL będzie aktywna. Stworzony zakres czasu ma przypisaną nazwę, do której będziemy odwoływać się podczas tworzenia warunków listy ACL. Ograniczenia zaś są definiowane przez samą listę ACL.
Rozpoczynamy od zdefiniowania zakresu. Time-range definiujemy w trybie konfiguracji globalnej po wydaniu polecenia: time-range <nazwa_zakresu> Po wydaniu polecenia określamy ramy czasowe. Interesujący nas okres obejmuje czwartek pomiędzy godziną 21:40 a 21:50 tak więc w trybie definicji zakresu wydajemy polecenie: Thursday 21:40 to 21:50 a że zdefiniowany interwał czasowy ma obejmować każdy czwartek zostaje dodany parametr: periodic Zdefiniowanemu zakresowi została przypisana nazwa: DOSTEP

Po zdefiniowaniu czasu obowiązywania listy ACL przystępujemy do określenia warunków samej listy ACL. Celem zadania jest uniemożliwienie komunikacji pomiędzy sieciami tak więc warunek listy ACL przyjmuje postać: deny ip any any a dodatkowo dzięki parametrowi: time-range do warunku zostaje przypisany zakres czasowy obowiązywania tego wpisu.

Stworzona lista ACL zostaje przypisana do interfejsu f0/0 routera R1. Kierunek działania listy został ustalony na wejście.

Sprawdzenie listy uwidacznia jej stan – lista ACL jest nieaktywna.

Lista ACL jest nieaktywna tak więc określone warunki listy nie są włączone. Sprawdźmy zatem czy uda nam się nawiązać komunikację pomiędzy hostami 192.168.0.1 a 192.168.1.1. Test ping kończy się niepowodzeniem. Czas wykonania testu to 21:35 czyli poza ustalonymi ramami zakresu – warunek zabraniający na komunikację ma być aktywny od 21:40

Lista ACL nie obowiązuje a my nie mamy dostępu do sieci 192.168.1.0/24 a według założeń scenariusza dostęp ma być odebrany tylko na 10 minut pomiędzy 21:40 a 21:50 Lista ACL zabrania na komunikację ponieważ nie wolno zapomnieć iż pomimo tego, że jest to czasowa lista ACL to nadal jest to lista ACL na końcu, której jest umieszczony niejawny warunek: deny any any Tak więc by komunikacja pomiędzy ustalonym zakresem była możliwa trzeba za pomocą warunku: permit ip any any jawnie na ruch sieciowy zezwolić.

Sprawdzenie listy ACL uwidacznia dodany warunek. Lista odbierająca dostęp do sieci 192.168.1.0/24 jest nieaktywna.

Sprawdźmy zatem jeszcze raz czy uda się nawiązać połączenie pomiędzy hostami. Połączenie doszło do skutku, wprowadzona korekta zdała egzamin. Połączenie jest możliwe gdyż czas obowiązywania zakazu jeszcze nie nadszedł.

Po 21:40 w czwartek wpis zabraniający na komunikację z stanu nieaktywny przechodzi do stanu aktywny. Ponieważ reguła ma niższy numer sekwencyjny jest stosowana jako pierwsza.

Komunikacja pomiędzy obiema podsieciami jest niemożliwa.

Ponowne sprawdzenie listy ACL uwidacznia liczbę dokonanych dopasowań.

Po godzinie 21:50 (oczywiście w czwartek) reguła kończy swe działanie.

Komunikacja pomiędzy sieciami zostaje przywrócona.

Z mechanizmem ACL związana jest jeszcze jedna funkcja a mianowicie grupy obiektów w listach ACL.
Grupy obiektów pozwalają nam na dokonanie klasyfikacji użytkowników, urządzeń oraz protokołów w grupy. Po dokonaniu przypisania do określonych grup możliwe jest utworzenie reguł kontroli dostępu obejmujących całą grupę.
Grupy obiektów można tworzyć zarówno dla IPv4, jak i dla IPv6.
Aby omówić ten mechanizm przyjmijmy, że mamy do czynienia z topologią sieciową przedstawioną na rysunku poniżej.

