Jak utworzyć macierz w systemie Windows oraz jak nią zarządzać dowiesz się Czytelniku po lekturze tych wpisów:
- Windows Server 2012. Poradnik administratora. Serwer plików
- Zarządzanie dyskami czyli słów kilka o partycjach i woluminach
Utworzenie macierzy przeprowadzimy w systemie Linux Ubuntu 16.04 a zajmiemy się macierzami typu RAID0, RAID1 oraz RAID5.
Zanim przejdziemy do ich konfiguracji szybkie przypomnienie dotyczące typu tworzonych macierzy.
Wikipedia bardzo fajnie podaje definicję i sens stosawnia tego typu rozwiązania (źródło: https://pl.wikipedia.org/wiki/RAID)
RAID (ang. Redundant Array of Independent Disks – nadmiarowa macierz niezależnych dysków) – sposób wykorzystania w systemie komputerowym dwóch lub większej liczby dysków twardych, w którym dyski te współpracują pomiędzy sobą. Osiąga się w ten sposób szereg różnorodnych możliwości nieosiągalnych przy użyciu zarówno pojedynczego dysku, jak i kilku dysków podłączonych jako oddzielne.
Rozwiązania typu RAID używane są w następujących celach:
- zwiększenie niezawodności (odporność na awarie);
- zwiększenie wydajności transmisji danych;
- powiększenie przestrzeni dostępnej jako jedna całość.
W artykule zajmiemy się macierzą RAID0, RAID1 oraz RAID5 tak więc zanim przejdziemy do konfiguracji krótkie omówienie.
RAID0 (tzw. striping)
Do utworzenia macierzy należy użyć przynajmniej dwa dyski (można więcej), powstała macierz oczywiście w systemie będzie widziana jako pojedynczy dysk (tak samo jest w przypadku RAID1 oraz RAID5), przy czym dostępna przestrzeń równa jest: liczba dysków x rozmiar najmniejszego z dysków (w wpisie będziemy łączyć dwa dyski o rozmiarze 5 GB tak więc całkowity rozmiar utworzonej macierzy wyniesie 10 GB). Zapis danych rozłożony jest pomiędzy dyskami co oznacza, że dany plik (a raczej jego część) tak naprawdę zapisywany jest na każdym z dysków wchodzącym w skład macierzy. Dzięki równoległemu zapisowi pliku znacząco podnosimy wydajność wykonywanych operacji odczytu/zapisu w myśl zasady - „co ma wykonać jeden to w dwójkę pójdzie szybciej”. Wadą tego typu rozwiązania jest wzrost awaryjności gdyż w przypadku wystąpienia usterki jednego z dysków tracimy dostęp do przechowywanych danych.
Macierz RAID0 schematycznie została pokazana na rysunku poniżej.

RAID1 (tzw. mirroring)
Praca macierzy opiera się na replikacji zapisywanych danych pomiędzy dyskami budującymi macierz. Całkowity pojemność macierzy przyjmuje rozmiar najmniejszego użytego dysku. Priorytetem przy wyborze tego typu rozwiązania jest bezpieczeństwo przechowywanych danych ponieważ awaria dysku nie powoduje utraty plików gdyż ich kopia znajduje się na innym dysku wchodzącym w skład macierzy. Wadą macierzy RAID1 jest zmniejszona szybkość zapisu danych (choć zależne jest to wyboru strategii zarządzania bo np. możliwe jest użycie dwóch macierzy RAID0 a następnie połączenie ich w macierz RAID1).
Macierz użyta w wpisie przyjmie rozmiar 8 GB gdyż do jej zbudowania zostaną użyte dwa dyski o takiej właśnie pojemności.
Schemat zapisu danych na macierzy typu RAID1 został przedstawiony poniżej.

RAID5
Praca macierzy opiera się na wyliczeniu tzw. sum kontrolnych, których zadaniem jest przywrócenie danych w przypadku awarii jednego z dysków. Sumy te są rozproszone po całej strukturze dysku co oznacza, że są one zapisywane na każdym z dysków. Do budowy macierzy należy przeznaczyć minimum trzy dyski przy czym jej pojemnośc równa się: n minus 1 dysków (do obliczenia całkowitej pojemności macierzy brany jest dysk o najmniejszym rozmiarze). Użycie tego typu macierzy zapewnia Nam zwiększone bezpieczeństwo przechowywanych danych przy jednoczesnym zapewnieniu wysokich wartości odczytu i zapisu.
Do utworzenia macierzy RAID5 użyjemy trzech dysków o pojemności 10 GB każdy tak więc całkowity rozmiar macierzy wyniesie 20 GB (3 dyski razy 10 GB minus pojemność najmniejszego czyli 10 GB).
Schemat zapisu danych na macierzy RAID5 został ukazany na rysunku poniżej.

