


Konsola pierwsze spojrzenie. Konfiguracja środowiska pracy.
Pierwsze spotkanie z konsolą systemu Linux w szczególności dla użytkownika, który dopiero co poznaje system Linux nie jest zachęcające ale wystarczy trochę samo zaparcia, ćwiczeń i obycia by stwierdzić, że korzystanie z tej formy komunikacji z systemem ma swoje zalety.
Po uruchomieniu konsoli system wita nas znakiem zachęty, zapraszającym do wydawania poleceń.

Znak zachęty w przypadku zwykłego użytkownika przyjmuje postać $ natomiast gdy użytkownikiem jest root (odpowiednik administratora w systemie Windows) znak zachęty zostaje zamieniony na #
Znak zachęty możemy modyfikować i ustalać jego wygląd w zależności od naszych potrzeb i upodobań. Aby wyświetlić wartość zmiennej środowiskowej PS1 odpowiedzialnej za budowę informacji pojawiających się w terminalu (ang. prompt) należy użyć polecenia: echo $PS1

Zmianę dokonujemy za pomocą komendy: export PS1='<opcje>'
Dostępne opcje to (więcej zobacz: man bash pod kątem zmiennej PS1):
\d - data w formacie: Dzień tygodnia Miesiąc Dzień,
\t - czas w formacie 24-godzinnym (HH:MM:SS),
\T - czas w formacie 12-godzinnym (HH:MM:SS),
\@ - czas w formacie 12-godzinnym (am/pm),
\A - czas w formacie 24-godzinnym (HH:MM),
\h - nazwa komputera (hostname) - do pierwszego znaku kropki,
\H - nazwa komputera (hostname),
\n - znak nowej linii,
\r - powrót karetki (ang. carriage return)
\e - znak ucieczki ASCII,
\u - nazwa użytkownika,
\w - ścieżka bieżącego katalogu (w przypadku katalogu $HOME nazwa jest skracana do tyldy (~),
\$ - jeśli numer UID jest 0 to znak: # (root), w przeciwnym wypadku znak: $,
\nnn - znak przedstawiony za pomocą liczby ósemkowej (np. 011),
\\ - backslash,
\[ - start sekwencji nie drukowalnych znaków,
\] - stop sekwencji nie drukowalnych znaków.
Do zbudowania promt-a możliwe jest również użycie kolorów. Składnia użycia koloru jest następująca: \[\e[ X;Y;Zm\] <opcja_kolor> \[\e[m\] np. export PS1='\[\e[0;34m\]\u\[\e[m\]'

gdzie:
X – kolor tekstu, Y – kolor tła, Z – efekt – przy czym gdy któregoś elementu nie używamy to go pomijamy.

Tabela opcji:
| Kolor | Tekst | Tło | Efekt | Kod |
| czarny | 30 | 40 | Pogrubienie | 1 |
| czerwony | 31 | 41 | bez pogrubienia | 22 |
| zielony | 32 | 42 | podkreślenie | 4 |
| żółty | 33 | 43 | bez podkreślenia | 24 |
| niebieski | 34 | 44 | miganie | 5 |
| magenta | 35 | 45 | bez migania | 25 |
| cyjan | 36 | 46 | ||
| biały | 37 | 47 |
Zmienne środowiskowe
Pierwszą zmienną już Czytelniku poznałeś (zmienna PS1) a nie jest to jedyna zmienna. W systemie Linux istnieje kilkadziesiąt różnych zmiennych. Wszystkich nie przedstawię ale na liście poniżej znajdziesz te zmienne, które wykorzystuje się najczęściej.
USER – nazwa aktywnego użytkownika,
HOSTNAME – nazwa hosta,
HOME – katalog domowy aktywnego użytkownika,
TZ – ustawiona strefa czasowa,
EDITOR – zmienna odpowiedzialna za określenie używanego edytora,
PATH – definiuje katalogi, które są przeszukiwane pod kątem wywoływanych poleceń, dzięki tej zmiennej nie musimy wpisywać pełnej ścieżki dostępu do programu,
SHELL – powłoka w której jest uruchomiony terminal,
TERM – rodzaj użytego terminala,
UID – identyfikator zalogowanego użytkownika,
OSTYPE – rodzaj systemu operacyjnego,
LANG – ustawienia językowe,
PWD – katalog roboczy w którym się znajdujemy,
HISTSIZE – rozmiar bufora historii.
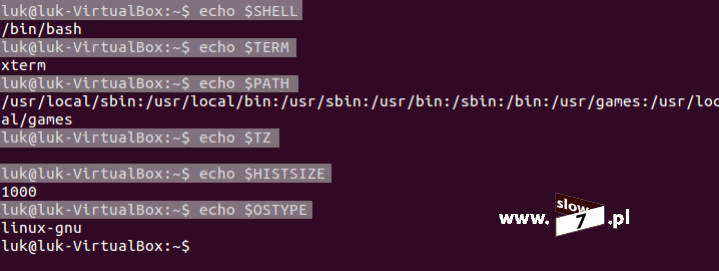
Część dostępnych zmiennych można wyświetlić za pomocą polecenia: printenv | more (użycie more powoduje zatrzymanie wyświetlania po zapełnieniu ekranu).