W przedstawionej powyżej topologii mamy do czynienia z trzema serwerami, z których każdy wymaga zezwolenia na ruch z zewnątrz dla trzech protokołów. Protokoły te to: SMTP (port 25), HTTP (port 80) oraz HTTPS (port 443).
Podczas definicji warunków listy ACL musielibyśmy utworzyć wpisy typu permit dla każdego serwera i dla każdego protokołu z osobna. Przykładowa konfiguracja routera wyglądałaby następująco:

W przypadku dodania kolejnego serwera jak również i dodatkowych protokołów musielibyśmy edytować listę ACL tak aby uwzględnić nowe wymagania.
Aby zaoszczędzić sobie czasu i problemów z bezpośrednią edycją listy ACL możemy wykorzystać mechanizm grup obiektów.
Konfiguracja rozpoczyna się od utworzenia grupy usług (ang. service group). Poniżej na listingu została utworzona grupa usług o nazwie: USŁUGI

Następnym etapem jest, utworzenie grupy urządzeń (ang. network group). Podczas definicji członków grupy możemy skorzystać ze słowa kluczowego range lub host a także zdefiniować podsieć. Poniżej została utworzona grupa urządzeń o nazwie SERWERY

Ostatnim zaś krokiem jest utworzenie samej listy ACL.