To co zostało już kilka razy zaznaczone ale nie powiedziane wprost to sprawa pojemności użytych dysków, które posłużą do zbudowania macierzy. Jak już pewnie sam do tego Czytelniku doszedłeś to przy konfiguracji macierzy nie opłaca używać się nośników o różnej pojemności gdyż zawsze wiąże się to z marnotrastwem pojemności dysku. Dlatego też dobrą zasadą jest używanie dysków o takim samym rozmiarze.
Przechodzimy do konfiguracji macierzy.
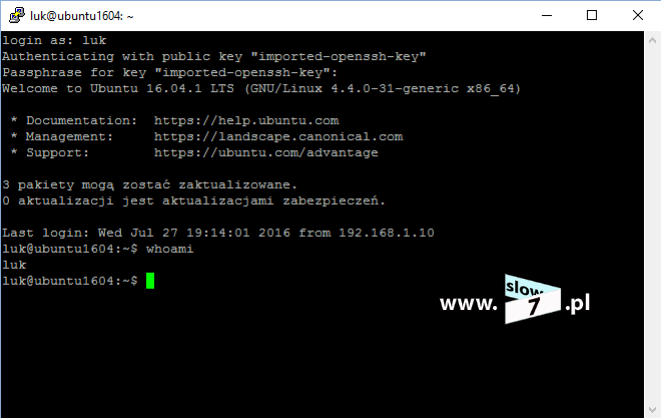
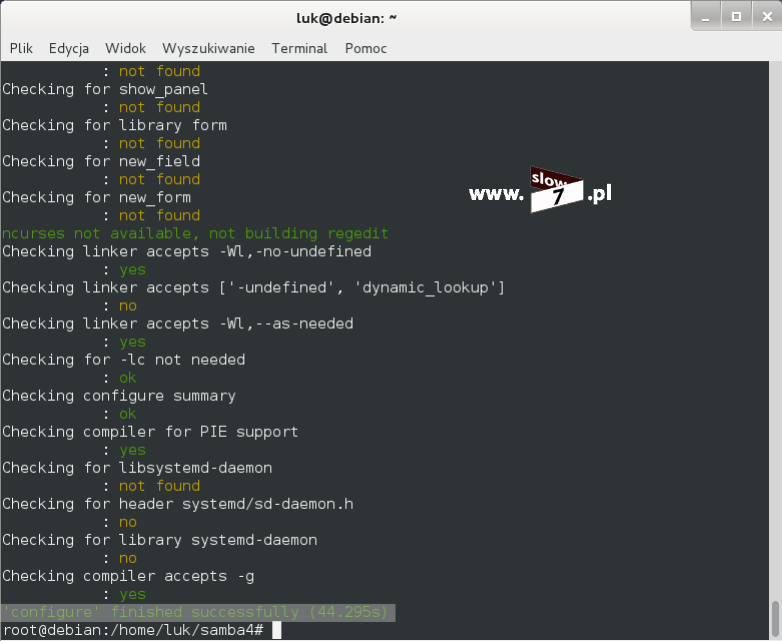
Po podłączeniu nowych dysków twardych rozpoczynamy od sprawdzenia czy dyski te widoczne są w systemie. Do sprawdzenia może posłużyć Nam komenda: lsblk Jak widać poniżej wszystkie 6 dysków jest aktywnych (dyski od sdb do sdh - dwa o pojemności 5GB, dwa o pojemności 8GB i trzy o pojemności 10 GB).

Wylistowanie dostępnych dysków możemy również sprawdzić za pomocą innego polecenia (a tak naprawdę dwóch połączonych ze sobą poleceń): ls | grep sd (polecenie wydajemy po przejściu do folderu /dev/).

Po upewnieniu się, że wszystkie z podłączonych dysków działają prawidłowo przechodzimy do utworzenia na nich partycji. Partycję utworzymy za pomocą narzędzia: fdisk.
Poniżej na rysunku została przedstawiona lista wszystkich dostępnych opcji, zaś my wykorzystamy kilka z nich:
- n - definicja nowej partycji,
- m - pomoc,
- L - lista typów partycji,
- w - zapis ustawień.

Narzędzie wywołujemy z parametrem dysku - polecenie przyjmie postać: fdisk /dev/sdb
Po wywołaniu polecenia (przez operację tworzenia partycji przeprowadzi nas kreator) na pierwsze pytanie dotyczące wyświetlenia pomocy odpowiadamy przecząco - wybieramy: n (wyświetlenie pomocy odbywa się po wybraniu znaku: m) - punkt 1.
Na każdym z dysków będzie tworzona tylko jedna podstawowa partycja (partycji tej zostanie przypisane całe dostępne miejsce) dlatego też by utworzyć partycję tego typu na kolejne pytanie odpowiadamy poprzez wprowadzenie znaku: p - punkt 2
Kolejne pytania kreatora dotyczą numeru partycji (punkt 3) oraz definicji numeru pierwszego i ostatniego sektora dysku (punkt 4). Na pytania te odpowiadamy wybierając klawisz Enter akceptując tym samym zaproponowane opcje domyślne.
Po zatwierdzeniu wszystkich opcji partycja zostaje utworzona (punkt 5).

Ostatnią czynność jaką musimy wykonać jest zdefiniowanie typu partycji. Aby określić typ partycji należy wprowadzić znak: t - punkt 6.
Aby poznać wszystkie możliwości została wprowadzona litera: L po wybraniu, której wyświetli się tabela wszystkich dostępnych opcji - punkt 7.
Ponieważ tworzona partycja będzie należeć do macierzy jej typ ustalamy na: Linux RAID auto Typ ten definiujemy poprzez wprowadzenie wartości: fd - punkt 8.
Aby zatwierdzić całość wprowadzonych ustawień wybieramy: w Narzędzie fdisk kończy swoje działanie - punkt 9.
Wszystkie opcje dotyczące struktury dysku zostały zdefiniowane.