Część zmiennych jest jednoznacznie określona lecz dwie z nich wymagają szerszego omówienia mowa tu o zmiennej PATH oraz EDITOR.
Zmienna PATH jak już zostało wspominane odpowiedzialna jest za odnalezienie programów, które są wywoływane w terminalu poprzez polecenia.
Gdy chcemy aby wyszukiwanie polecenia rozpoczęło się od aktualnego katalogu roboczego trzeba na początku zmiennej PATH wstawić znak kropki (.) – polecenie: export PATH=".:$PATH" Gdybyśmy chcieli do zmiennej PATH dodać katalog możemy skorzystać z polecenia: PATH=$PATH':<lokalizacja_katalogu>'

1. Sprawdzenie zmiennej PATH,
2. Dodanie do zmiennej PATH znaku kropki (znak nakazuje rozpoczęcie wyszukiwania programu/skryptu od bieżącej lokalizacji),
3. Sprawdzenie faktu przypisania,
4. Dodanie katalogu: /usr/lokal/samba/sbin do zmiennej PATH,
5. Sprawdzenie faktu przypisania.
Natomiast do zmiennej EDITOR można przypisać swój ulubiony edytor tekstowy. Poniżej przykład przypisania do zmiennej EDITOR programu mcedit (jakoś wole używać tego edytora niż domyślnie zainstalowanego vi czy nano). Mcedit dostępny jest po zainstalowaniu pakietu Midnight Commander, program ten jest menedżerem plików (jak ktoś pamięta Norton Commander to się nie zawiedzie). Program instalujemy za pomocą polecenia: sudo apt-get install mc
1. Zlokalizowanie programu mcedit,
2. Sprawdzenie aktualnej wartości zmiennej EDITOR,
3. Przypisanie do zmiennej EDITOR ścieżki katalogu w której znajduje się program,
4. Sprawdzenie faktu przypisania.

Kontrola uruchamianych procesów
Każde wydane polecenie w powłoce systemu Linux powoduje wykonanie jakiegoś zadania. By móc pracować efektywnie z powłoką trzeba umieć zarządzać uruchomionymi zadaniami. Podczas pracy z powłoką mamy wpływ na sposób zachowania się zadań, możemy wykonać następujące operacje wobec uruchamianych zadań:
uruchomić zadanie na pierwszym planie - tj. wydana komenda powoduje uruchomienie zadania przez powłokę a zadanie te działa w powłoce tak że niemożliwe jest wydanie kolejnych komend,
uruchomić zadanie w tle - tj. wydana komenda powoduje uruchomienie zadania przez powłokę a zadanie te działa nie zajmując jej, mamy możliwość wykonywania kolejnych poleceń,
zawieszenie zadania - wstrzymanie pracy zadania,
wznowienie - powoduje kontynuację pracy wcześniej zawieszonego zadania.
Z każdą z tych czynności związane jest odpowiednie polecenie, aby wyświetlić listę aktualnie uruchomionych zadań, skorzystaj z polecenia: jobs

Liczba w nawiasie oznacza numer zadania znak + oraz - zadania wywołane po wydaniu poleceń fg oraz bg.
Aby uruchomić zadanie w tle na końcu polecenia umieszczamy znak: &
Gdy uruchomione jest zadanie a my wciśniemy Ctrl+Z (można też użyć polecenia: suspend) zadanie to zostaje wstrzymane lecz zapamiętywany jest stan zadania.
Tak wstrzymane zadanie możemy ponownie uruchomić przy czym mamy dwie możliwości: gdy wykorzystamy polecenie: fg zadanie to zostanie uruchomione na pierwszym planie; gdy zaś zdecydujemy się użyć polecenia: bg zadanie to również zostanie wznowione lecz tym razem w tle.
Za pomocą tych dwóch komend możliwe jest wznawianie różnych zadań, domyślnie wydanie samego polecenia fg bądź bg bez żadnych parametrów spowoduje uruchomienie ostatnio wstrzymanego zadania. Gdy zaś chcemy uruchomić, wznowić konkretne zadanie możemy użyć np. komendy: bg %<numer_zadania> Numer zadania poznamy dzięki poznanemu już poleceniu: jobs
Historia poleceń
Wszystkie polecenia, które wpisujemy do konsoli są zapamiętywane tak więc istniej możliwość odwołania się do już wydanego polecenia. Aby wyświetlić listę wydanych poleceń użyj polecenia: history

Po wydaniu polecenia wyświetli się lista ponumerowanych komend, które w powłoce wydaliśmy. Poniżej przedstawiam kilka przykładów wykorzystania listy komend.
history <liczba> - wyświetlenie zdefiniowanej liczby ostatnio wydanych poleceń,
history -c – wyczyszczenie historii,
!! – ostatnio wydane polecenie,
!<liczba> - wywołanie polecenia o danym numerze,
!-<liczba> - wywołanie polecenia minus zdefiniowana liczba
Aliasy
System Linux umożliwia tworzenia tzw. aliasów czyli skrótów, które realizują jakieś konkretne polecenie bez konieczności wpisania całej składni polecenia wraz z parametrami.
W trakcie poznawania systemu Linux bardzo często miałem nawyk czyszczenia ekranu za pomocą windowsowego polecenia cls a jak wiadomo w powłoce bash te polecenie nie występuje, bo do czyszczenia okna terminala używa się komendy clear bądź tput clear. Aby móc jednak czyścić ekran terminala z wykorzystaniem komendy cls należy stworzyć alias, który będzie łączył ciąg cls z poleceniem clear. Od tej pory wpisanie w oknie polecenia cls wywoła nam komendę clear. Alias tworzymy za pomocą ogólnej składni: alias <nazwa_aliasu>= "<polecenie>" Tak więc chcąc przypisać linuxowe polecenie clear tak aby by było wykonane po wpisaniu cls należy wydać polecenie: alias cls="clear"

Aliasy dodatkowo mogą być wykorzystane do poruszania się po systemie plików. Gdy bardzo często odwołujemy się do jakiegoś miejsca na dysku możemy stworzyć alias, który będzie łączył nam dany folder z przyjazną dla nas nazwą. Poniżej przykład uworzena aliasu dok po wywołaniu, którego będziemy przeniesieni do lokalizacji: /home/luk/Dokumenty

Ciekawe efekty uzyskamy gdy alias połączymy z zmienną.

Połączyliśmy alias dok z zmienną DOK, po wydaniu polecenia dok jesteśmy przekierowani do zmiennej, która powoduje przejście do zdefiniowanego katalogu. Dodatkowo utworzoną zmienną możemy wykorzystać w poleceniach np. kopiowanie plików. Poniżej przykład skopiowania pliku: plik1 do lokalizacji /home/luk/Dokumenty która to lokalizacja została powiązana z zmienną DOK.