Aby lista mogła zacząć działać trzeba ją jeszcze powiązać z danym interfejsem. W naszym scenariuszu oczywiście będzie to interfejs routera znajdujący się od strony Internetu a kierunek działania musi przyjąć stan: in
Odtąd gdy zostanie dodany nowy serwer bądź usługa należy jedynie zmodyfikować grupę obiektów.
Powoli zbliżamy się do końca wpisu więc jako ostatni punkt naszych rozważań przed podsumowaniem proponuję kilka przykładów najczęściej stosowanych list ACL.
Lista ACL przedstawiona poniżej odpowiada za zablokowanie pakietów TCP z ustawionymi niedozwolonymi flagami tj. pakietów, które w normalnym funkcjonowaniu sieci nigdy nie powinny zostać utworzone. Więcej na ten temat znajdziesz w wpisie: Co w sieci siedzi. Skanowanie portów. Zastosowanie poniższych warunków zablokuje metody skanowania, które mogłyby być wykorzystane przez atakującego naszą sieć.
access-list 111 deny tcp any any ack fin psh rst syn urg
access-list 111 deny tcp any any fin
access-list 111 deny tcp any any urg psh fin
access-list 111 deny tcp any any rst syn
access-list 111 deny tcp any any rst syn fin
access-list 111 deny tcp any any syn fin
access-list 111 deny tcp any any rst syn fin ack
access-list 111 deny tcp any any syn fin ack
Ze względów bezpieczeństwa i dobrą praktyką jest na routerze brzegowym zablokowanie wszystkich pakietów, które mają następujące adresy źródłowe IP:
- Adresy typu: local host (127.0.0.0/8)
- Adresy przypisane siecią prywatnym (10.0.0.0/8, 172.16.0.0/12, 192.168.0.0/16),
- Adresy z grupy multikastowej (224.0.0.0/4).
Przykładowa lista ACL mogłaby mieć postać:
access-list 180 deny ip 0.0.0.0 0.255.255.255 any
access-list 180 deny ip 127.0.0.0 0.255.255.255 any
access-list 180 deny ip 10.0.0.0 0.255.255.255 any
access-list 180 deny ip 172.16.0.0 0.15.255.255 any
access-list 180 deny ip 192.168.0.0 0.0.255.255 any
access-list 180 deny ip 224.0.0.0 15.255.255.255 any
access-list 180 deny ip host 255.255.255.255 any
Kolejny przykład zabrania na ruch sieciowy (wyjściowy) pakietom z adresem źródłowym IP innym, niż ten, który obowiązuje w sieci wewnętrznej (czyli zakres adresów IP, który sam ustaliłeś).
access-list 180 deny ip <ustalony_adres_sieci> any
Ograniczenie dostępu do routera przy połączeniach zdalnych
Połączenie z routerem może ustanowić host o zdefiniowanym adresie IP.
access-list 90 permit host <adres_IP>
access-list 90 deny any
W trybie konfiguracji linii VTY
access-class 90 in
Zabronienie na ruch Telnet (TCP, Port 23)
access-list 102 deny tcp any any eq 23
access-list 102 permit ip any any
Zabronienie na ruch FTP (TCP, Port 21)
access-list 102 deny tcp any any eq ftp
access-list 102 deny tcp any any eq ftp-data
access-list 102 permit ip any any
Zezwolenie na ruch FTP
access-list 102 permit tcp any any eq ftp
access-list 102 permit tcp any any eq ftp-data established
Zezwolenie na ruch DNS
access-list 112 permit udp any any eq domain
access-list 112 permit udp any eq domain any
access-list 112 permit tcp any any eq domain
access-list 112 permit tcp any eq domain any
Zezwolenie na aktualizacje związane z routingiem
Protokół RIP - access-list 102 permit udp any any eq rip
Protokół IGRP - access-list 102 permit igrp any any
Protokół EIGRP - access-list 102 permit eigrp any any
Protokół OSPF - access-list 102 permit ospf any any
Protokół BGP - access-list 102 permit tcp any any eq 179 oraz access-list 102 permit tcp any eq 179 any
Podsumowanie (czyli to co warto powtórzyć bądź to o czym zapomniałem a co warto wiedzieć):
- Osobna lista ACL powinna istnieć dla każdego protokołu i kierunku.
- Standardowe listy ACL umiejscawiamy jak najbliżej miejsca docelowego, którego dotyczą.
- Rozszerzone listy ACL umieszczamy jak najbliżej źródła, którego dotyczą.
- Warunki budujące listę ACL są analizowane po kolei od góry do dołu aż do odnalezienia dopasowania o położeniu danego wpisu decyduje numer sekwencyjny.
- Jeśli po analizie listy ACL nie wykryto dopasowania do żadnego z zdefiniowanych warunków pakiet jest odrzucany na wskutek działania nie jawnej instrukcji: deny any. Warunek ten nie jest uwzględniany na listingach konfiguracji.
- Warunki budujące daną listę ACL powinny zostać zdefiniowane w kolejności od szczegółowych do ogólnych. Oznacza to iż na początku listy ACL znajdują się instrukcje dotyczące pojedynczych hostów zaś po nich instrukcje odnoszące się do grup i ogółu.
- W przypadku wildcard mask bit 0 oznacza - wykonaj dopasowanie, zaś bit 1 - zignoruj.
- Tworzone wpisy listy ACL zawsze są dodawane na końcu listy.
- Zanim zostanie zastosowana instrukcja permit bądź deny musi nastąpić zgodność dopasowania informacji zawartych w nagłówku pakietu do warunku listy ACL.
- Komentarze o sposobie działania listy ACL umieszczamy w osobnym pliku, zaś w opisie listy ACL definiujemy nazwę pliku zawierającego opis.
- Lista ACL dla ruchu wychodzącego nie jest stosowana dla pakietów, których źródłem jest router lokalny.
- Jeśli potrzeba jest ograniczenia ruchu sieciowego w oparciu o czas zastosuj listy ACL czasowe (ang. time-based).
- Aby użytkownicy mogli uzyskać dostęp do chronionych przez listę ACL obszarów sieci wykorzystaj do tego celu listy dynamiczne.
- Listy typu reflexive ACL umożliwiają filtrowanie ruchu w oparciu o adresy źródłowe i docelowe oraz numery portów. Ich użycie nie ogranicza się tylko do protokołu TCP jak to ma miejsce w przypadku list ACL Established.
Rozwiązanie
Możliwa jest taka definicja listy ACL gdyż zapis: permit 192.168.0.6 0.0.0.1 zezwala na ruch sieciowy pochodzący od hostów z zdefiniowanymi adresami IP 192.168.0.6 oraz 192.168.0.7 Dzieje się tak ponieważ maska wieloznaczna 0.0.0.1 tożsama jest z podsiecią 255.255.255.254 a sieć ta wraz w połączeniu z adresem IP 192.168.0.6 definiuje tylko dwa adresy IP - 192.168.0.6 oraz 192.168.0.7
Po dokonaniu korekty jak widać poniżej z hosta 192.168.0.1 nie udaje nam się spingować komputer 192.168.1.1
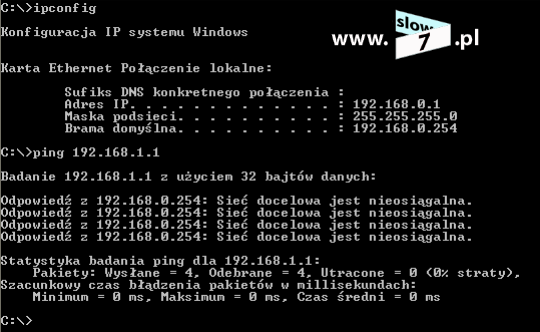
Zaś przy użyciu hosta 192.168.0.6 test ping kończy się sukcesem.

Sprawdzenie listy ACL tylko utwierdza nas w przekonaniu iż przyjęte rozwiązanie jest jak najbardziej prawidłowe.

]]>