Operację tą powtarzamy dla wszystkich pozostałych dysków (od sdc do sdh).
Po definicji partycji dysku, efekt przeprowadzonej konfiguracji sprawdzimy poprzez ponowne wybranie polecenia: lsblk (użycie parametru -a powoduje ukazanie wszystkich dysków). Partycje podstawowe na wszystkich dyskach zostały utworzone (jedna partycja na każdym z dysków: od sbb1 do sdh1).

I ten sam efekt uzyskamy wydając znane Nam już polecenie: ls /dev/ | grep sd - jak widać i tu wydanie komendy uwidacznia fakt utworzenia partycji dla każdego z dysków.

Tworzenie macierzy rozpoczniemy od utworzenia macierzy typu RAID0.
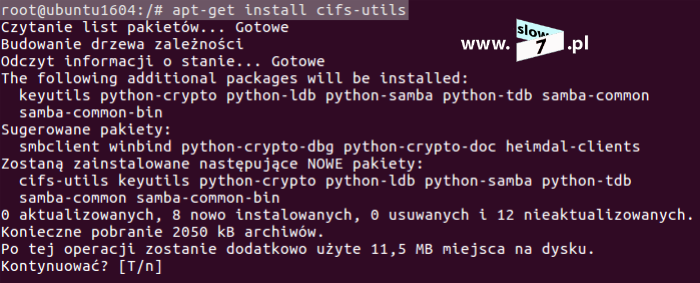
Do utworzenia wszystkich macierzy oraz do zarządzania nimi użyjemy narzędzia: mdadm Jeśli nie mamy go zainstalowanego pobieramy je za pomocą polecenia: apt-get install mdadm

Program został zainstalowany.
Aby utworzyć macierz należy posłużyć się poleceniem o ogólnej składni: mdadm --create <nazwa_tworzonej_macierzy> --level=<typ_macierzy> --raid-devices=<liczba_dysków_wchodzących_w_skład_macierzy> <definicja_dysków>
W scenariuszu przyjęto, że macierz RAID0 (nazwa: md1) będzie składać się z dwóch dysków sdb1 oraz sdc1 tak więc polecenie tworzące macierz przyjmie postać: mdadm --create /dev/md1 --level=raid0 --raid-devices=2 /dev/sdb1 /dev/sdc1 Po wydaniu komendy macierz RAID0 została utworzona.

Przechodzimy do utworzenia macierzy RAID1 (nazwa: md2). W skład macierzy wchodzą również dwa dyski: sdd1 oraz sde1 - polecenie tworzące macierz przyjmie kształt: mdadm --create /dev/md2 --level=raid1 --raid-devices=2 /dev/sdd1 /dev/sde1 Macierz RAID1 została utworzona.

Ostatnią macierz jaką utworzymy będzie macierz typu RAID5 (nazwa: md3) W skład macierzy wejdą trzy dyski: sdf1, sdg1 oraz sdh1. Aby utworzyć macierz wydajemy komendę: mdadm --create /dev/md3 --level=raid5 --raid-devices=5 /dev/sdf1 /dev/sdg1 /dev/sdh1 I tym razem utworzenie macierzy kończy się powodzeniem.

Wszystkie trzy macierze zostały utworzone (od md1 do md3) aby zweryfikować ich stan możemy posłużyć się kilkoma poleceniami. Pierwszym z nich jest komenda: mdadm --query <nazwa_macierzy> Jak widać poniżej wydając polecenie odnośnie wszystkich trzech macierzy uzyskujemy informację o: wielkości macierzy (jak można zauważyć wartości wyliczone przy opisie typu macierzy są zgodne z wartościami rzeczywistymi), typu macierzy, ilości dysków budujących macierz oraz liczbie dysków zapasowych (do tematu wrócimy w dalszej części wpisu).

Bardziej szczegółowe informacje na temat danej macierzy uzyskamy wydając polecenie: mdadm --detail <nazwa_macierzy> Poniżej przedstawiono wynik jaki uzyskano po wydaniu polecenia odnośnie macierzy /dev/md1
Informacje zostały wzbogacone o: czas utworzenia macierzy, aktualny status macierzy, ilość dysków wadliwych oraz nazwy dysków wchodzących w jej skład.

Te same polecenie lecz tym razem sprawdzamy macierz RAID1 (/dev/md2)

I macierz RAID5 (/dev/md3).

Ostatnim poleceniem jakie możemy użyć by zweryfikować stan macierzy jest komenda: cat /proc/mdstat Po wydaniu komendy poznamy stan wszystkich macierzy dostępnych w systemie.

Wydanie opisanych poleceń potwierdziło iż wszystkie z utworzonych macierzy działają prawidłowo. Aby móc zacząć zapisywanie plików ostatnią czynność jaką musimy wykonać jest formatowanie. Proces formatowania wykonamy za pomocą polecenia: mkfs.<system_plików> <nazwa_macierzy> Wszystkie macierze formatujemy z wykorzystaniem systemu plików ext4. Macierze zostały sformatowane.