Aby przejrzeć listę utworzonych aliasów wydaj komendę: alias

Aby usunąć alias należy skorzystać z polecenia: unalias <nazwa_aliasu>
Wszystkie zmienne i aliasy, które utworzyliśmy mają „cykl życia” ustawiony do czasu w którym system operacyjny działa czyli po wykonaniu restartu systemu utworzone definicje zmiennych i aliasów już nie obowiązują. A dodatkowo zmienne i aliasy nie są dostępne dla innych wywołań konsoli. Aby uniknąć konfiguracji tych parametrów po każdorazowym uruchomieniu systemu należy definicje te umieścić w pliku: .bashrc W pliku tym zapisane są Twoje ustawienia a plik ten zlokalizowany jest w katalogu domowym (w przypadku użytkownika root plik znajduje się w /root)
Gdy skończymy edytować plik .bashrc należy go przeładować za pomocą polecenia: ..bashrc.

Po wprowadzeniu zmian (dodanie kropki do już istniejącej zmiennej PATH, dodanie nowej zmiennej DOK oraz utworzenie aliasu cls) i zapisaniu pliku, plik ten należy przeładować za pomocą polecenia: ..bashrc Po przeładowaniu wszystkie wpisy, których dokonaliśmy znajdują swoje odzwierciedlenie w użytych w terminalu poleceniach.

Polecenia związane z plikami.
Zanim Czytelniku będziesz próbował testować opisane polecenia należy jeszcze chwilkę zatrzymać się i wyjaśnić zasady jakie obowiązują przy stosowaniu znaku spacji i znaków specjalnych. Praca z plikami, które wykorzystują te znaki powoduje pewne problemy gdyż znaki te i występujące po nich ciągi tekstu, często są traktowane jako parametr lub definicja osobnego pliku.
W przypadku pliku, który w nazwie zawiera spację oraz znak specjalny by odwołanie do tego pliku zakończyło się sukcesem wystarczy, że nazwę pliku obejmiemy cudzysłowem. Poniżej przykład w którym utworzyłem dwa pliki: pierwszy plik zawiera spacje - nazwa pliku: plik ze spacjami; drugi zaś plik w swojej nazwie zawiera znak specjalny > - nazwa pliku: plikiznanspecjalny> Jak widać tradycyjne odwołanie do obu plików (wykorzystano polecenie: ls - pokaż pliki w katalog) kończy się niepowodzeniem, gdy zaś nazwy plików obejmiemy cudzysłowami wydana komenda kończy się sukcesem.

W przypadku pliku, zaczynającego się od minusa objęcie nazwy pliku cudzysłowem nie wystarczy, gdyż w poleceniu w którym do takiego pliku będziemy próbowali się odwołać uzyskamy informację o błędnej opcji. By udało się zbudować komendę z nazwą pliku rozpoczynającą się od minusa, nazwę tego pliku musimy poprzedzić operatorem: ./

Każde polecenie a raczej wynik uzyskany dzięki wydaniu komendy można zapisać do pliku. Przypuśćmy, że okresowo badamy dostępność jakiegoś hosta i wyniki te chcemy mieć w zewnętrznym pliku. Aby uzyskać nasz cel należy użyć symbolu przekierowania. Są trzy główne symbole przekierowania >,>>,<
Aby zrozumieć sposób ich wykorzystania symbole >,>>, połączymy z poleceniem ping, które będzie skanować nam witrynę wp.pl
Po wydaniu polecenia: ping -c 3 wp.pl > testwp nie uzyskamy informacji w terminalu, ponieważ zostają one przekierowane do pliku testwp

Użycie polecenia jeszcze raz spowoduje nadpisanie (zastąpienie) już istniejących danych, aby wymusić dopisanie do już istniejącego pliku należy użyć symbolu >> - ping -c 3 wp.pl >> testwp

Operatora przekazania > można również użyć aby wyniki uzyskane dzięki wydaniu dowolnego polecenia przekierować do innego terminala.
W tym celu należy poznać nazwę terminala z którego korzystamy. Nazwę tą poznamy za pomocą polecenia: tty
Po otworzeniu kolejnych sesji konsoli możemy za pomocą poznanej nazwy przekierowywać wyniki wydawanych poleceń. Poniżej przykład przekierowania wyników uzyskanych dzięki poleceniu ifconfig – polecenie: ifconfig > /dev/pts/25

Użyte polecenia przekierowania > oraz >> wymuszały zapisanie wyników wydanych poleceń do pliku, natomiast symbol < spowoduje pobranie danych z istniejącego pliku.
Poniżej przykład pobrania wyrazów z pliku dane wraz z ułożeniem ich w kolejności alfabetycznej. Dane pobrane z zewnętrznego pliku dzięki użyciu polecenia sort zostają ułożone w kolejności rosnącej tj. od a do z.

Oczywiście nic nie stoi na przeszkodzie aby symbolów przekierowania w jednym poleceniu użyć kilkakrotnie. Spróbujmy więc posortowane wyrazy z przykładu powyżej zapisać do pliku. Zadanie to wykonamy po użyciu komendy: sort < dane > posortowane

Istnieje jeszcze jeden symbol a mianowicie pionowa kreska (Shift+"\"). Symbol ten pozwala nam na utworzenie tzw. potoku (ang. pipe). Potok pozwala nam na połączenie kilku poleceń tak by stanowiły one jedność, bądź bardziej fachowo aby dane wyjściowe jednego programu były danymi wejściowymi dla innego.
Taki standardowym przykładem użycia potoku jest sytuacja w której wydajemy polecenia a informacje, które uzyskujemy dzięki wydanej komendzie nie mieszczą się w jednym oknie terminala. Informacji jest tak dużo, że kolejna porcja wypisywanych danych zastępuje te bieżące a my nie mamy możliwości zapoznania się z nim. Natomiast gdy wydamy np. komendę: ls -l | more wyniki uzyskane dzięki poleceniu ls (pokaż pliki w katalogu) zostaną przekazane do aplikacji more powodującej zatrzymanie wyświetlania po zapełnieniu ekranu terminala. Kolejna porcja informacji zostanie wyświetlona po wciśnięciu dowolnego klawisza. Wydane polecenie: ls -l | more jest potokiem ponieważ polecenie to zostało zbudowane z dwóch odrębnych komend a połączonych ze sobą operatorem potoku.