Po wykonaniu formatowania macierze zostaną automatycznie zamontowane. Efekt montowania możemy śledzić np. z wykorzystaniem graficznego trybu użytkownika w oknie menadżera plików.

Macierze dysku zostały poprawnie utworzone i zamontowane od tej pory możemy rozpocząć prowadzenie zapisu plików.
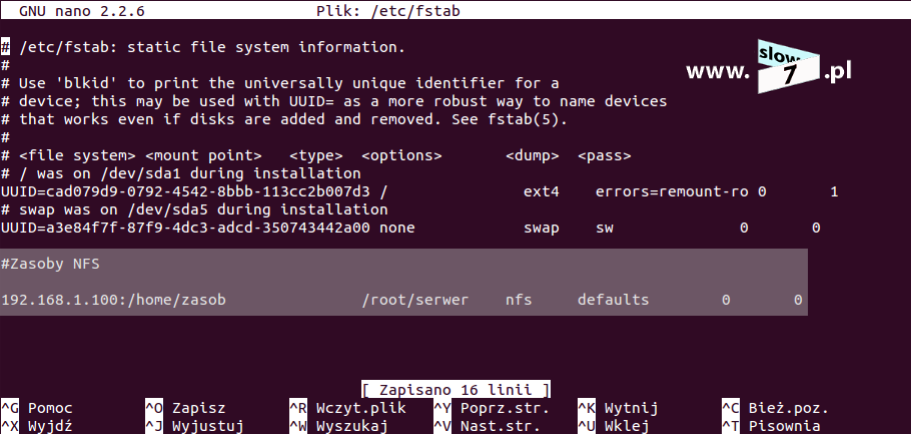
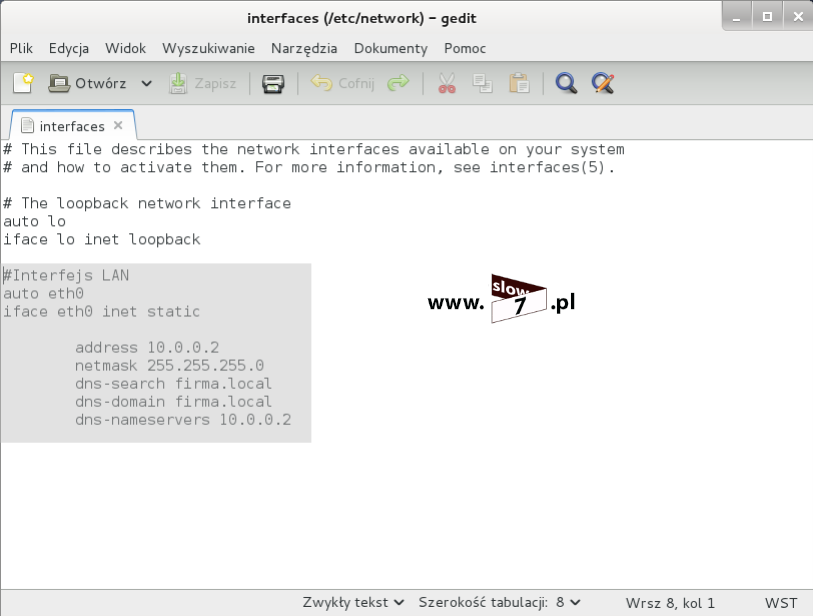
Kolejną czynność jaką wykonamy jest dodanie odpowiednich informacji do pliku /etc/fstab tak by macierze te były automatycznie montowane wraz ze startem systemu. Aby dokonać wpisu do pliku /etc/fstab musimy znać tak zwany numer UUID (ang. Universally Unique IDentifier) macierzy. Identyfikator ten jest 128-bitowym unikalnym numerem, generowanym losowo na podstawie posiadanego w systemie sprzętu oraz wartości zegara systemowego. Sprawdzenie UUID dokonamy z wykorzystaniem polecenia: blkid Wpis w pliku /etc/fstab możemy dokonać przy użyciu zdefiniowanej nazwy macierzy ale jest to sposób nie zalecany gdyż w niektórych dystrybucjach Linuxa wcześniej określona nazwa macierzy po restarcie komputera może ulec zmianie. Tak więc odpowiednie wpisy bezpieczniej jest wykonać właśnie z wykorzystaniem identyfikatora UUID.
Numer UUID jest również wyświetlany po wydaniu komendy: mdadm --detail <nazwa_macierzy> lecz nie jest to identyfikator macierzy lecz ostatniego dysku, który do macierzy został dodany.

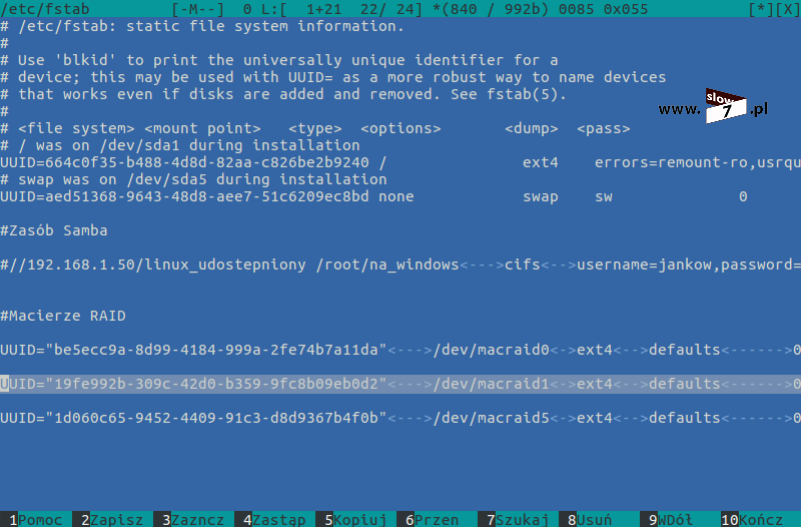
Po poznaniu numerów UUID macierzy przechodzimy do edycji pliku /etc/fstab. Edycje oczywiście możemy wykonać w dowolnym edytorze, Ja wybrałem mcedit. Po otwarciu pliku należy dodać trzy dodatkowe wpisy dla każdej z macierzy osobno. Ogólna składnia wpisu wygląda następująco: UUID="<identyfikator_UUID>" <punkt_montowania> ext4 defaults 0 0 Na rysunku poniżej zaprezentowano dodanie wpisów odnoszących się do wcześniej utworzonych macierzy.
Przyjęto następujące punkty montowań:
- macierz md1 (RAID0) - /dev/macraid0
- macierz md2 (RAID1) - /dev/macraid1
- macierz md13(RAID5) - /dev/macraid5

Aby montowanie zakończyło się sukcesem należy utworzyć katalogi, które odpowiadają zdefiniowanym punktom montowania.

Można by było w tym momencie wykonać restart komputera ale za nim to wykonamy sprawdźmy czy na pewno wszystko przebiegnie po Naszej myśli. Edycja pliku /etc/fstab niesie za sobą ryzyko popełnienia błędu, który może doprowadzić do nieuruchomienia się systemu. Dlatego zawsze warto przed wykonaniem ponownego uruchomienia komputera upewnić się, że wszystko zostało skonfigurowane prawidłowo.
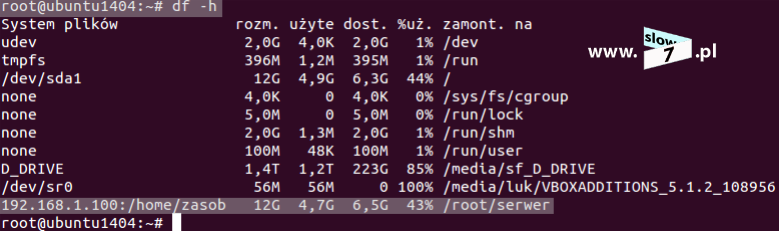
Wykonanie montowania w zdefiniowanych lokacjach nie powiedzie się, gdyż utworzone macierze domyślnie zostały uaktywnione i ich punkt montowania został przypisany do innej lokacji. Aby sprawdzić ich stan należy posłużyć się poleceniem: df -h Jak widać poniżej wszystkie trzy macierze zostały zamontowane w katalogu /media/luk/
Aby je zwolnić wydajemy polecenie: umount <nazwa_macierzy> Macierze został zwolnione.

Sprawdzenia poprawności montowania z wykorzystaniem wpisów zdefiniowanych w /etc/fstab wykonamy za pomocą komendy: mount -a Jak widać poniżej wydanie polecenia i ponowne sprawdzenie uwidacznia fakt poprawnego zamontowania macierzy.

Przed wykonaniem restartu komputera na każdej z macierzy został zapisany plik tekstowy.

Ostatni test to ponowne uruchomienie komputera. Host został zrestartowany.
Po uruchomieniu maszyny sprawdzamy stan macierzy. Jak można zaobserwować macierze zostały zamontowane prawidłowo. Uważny Czytelnik na pewno zauważy fakt zmiany nazw macierzy:
- macierz /dev/md1 na /dev/md127 - RAID0
- macierz /dev/md2 na /dev/md125 - RAID1
- macierz /dev/md3 na /dev/md126 - RAID5
Zmiana nazwy jest jak najbardziej działaniem prawidłowym i jak już wspomniałem w niektórych dystrybucjach Linuksa występuje. Dlatego też co już również zaznaczyłem wpisy w pliku /etc/fstab wykonujemy z wykorzystaniem identyfikatora UUID.

Dodatkowo stan macierz sprawdzono z wykorzystaniem polecenia: cat /proc/mdstat

Macierze działają prawidłowo i tak naprawdę wpis ten można by było w tym miejscu zakończyć. Ale jak już mamy macierze skonfigurowane sprawdźmy jak poradzić sobie w sytuacji w której jeden z dysków tworzących macierz ulega uszkodzeniu.
Rozpoczynamy od macierzy RAID0. Została zasymulowana sytuacja uszkodzenia macierzy - jeden z dysków macierzy został celowo odłączony.
Jak widać poniżej ponowne uruchomienie komputera kończy się niepowodzeniem. Macierz RAID1 oraz RAID5 zostają zamontowane prawidłowo, montowanie macierzy RAID0 kończy się niepowodzeniem.