Operatory przekierowania i operator potoku można łączyć tak naprawdę z wszystkimi poleceniami używanymi w powłoce wszystko zależy od celu jaki chcemy osiągnąć. Poniżej jeszcze dwa przykłady w których wykorzystano te operatory.
Pierwszy przykład pokazuje wykorzystanie operatorów do zapisu w pliku tekstowym nazw plików (w kolejności alfabetycznej) znajdujących się w danym katalogu (w przykładzie katalog /bin/ - polecenie: ls /bin/ | sort > pliki)

Drugi zaś przykład wyszukuje nam wszystkie pliki z rozszerzeniem jpg a wyniki wraz z sortowaniem zostają zapisane do pliku – polecenie: find / -name *.jpg | sort > zdjęcia

Dir i ls – zawartość katalogu
Wyświetlenie plików i katalogów znajdujących się w bieżącej lokalizacji następuje po wydaniu polecenia: dir (podobnie jak w systemie Windows).

Wyświetlenie zawartości katalogu może również odbyć się z wykorzystaniem polecenia: ls

Polecenia dir i ls zawierają szereg opcji (zobacz pomoc) lecz te najczęściej używane przełączniki to:
ls plik1 plik2 plik3 – listuje tylko wymienione pliki,
ls *.doc – pokaże wszystkie pliki o rozszerzeniu *.doc,
ls katalog1 katalog2 – listuje wymienione katalogi,
ls -l – szczegółowa lista plików wraz z atrybutami,
ls -a – pokaż pliki ukryte (czyli te których nazwa zaczyna się kropką),
ls -R – pokaż dodatkowo zawartość podkatalogów.
Dodatkowo fajnym poleceniem by wyświetlić drzewo katalogów i plików jest komenda: tree (w niektórych systemach trzeba doinstalować niezbędne pakiety – sudo apt-get install tree)
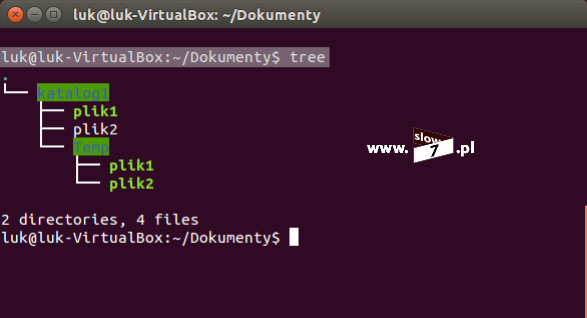
Dodatkowe parametry do polecenia tree:
-d – pokaż tylko katalogi,
-f – pokaż ścieżkę dostępu,
-a – pokaż wszystko,
-L <poziom> - poziom listowania katalogów,
-H – eksport do HTML-a,
-X – eksport do XML-a.
Cd oraz pwd – poruszanie się pomiędzy katalogami
Przejście pomiędzy katalogami realizujemy za pomocą polecenia: cd <nazwa_katalogu> możliwe jest wpisanie tylko pierwszych liter katalogu i dopełnienie nazwy za pomocą klawisza TAB (wielkość liter ma znaczenie). Przejście do katalogu wyżej następuje po wydaniu polecenia: cd ..

Użycie samego polecenia cd przeniesie nas do katalogu aktualnie zalogowanego użytkownika.
Mkdir – tworzenie folderu
Aby utworzyć katalog/katalogi należy wykorzystać polecenie: mkdir <nazwa_katalogu> Jak widać poniżej można za pomocą polecenia utworzyć wiele katalogów (nazwy katalogów po spacji).

Aby zaś utworzyć katalog w nazwie którego zawarta jest spacja należy nazwę umieścić w cudzysłowie.

Do utworzenia pliku/plików należy wykorzystać polecenie: ls > <nazwa_pliku> (symbol > - znak przekierowania). Podobnie jak w przypadku polecenia tworzenia katalogu, nazwę pliku zawierającego spację umieszczamy w cudzysłowie.

Cp – kopiowanie plików
Kopiowanie plików pomiędzy katalogami następuje z wykorzystaniem komendy: cp <element_kopiowany> <lokalizacja> Na przykładzie poniżej, utworzony wcześniej plik o nazwie plik1 został skopiowany do katalogu o nazwie katalog2 (symbol .. nakazuje przejście w strukturze katalogów o jeden poziom wyżej, ponieważ kopiowanie następowało bezpośrednio z folderu katalog1)

Wydanie komendy: cp <nazwa_pliku> <nazwa_pliku> spowoduje utworzenie kopii danego pliku.

Inne przydatne wariacje polecenia cp poniżej:
cp tes* podkatalog/ – skopiuje wszystkie pliki zaczynające się na tes do ./podkatalog/
cp -r katalog1 ~ - wydanie polecenia spowoduje skopiowanie katalogu wraz z całą zawartością do katalogu domowego (home/nazwa użytkownika)
cp * katalog1 – kopiowanie wszystkich plików z bieżącej lokalizacji do folderu katalog1 (dodanie -r skopiuje również podkatalogi)
Mv – przenoszenie plików
Za pomocą polecenia: mv przeniesiemy plik bądź zmienimy jego nazwę. Wydanie komendy: mv <bieżąca_nazwa_pliku> <nowa_nazwa_pliku> zmieni nam nazwę pliku. Polecenia możemy również używać do operacji, które odnoszą się do katalogów.