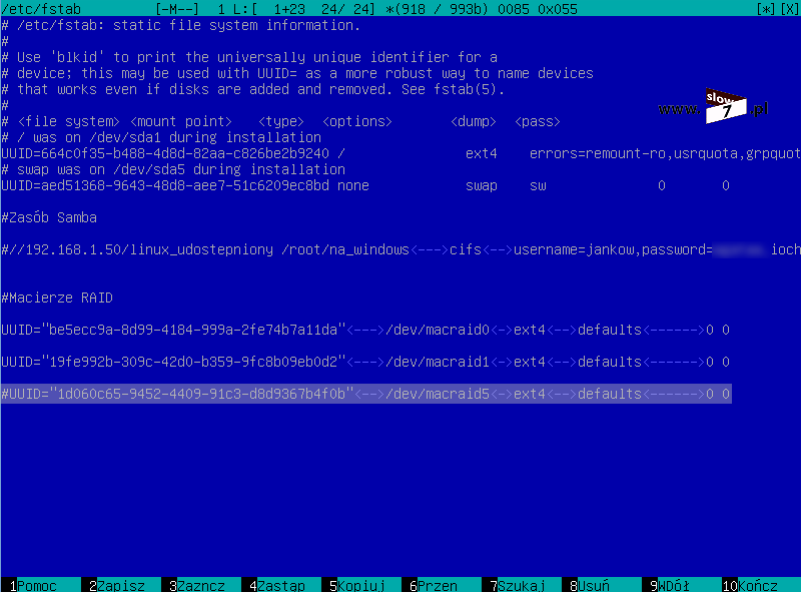
Na szczęście dla Nas system Ubuntu został wyposażony w mechanizm uruchomienia się w trybie awaryjnym. Jeśli z jakiś powodów system nie może załadować się prawidłowo tryb recovery zostanie uruchomiony automatyczne. Po uruchomieni systemu w trybie tym należy zalogować się z uprawnieniami użytkownika root. Po poprawnym wykonaniu tego kroku przechodzimy do edycji pliku /etc/fstab w którym to blokujemy wykonanie linii wpisu dotyczącego macierzy RAID0 (do blokowanie wykorzystujemy znak komentarza - #).

Po zapisie zmian wykonujemy ponowny rozruch maszyny i sprawdzamy zamontowane macierze.
Macierze RAID znów zmieniły swoją numerację:
- macierz /dev/md125 - RAID0 - nieobecna
- macierz /dev/md127 - RAID1
- macierz /dev/md126 - RAID5

Sprawdzamy szczegóły macierzy RAID0 - jak można zauważyć macierz ta jest nieaktywna.

Dostęp do plików zapisanych na macierzy został utracony. W przypadku tego typu macierzy tak naprawdę niewiele można zrobić, sposób alokacji danych (podział ich na różne dyski) na dyskach skutecznie uniemożliwi Nam ich odzyskanie. Szybkość zapisu w tego typu macierzach jest okupiona bezpieczeństwem.

Sprawdźmy zatem co stanie się w przypadku macierzy typu RAID1.
Uszkodzeniu ulega jeden z dysków macierzy i tak jak poprzednio system nie zostaje poprawnie uruchomiony. Zostają zamontowane macierze RAID0 (macierz została przywrócona poprze podłączenie uprzednio odłączonego dysku) oraz RAID5.
System uruchamia się w trybie awaryjnym.

Tak jak w przypadku RAID0 w pliku /etc/fstab zostaje zablokowana linia montowania macierzy lecz tym razem blokujemy wpis odnoszący się do macierzy RAID1.

Po wprowadzeniu zmian ich zapisie restartujemy komputer, system uruchamia się prawidłowo.
Macierze RAID ponownie zmieniły swoją numerację:
- macierz /dev/md125 - RAID0
- macierz /dev/md126 - RAID1 - nieobecna
- macierz /dev/md127 - RAID5
Sprawdzamy stan macierzy RAID1. Po analizie danych stan macierzy został ustalony na: inactive (bardzo często zdarza się, że w przypadku niedziałających prawidłowo macierzy narzędzie mdadm źle definiuje jej typ, jak się Czytelniku przyjrzysz typ macierzy został ustalony na RAID0 co oczywiście jest błędem).

Aby macierz naprawić (wszak po to definiowaliśmy macierz RAID1 by w razie jej awarii nie utracić dostępu do swoich plików) w pierwszej kolejności należy ją zatrzymać. Zatrzymanie realizujemy za pomocą polecenia: mdadm --stop <nazwa_macierzy> Macierz RAID1 przestała być aktywna.

Za pomocą komendy: lsblk sprawdzamy identyfikatory dysków (odłączenie dysku spowodowało zmianę ich nazw) jak widać poniżej jedynym dyskiem nieprzypisanym do macierzy jest dysk sdd1 tak więc dysk ten musi należeć do macierzy RAID1. Aby macierz uaktywnić wydajemy polecenie: mdadm --assemble --force <nazwa_macierzy> <nazwa_dysku> Po wydaniu komendy macierz została uruchomiona z jednym aktywnym dyskiem.

Aby sprawdzić stan macierzy wydajemy polecenie: mdadm --detail <nazwa_macierzy> Przeglądając uzyskane wyniki zauważyć można, że jest to macierz typu RAID1 a w jej skład wchodzi tylko jeden dysk.