Użycie następującej składni: mv <przenoszone_pliki> <miejsce_docelowe> zmieni nam lokalizację plików/katalogów. Poniżej przeniesienie pliku: plik1 z folderu katalog1 do folderu katalog2

Przy przenoszeniu plików często przydatny okazuje się parametr -u, który to jest odpowiedzialny za przeniesienie plików gdy źródło jest nowsze od celu albo nie ma celu.
Rm – kasowanie plików/katalogów
Aby skasować pliki należy posłużyć się poleceniem: rm <nazwa_pliku>

Dostępne są również przełączniki:
rm -r katalog – kasuje wszystko w zdefiniowanym katalogu tj. wszystkie pliki wraz z podkatalogami (--recursive)
rm -f plik – brak pytania o potwierdzenie kasowanych danych (--force)
Aby usunąć pusty katalog należy skorzystać z komendy: rmdir <nazwa_katalogu>

Chmod – prawa dostępu do plików
W systemie Linux każdy plik jak także katalog ma swoje określone prawa dostępu. Prawa te określają, kto i jaką czynność może z danym plikiem/katalogiem wykonać. Mamy do czynienia z prawem do odczytu, zapisu i wykonania. Oczywiście dany plik/katalog może mieć nałożoną różną kombinacje praw. Aby wykonać sprawdzenie praw dostępu posłuż się Czytelniku znanym już Tobie poleceniem: ls -l Na rysunku poniżej zostały przedstawione prawa dostępu do dwóch plików i jednego katalogu.

Po wyświetleniu praw dostępu do plików i katalogu (to ten pierwszy ciąg znaków od lewej) możemy przejść do analizy obowiązujących praw.
Każdy element (tutaj pliki i katalog) posiada zdefiniowane uprawnienia dla trzech grup: prawa dostępu właściciela pliku, prawa dostępu grupy, oraz prawa dostępu pozostałych. Prawa te przybierają formę zapisu dziesięcio elementowego ciągu znaków. Określone znaki na poszczególnych miejscach tego ciągu będą nas informowały o możliwości wykonania na pliku danych operacji. Już wiesz czytelniku, że prawa nakładane są trzem odrębnym grupom i do określenia tych praw zostało zarezerwowane 9 znaków (po trzy znaki na każdą grupę) zaś 10 znak lecz pierwszy w kolejności będzie nam mówił z jakim elementem będziemy mieli do czynienia. Poniżej lista wartości jaka może wystąpić na pierwszym miejscu wraz z opisem:
- – zwykły plik,
d – katalog/folder,
l – symlink czyli dowiązanie symboliczne,
s – gniazdo,
f – FIFO,
c – urządzenie znakowe,
b – urządzenie blokowe.
Natomiast prawa są określane za pomocą następujących symboli:
r – prawo do odczytu (wartość 4),
w – prawo do zapisu (wartość 2),
x – prawo do wykonania (wartość 1).
Tak więc uzbrojeni w tą wiedzę spróbujmy rozszyfrować prawa elementów zaprezentowanych na rysunku powyżej (wartości podane w nawiasach zostaną omówione za chwilę).
-rw-rw-r-- prawo właściciela do odczytu i zapisu lecz nie do wykonania (ciąg: rw-), prawo grupy do odczytu i zapisu lecz nie do wykonania (ciąg: rw-), pozostali tylko prawo do odczytu (ciąg: r--),
-rw-r--r-- prawo właściciela do odczytu i zapisu lecz nie do wykonania (ciąg: rw-), prawo grupy do odczytu lecz nie do zapisu i wykonania (ciąg: r--), pozostali tylko prawo do odczytu (ciąg: r--),
drwxrwxr-x prawo właściciela do odczytu, zapisu i wykonania (ciąg: rwx), prawo grupy do odczytu, zapisu i wykonania (ciąg: rwx), pozostali prawo do odczytu i wykonania lecz brak praw do zapisu (ciąg: r-x), symbol d oznacza, że mamy do czynienia z katalogiem.
Tak więc chcąc zmienić prawa do danego pliku bądź katalogu musimy posłużyć się poleceniem: chmod Ogólna składnia użycia polecenia wygląda następująco: chmod <opcje> <grupa> <uprawnienia> <plik/katalog> bądź chmod <opcje> <wartość_liczbowa> <plik/katalog>
W poleceniu stosujemy następujące symbole:
grupa docelowa co do których praw mają obowiązywać: u - user, g - group, o - others, a – all
uprawnienia: r - read, w - write, x – execute
+ - dodanie uprawnień, - - odebranie uprawnień
Tak więc wykonajmy mały przykład. Naszym zadaniem będzie odebranie prawa odczytu i wykonania grupie pozostali. Jak widzimy poniżej grupa pozostali ma prawo wykonania tych operacji odnośnie folderu katalog1 By odebrać im te uprawnienia należy wydać polecenie: chmod o-r-x katalog1 Po ponownym sprawdzeniu uprawnień można zauważyć, że poszczególne prawa zostały odebrane.

Aby zaś nadać praw odczytu, zapisu i wykonania dla wszystkich grup możemy użyć komendy: chmod a+r+w+x katalog 1 bądź krócej: chmod a+rwx katalog1

Aby odebrać grupie prawo do zapisu i jednocześnie pozostałym odebrać wszystkie prawa skorzystaj z komendy: chmod g-w,o-rwx katalog1

Wcześniej w opisie przy każdym z praw podałem pewne wartości liczbowe, skorzystanie z tych wartości jest znacznie wygodniejszym sposobem nadawania i odbierania praw. Aby zbudować polecenie posłuż się tabelą i przykładem zamieszczonym poniżej. Naszym celem jest nadanie następujących praw do folderu katalog1: prawa użytkownika - wszystkie, prawa grupy - odczyt i wykonanie a dla pozostałych tylko odczyt. By wykonać to zadanie możemy posłużyć się poleceniem: chmod 754 katalog1

Efekt wydania polecenia.

Skąd ta liczba i jak ją obliczyć? Cyfry w prawach dostępu to:
pierwsza cyfra to prawa właściciela do pliku;
druga – grupy właściciela;
trzecia – wszystkich innych.
Jeżeli chcemy wykonać nasz zadanie otrzymujemy:
prawa właściciela: odczyt+zapis+wykonanie czyli 4+2+1=7,
prawa grupy: odczyt+wykonanie czyli 4+1=5
prawa pozostałych: odczyt czyli 4
Tak więc za pomocą tak obliczonego kodu liczbowego możemy przeprowadzić ustawienie uprawnień do plików i katalogów.
I na koniec warto wspomnieć jeszcze o jednym parametrze a mianowicie opcji: -R, która pozwala nam ustalić prawa dla wszystkich plików/katalogów znajdujących się np. w katalogu.
Na sytuacji przedstawionej na rysunku poniżej wszystkie pliki i podkatalogi znajdujące się w folderze katalog1 mają ustawione wszystkie prawa (sam folder również – pkt 1 oraz pkt 2) Za pomocą komendy: chmod -R 707 katalog1 zostały odebrane wszelkie prawa dla grupy (pkt 3) Po sprawdzeniu praw dla folderu i plików znajdujących się w tym folderze widać, że prawa mają zastosowanie (pkt 5 i pkt 6) z wyjątkiem jednego pliku – plik2 (pkt 7), zmiana praw nie mogła być zastosowana (pkt 4) ponieważ plik ten należy do użytkownika root.

Chown, chgrp - zmiana właściciela pliku/katalogu
Czasem istnieje potrzeba zmiany właściciela pliku, bądź przypisania do praw pliku danej grupy. Operację tą możemy wykonać za pomocą polecenia: chown. Ogólna składnia polecenia jest następująca: chown <opcje> <użytkownik/grupa> <plik/katalog>
Poniżej przykład zmiany właściciela pliku: plik2 Plik ten należy do użytkownika root, po wydaniu polecenia: chown luk plik2 nowym właścicielem pliku staje się użytkownik luk.

Zmiana przynależności do pliku jest również możliwa z użyciem UID użytkownika. Identyfikator UID jest przyznawany każdemu nowemu użytkownikowi i jest on niepowtarzalny. Aby poznać identyfikator użytkownika wydaj polecenie: id <nazwa_użytkownika> Naszym celem będzie ponowne przypisanie praw właściciela użytkownika root do pliku: plik2 UID użytkownika root to 0. Wydanie komendy: chown 0 plik2 spowoduje ustawienie właściciela pliku: plik2 na użytkownika root.

Wprawne oko co niektórych czytelników na pewno zauważyło, że po wydaniu przedstawionych powyżej komend chown zmieniła się tylko przynależność właściciela pliku a nie grupy. By zmienić właściciela pliku odnośnie grupy po zdefiniowaniu nazwy użytkownika podajemy nazwę grupy. Nazwa użytkownika i nazwa grupy są oddzielone dwukropkiem.
Poniżej ponownie przykład zmiany właściciela pliku: plik2 tym razem zmianie ulega właściciel i grupa. Gdy nazwa grupy i użytkownika jest taka sam wystarczy, że po definicji użytkownika wstawimy sam dwukropek. Czyli zmianę przynależności dla przykładu poniżej można by było zrealizować za pomocą polecenia: chown luk: plik2

I tu również można wykorzystać identyfikator użytkownika i identyfikator grupy.

Zmiana przynależności samej grupy odbywa się za pomocą przykładowego polecenia: chown :luk plik2 (opuszczamy definicję użytkownika i po dwukropku podajemy nazwę grupy).

Aby zmienić właściciela wszystkich plików i podkatalogów skorzystaj z przełącznika -R.

Innym sposobem zmiany przynależności pliku/katalogu do grupy jest skorzystanie z polecenia: chgrp <nazwa_grupy> <plik/katalog> Poniżej na zrzucie został przedstawiony przykład zmiany grupy dla pliku: plik2 Grupa z root została zmieniona na luk.

Find, Locate, Which – wyszukiwanie plików
Aby wyszukać dany plik bądź katalog należy użyć polecenia: find -name <nazwa_szukanego elementu> Poniżej przykład odszukania elementów zawierających ciąg tmp.

Użycie znaku gwiazdki powoduje wyszukanie plików pasujących do danego wzorca np. polecenie: find -name temp* spowoduje wyszukanie wszystkich plików zaczynających się od słowa temp
Aby znaleźć pliki ze względu na ich rozmiar możemy posłużyć się np. poleceniem find -size 5k – wyszukanie plików, których rozmiar wynosi 5 kB, aby wyszukać pliki o rozmiarze większym niż 5 kB dodajemy znak plus natomiast o rozmiarze mniejszym znak minus np. find -size +5k

Aby odszukać pliki ze względu na uprawnienia do plików możemy posłużyć się poleceniem: find <uprawnienie> Polecenie ukaże pliki o określonym stanie w kontekście użytkownika wydającego polecenie. Uprawnienia jakie możemy wyszukiwać to:
-readable – prawo do odczytu,
-writable – prawo do zapisu,
-executable – prawo do wykonania.
Jak można zauważyć poniżej użytkownik luk wydaje polecenie odszukania wszystkich plików, które ma prawo czytać a następnie wszystkich plików, które może zapisywać. Dwa pliki: plik2 i plik3 które należą do użytkownika root w wynikach wyszukiwania plików do odczytu pojawiają się lecz w wynikach do zapisu już nie. Użytkownik luk może te pliki przeglądać ponieważ atrybut dla pozostałych ustawiony jest na read dając tym samym prawo do przeglądania wszystkim.

Do wyszukiwania plików pod kątem uprawnień możemy również użyć przełącznika: -perm <kod_chmode> Tworzenie kodu chmod zostało opisane wyżej tak więc chcąc odnaleźć pliki do których użytkownik ma prawo odczytu (bo atrybut odczytu jest ustawiony w sekcji pozostali) można użyć polecenia: find -perm -004 Opcja -type f nakazuje wyświetlenie tylko plików.