Przejdźmy zatem do jej zamontowania i sprawdzenia czy uzyskamy dostęp do naszych plików.
W tym celu w pliku /etc/fstab ponownie uaktywniamy linię odpowiedzialną za automatyczne zamontowanie macierzy RAID1 podczas startu sytemu.
Po naniesieniu poprawek za pomocą komendy: mount -a wykonujemy operację montowania macierzy (punkt 1). Próba podłączenia macierzy do zasobu kończy się niepowodzeniem (punkt 2). Powodem takiego stanu rzeczy jest brak katalogu. Szybko poprawiamy konfigurację poprzez utworzenie folderu /dev/macraid1 (punkt 3) i ponawiamy próbę montowania. Tym razem próba kończy się powodzeniem (punkt 4).

Macierz została podłączona. Fakt ten potwierdzamy wydaniem polecenia: df -h

Ostatni test to próba otwarcia pliku i jak widać kończy się on sukcesem. Odzyskaliśmy dostęp do naszych plików.

Naprawmy naszą macierz RAID1 i dodajmy do niej drugi, sprawny dysk. Napęd został podłączony do hosta. Po uruchomieniu systemu sprawdzamy litery dysku. Jak widzimy niżej jedynym wolnym dyskiem jest dysk sdd1 (po podłączeniu nowego dysku zmieniają się ich nazwy a także po raz kolejny nazwy macierzy: /dev/md125 - macierz RAID1) i to jego włączymy w strukturę macierzy RAID1.

Aby upewnić się co do nazwy macierzy sprawdzamy jej stan.

Po sprawdzeniu i upewnieniu się co do nazwy macierzy i jej typu przystępujemy do dołączenia nowego dysku. Dysk dodajemy za pomocą już znanego Nam polecenia: mdadm --add <nazwa_dysku> Dysk został dodany poprawnie. Ponowne sprawdzenie stanu macierzy ukazuje fakt jej odbudowy.
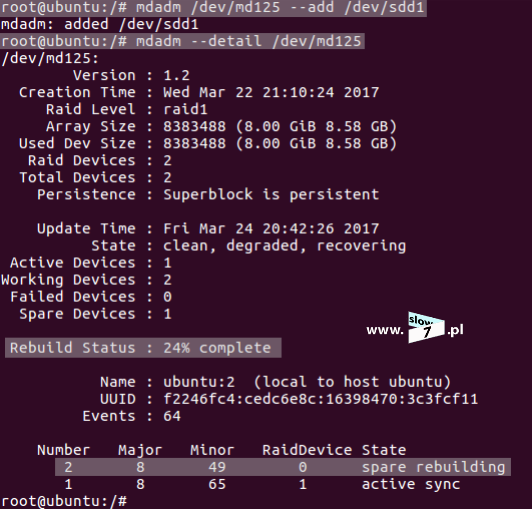
Macierz RAID1 została w pełni odbudowana i odzyskała swoją sprawność.
Zanim przejdziemy dalej wykonajmy jeszcze jeden eksperyment. Do macierzy został dodany nowy dysk /dev/sdd1, drugim dyskiem wchodzącym w jej skład jest napęd /dev/sde1 zasymulujmy uszkodzenie tego napędu i sprawdźmy czy w dalszym ciągu będzie możliwy dostęp do plików. Tak więc scenariusz sprowadza się do sytuacji w której mieliśmy działającą macierz RAID1 złożoną z dwóch dysków, pierwszy z nich uległ uszkodzeniu, macierz naprawiliśmy dodając nowy dysk (zastępując ten wadliwy) lecz niestety dotąd dobry dysk numer dwa również ulega awarii (sytuacja trochę naciągana ale nie niemożliwa).

Dysk /dev/sde1 za pomocą komendy: mdadm <nazwa_macierzy> --fail <nazwa_dysku> odznaczamy jako uszkodzony. Sprawdzenie stanu macierzy potwierdza fakt odznaczenia dysku.

Dysk /dev/sde1 z macierzy RAID1 został usunięty.
Pomimo usunięcia dysku dostęp do naszych danych jest nadal możliwy ponieważ ich kopia znajduje się na drugim dysku. Nasz test zakończył się powodzeniem ponieważ macierz zdążyła się odbudować.

Naprawmy naszą macierz i dodajmy z powrotem dysk /dev/sde1

Dysk został dodany, sprawdzenie stanu macierzy uwidacznia jej odbudowę. Po odbudowaniu macierz RAID1 wraca do pełnej funkcjonalności.

W przypadku macierzy RAID1 mamy do czynienia z sytuacją odwrotną niż w przypadku RAID0 - bezpieczeństwo przechowywanych danych ma wyższy priorytet niż szybkość ich zapisu/odczytu.
Do rozważenia pozostała Nam sytuacja w której to uszkodzeniu ulega macierz typu RAID5. Procedura uzyskiwania dostępu do danych jest bardzo podobna do tej przedstawionej w opisie macierzy RAID1 ale nic nie stoi na przeszkodzie by ją szybko omówić.
Jeden z dysków tworzących macierz zostaje uszkodzony jak już pewnie Czytelniku się domyślasz efektem tego jest brak dostępu do systemu (na szczęście mamy tryb awaryjny). Macierz RAID0 oraz RAID1 zostają zamontowane prawidłowo.