Polecenie: find -perm -004 wyświetla te pliki, które mają ustawiony atrybut read w sekcji pozostali, reszta pól nie jest brana pod uwagę, ważne jest by ten konkretny atrybut był zdefiniowany (dlatego w wyniku wyszukiwania zostały umieszczone oba pliki).
Aby odnaleźć plik z konkretnie ustawionym atrybutem chmod należy podać samą wartość atrybutu (dlatego tylko jeden plik został umieszczony w wyniku wydania drugiego polecenia, ponieważ tylko ten jeden plik spełnia warunek).
Użycie znaku / spowoduje wyszukanie wszystkich plików do których zdefiniowana wartość chmod pasuje. Na rysunku poniżej użytkownik do jednego pliku ma dostęp poprzez to że jest ich właścicielem a do drugiego poprzez członkostwo w grupie pozostali.

Polecenie: find -perm 400 wyszuka tylko te pliki którem mają ustawiony kod chmod na 400 (czyli plik: plik1), drugie polecenie: find -perm 004 pokaże pliki z atrybutem 004 (czyli plik: plik2) natomiast komenda: find -perm /404 wszystkie pliki z ustawionymi atrybutami: 400, 004 oraz 404
Poleceniem find oprócz znajdowania plików z określonymi atrybutami może zostać wykorzystane również do odnalezienia plików konkretnego użytkownika bądź grupy.
Aby wyszukać pliki, konkretnego użytkownika należy skorzystać z flagi -user bądź -uid. Opcja user jest łączona z nazwą użytkownika ale także jego numerem uid natomiast flaga uid tylko z identyfikatorem użytkownika. Aby poznać numer użytkownika posłuż się poleceniem: id -u <nazwa_użytkownika> bądź echo $UID

Innym poleceniem pozwalającym nam na zlokalizowanie plików jest komenda: locate <nazwa_szukanego_elementu> Aby zignorować wielkość znaków użyj przełącznika -i.

Szybsze wyszukanie plików zapewnia nam polecenie: locate ponieważ polecenie to korzysta z bazy danych, która to przechowuje informacje o położeniu plików. Baza ta co jakiś czas jest aktualizowana przez jedno z zadań programu cron. Manualne odświeżenie bazy następuje po wydaniu komendy: updatedb
Do lokalizacji plików wykonywalnych możemy użyć polecenia: which <nazwa_programu> Poniżej jako przykład lokalizacja programu firefox oraz vim.

File – informacja o typie pliku
Narzędzie file dostarcza nam informacji o tym z jakim plikiem mamy do czynienia. Składnia polecenia: file <nazwa_pliku> Jak można zauważyć na rysunku poniżej wydanie polecenia odnośnie plików: plik, plik2 oraz bash zwróciło nam informację iż pierwszy jest dokumentem XML, drugi plikiem HTML a ostatni zaś plikiem binarnym.

Polecenie: grep jest wykorzystywane do odszukania danej wartości, lub danych które będą pasować do wzorca. Ogólna składnia polecenia jest następująca: grep <opcje> <wzorzec> <przeszukiwany_plik>
Poniżej został utworzony plik, który zawiera listę załadowanych modułów i w pliku tym poszukujemy informacji na temat modułu Bluetooth. Po wpisaniu polecenia: grep Bluetooth plik3 nakazującego przeszukanie w plik3 wystąpienia słowa Bluetooth nie uzyskujemy żadnej informacji gdyż szukany ciąg nie wystąpił w przeszukiwanym pliku. A może problemem jest wielkość liter? Aby to sprawdzić w kolejnym poleceniu został dodany przełączki -i który każe poleceniu grep zignorować wielkość liter. Tym razem uzyskujemy informację, że poszukiwany ciąg został odnaleziony.

Wzorce poszukiwanych ciągów tekstowych możemy budować w zależności od kryteriów jakie muszą spełniać. Poniżej na rysunku wzorzec, który każe wyszukać ciągi znaków w których znajdują się litery xyz – polecenie: grep [xyz] plik3

Jeszcze jeden przykład, który szuka tekstu snd_ przy czym tekst ten musi wystąpić a po nim może znajdować się dowolna mała litera od a do z – polecenie: grep snd_[a-z] plik3

Przykładów wykorzystania polecenia grep można podać bardzo wiele, wszystko zależy od tego co tak naprawdę szukamy. A na pewno pomocne będą poniższe wyrażenia, które pozwolą nam na zbudowanie kryteriów, przeszukujących plik pod kątem naszych oczekiwań:
[xyz] – pasuje do x lub do y lub do z,
[a-z] – pasuje do wszystkich liter od a do z
[A-Za-z] – pasuje do dowolnej dużej i małej litery,
[0-9] – pasuje do dowolnej z cyfr,
[^xy] – pasuje do wszystkich znaków za wyjątkiem x i y,
. – dowolny znak,
^ – pusty łańcuch na początku linii,
$ – pusty łańcuch na końcu linii,
\< – pusty łańcuch na początku słowa,
\> – pusty łańcuch na końcu słowa.
Oprócz wyrażeń do dyspozycji mamy również opcje:
-i – zignoruj wielkość liter,
-v – wypisz te wiersze, które nie pasują do zbudowanego wzorca,
-f – porównaj wiersze wg wzorców zapisanych w pliku,
-c – zwróć liczbę wierszy pasujących do wzorca,
-n – wypisz numer wiersza, w którym zostało odnalezione dopasowanie,
-l – wypisz tylko nazwy plików w których znajduje się poszukiwany tekst,
-w – wyszukuje konkretny ciąg wyrazowy oznacza to że jeżeli szukany tekst to np. ta to zwrócone zostaną tylko te wartości w których ten tekst wystąpi, nie zostanie zwrócone np. słowo tata
-r – szukanie rekursywnie tzn. przeszukiwane są również podkatalogi,
-E – interpretuje wzorzec jako wyrażenie regularne.
Przy używaniu grep należy pamiętać, że aby znaleźć wyrazy zawierające następujące znaki: + | { } ( ) ? . znaki te trzeba zamaskować – maskujemy wykorzystując do tego prawy ukośnik \
To na koniec jeszcze parę przykładów:
grep zdjecie\.jpg plik.txt – gdy w poszukiwanym wyrazie chcemy odnaleźć kropkę wówczas znak kropki musimy zamaskować używając do tego prawego ukośnika, szukany ciąg to zdjecie.jpg
grep joan*a plik.txt – użycie * oznacza, że poprzedzający gwiazdkę element będzie dopasowany zero lub dowolną ilość razy, wydanie polecenia zwróci tekst: joana a także joanna czy joannna
grep komputer * – polecenie wyszuka wyraz komputer we wszystkich plikach bieżącego katalogu
grep ka$ plik.txt – wyrazy kończące się na ka czyli np. pralka, walka itd.
grep -E "^a|^b" plik.txt – zostaną wybrane wiersze zaczynające się znakiem a lub b (znak | oznacza lub)
Kompresja plików – narzędzia ZIP, TAR i RAR
W każdym szanującym się systemie istnieje możliwość utworzenia plików archiwum, zawierających skompresowane dane. W systemie Linux najpopularniejszymi narzędziami są programy ZIP i TAR. Programy te pozwalają nam na „pakowanie” wielu plików do jednego archiwum jak i na późniejsze wyodrębnienie tych plików z archiwum.
Aby utworzyć plik archiwum ZIP możemy posłużyć się poleceniem: zip <nazwa_archiwum> <pliki> Poniżej zostało utworzone archiwum spakowane.zip zawierające trzy pliki: plik, testwp, zdjecia