Po uruchomieniu trybu awaryjnego w pliku /etc/fstab blokujemy wpis dotyczący montowania macierzy RAID5.
Po poprawnym uruchomieniu systemu sprawdzamy stan zamontowanych macierzy.
Nazwy macierzy przedstawiają się następująco:
- macierz /dev/md125 - RAID0
- macierz /dev/md127 - RAID1
- macierz /dev/md126 - RAID5 - nieobecna
Wyświetlając szczegóły macierzy RAID5 (i tu ponownie macierz zostaje błędnie zidentyfikowana) jej stan zostaje określony jako: inactive

Aby odzyskać dostęp do danych:
1 - zatrzymujemy macierz - mdadm --stop <nazwa_macierzy>
2 - ponownie uruchamiamy macierz wraz z definicją dysków - mdadm --assemble --force <nazwa_macierzy> <nazwa_dysku>
Sprawdzenie stanu macierzy (punkt 3) potwierdza fakt jej uruchomienia.

Gdy macierz działa w pliku /etc/fstab uaktywniamy wpis odnoszący się do jej montowania.

Aby macierz została prawidłowo zamontowana musimy ponownie utworzyć katalog, który został zdefiniowany w pliku /etc/fstab Brak punktu montowania uniemożliwi załadowanie macierzy.
Po wykonaniu tych wszystkich czynności dostęp do plików zostaje przywrócony.

Jeżeli chcemy macierz usunąć musimy wykonać następujące kroki:
- wykasowanie wpisów w pliku /etc/fstab odnoszących się do skonfigurowanych macierzy,
- zatrzymanie macierzy - polecenie: mdadm --stop <nazwa_macierzy>
- usunięcie dysków wchodzących w skład macierzy - polecenie: mdadm <nazwa_macierzy> -r <nazwa_dysku>
- jeżeli dysk ma pracować jako normalny wolumin warto również wydać polecenie: dd if=/dev/zero of=<nazwa_dysku> bs=1M count=1024 celem usunięcia informacji dotyczących konfiguracji dysku (ostrożnie z poleceniem, gdyż jego użycie wiąże się z zniszczeniem danych przechowywanych na dysku) a następnie użycia narzędzia fdisk celem utworzenia nowych partycji.
Z narzędziem mdadm związana jest jeszcze jedna ciekawa funkcja a mianowicie podczas konfiguracji macierzy można zdefiniować dysk zapasowy tzw. spare devices, który w razie wystąpienia awarii przejmie zadania dysku uszkodzonego.
Prześledźmy sposób konfiguracji mechanizmu na przykładzie macierzy RAID1 (z macierzą typu RAID0 funkcja ta nie ma zastosowania).
W systemie istnieją trzy dyski: sdb1, sdc1 oraz sdd1. Dwa pierwsze z nich posłużą do zbudowania macierzy zaś trzeci będzie dyskiem zapasowym.
Rozpoczniemy od utworzenia macierzy RAID1 złożonej z dwóch dysków i jednego zapasowego. Aby skonfigurować macierz wydajemy polecenie: mdadm --create <nazwa_macierzy> --level=<typ_macierzy> --raid-devices=<ilość_dysków> <nazwa_dysków> --spare-devices=<ilość_dysków_zapasowych> <nazwa_dysków>
Tak więc podstawiając wszystkie dane aby utworzyć macierz RAID1 z wykorzystaniem dwóch dysków sdb1 oraz sdc1 i jednym zapasowym sdd1 należy wydać polecenie jak na zrzucie poniżej. Macierz RAID1 została utworzona.

Sprawdźmy dane szczegółowe macierzy. Jak można zauważyć macierz tworzą 3 dyski przy czym dwa z nich są aktywne a zaś jeden jest dyskiem zapasowym.

Po utworzeniu macierzy przeprowadzamy jej formatowanie.

Oraz celem automatycznego montowania dodajemy odpowiedni wpis w pliku /etc/fstab

Macierz została zamontowana w lokacji /dev/macraid1

Na macierzy został utworzony plik: plikmacraid1.txt

Po wykonaniu tych wszystkich czynności celem ostatecznego sprawdzenia dokonujemy restartu komputera.
Ładowanie systemu przebiega bez żadnych problemów a jak się można domyślać po ponownym uruchomieniu hosta następuje zmiana nazwy macierzy. Macierz z /dev/md1 została przemianowana na /dev/md127
Ponowne sprawdzenie szczegółów macierzy potwierdza, iż wszystko jest w porządku.

Macierz działa i jest sprawna czas zatem sprawdzić jak zachowa się ona w sytuacji uszkodzenia jednego z dysków.
Dysk sdb1 ulega awarii i odznaczamy go jako uszkodzony (punkt 1) po wykonaniu tej operacji sprawdzamy szczegóły macierzy (punkt 2). Dotąd nie aktywny dysk sdd1 automatycznie przejął (bez żadnej ingerencji) zadania dysku sdb1 (punkt 3) - rozpoczęła się odbudowa macierzy tak by przywrócić jej pełną funkcjonalność.

Dostęp do zapisanych plików jest oczywiście możliwy.

Dotarliśmy do końca - mam nadzieję, że po lekturze tego wpisu macierze w systemie Linux nie będą miały przed Tobą żadnych tajemnic.
BIBLIOGRAFIA:
https://forum.ivorde.com/mdadm-how-can-i-destroy-or-delete-an-array-t85.html