Aby spakować cały katalog można posłużyć się symbolem wieloznacznym *.* bądź gdy chcemy dodać pliki określonego rodzaju np. pliki tekstowe - *.txt
Dodanie plików do archiwum odbywa się poprzez odwołanie się do wcześniej utworzonego pliku archiwum wraz z nazwą plików, które chcemy dodać. Odwołując się do przykładu powyżej aby do archiwum spakowane.zip dodać plik dane należałoby posłużyć się poleceniem: zip spakowane.zip dane
Sprawdzenie zawartości archiwum bez jego rozpakowania możemy wykonać za pomocą komendy: unzip -l <archiwum> Jak można zauważyć plik dane został dodany do pliku archiwum spakowane.zip.

Aby z pliku spakowane.zip wyodrębnić „spakowane” pliki, plik archiwum został przekopiowany do katalogu: /home/Dokumenty/katalog2 a następnie została wydana komenda: unzip <plik_archiwum> nakazująca wyodrębnienie plików.

Narzędzie ZIP jest używane z reguły do kompresji plików, które np. mają zostać wysłane do osoby nie korzystającej z systemu Linux natomiast w przypadku osób posiadających system Linux bardziej odpowiednią opcją wydaje się wybranie drugiego narzędzia a mianowicie TAR.
Opis narzędzia wykonam na tym samy zestawie danych jakie zostały wykorzystane do omówienia programu ZIP.
Aby użyć narzędzia TAR celem skompresowania plików należy wydać komendę: tar cvzf <nazwa_archiwum> <pliki>

Aby podejrzeć pliki znajdujące się w archiwum skorzystaj z polecenia: tar tvzf spakowane.tar.gz

Aby zaś rozpakować pliki należy użyć komendy: tar xvzf <skapowane_archuwum> Na przykładzie poniżej spakowane archiwum zostało skopiowane do folderu katalog2 i następnie wyodrębniono pliki.

W przypadku plików RAR należy w pierwszej kolejności doinstalować aplikacje odpowiedzialne za obsługę tego typu plików: sudo apt-get install rar unrar (rar potrafi nam kompresować i dekompresować pliki, natomiast unrar tylko dekompresować).

Kompresja plików odbywa się za pomocą polecenia: rar a <nazwa_pliku_rar> <pliki/katalogi> Po wydaniu polecenia następuje kompresja plików.

Test archiwum odbywa się poprzez użycie przełącznika: t

Dodanie pliku do archiwum odbywa się również dzięki ustawionej fladze a z zdefiniowanymi plikami, które chcemy do archiwum dodać (w przykładzie poniżej do wcześniej utworzonego archiwum spakowane.rar został dodany plik dane)

Kasowanie pliku z archiwum możemy wykonać za pomocą przełącznika d (wcześniej dodany plik dane został z archiwum usunięty)

Dekompresja archiwum odbywa się za pomocą polecenia: rar e <plik_rar>

Inne przydatne opcje:
-u – aktualizacja plików w archiwum,
-p – ustawienie hasła,
-r – kompresja wraz z podkatalogami,
-c – komentarz do archiwum.
Stat informacje o stanie pliku bądź sytemu plików.
Wydając polecenie stat <nazwa_pliku/katalogu> uzyskamy podstawowe informacje dotyczące danego pliku a także dane o operacjach wykonywanych na pliku (prawa dostępu, właściciel, czasy zmiany, modyfikacji itd.) natomiast dodając przełącznik -f uzyskamy informacje o pliku w kontekście systemu plików.

Dane uzyskane dzięki poleceniu możemy sformatować według własnego uznania poprzez zastosowanie przełączników podanych poniżej. Np. chcąc uzyskać informacje o prawach dostępu do plików w postaci ósemkowej i tradycyjnej należy wydać polecenie: stat -c %a%A <nazwa_pliku>

Prawidłowe specyfikacje formatu dla plików (bez opcji --file-system):
%a – prawa dostępu ósemkowo,
%A – prawa dostępu w postaci czytelnej dla człowieka,
%b – liczba zajętych bloków (zobacz %B),
%B – rozmiar w bajtach każdego bloku podanego przez %b,
%C – kontekst bezpieczeństwa,
%d – numer urządzenia dziesiętnie,
%D – numer urządzenia szesnastkowo,
%f – tryb surowy, szesnastkowo,
%F – typ pliku,
%g – numer grupy właściciela pliku,
%G – nazwa grupy właściciela pliku,
%h – liczba dowiązań zwykłych,
%i – numer i-węzła,
%m – miejsce zamontowania,
%n – nazwa pliku,
%N – nazwa pliku w cudzysłowach, rozwiązana jeżeli dowiązanie symboliczne,
%o – optymalny rozmiar wielkości transferu wejścia/wyjścia,
%s – całkowity rozmiar w bajtach,
%t – większy numer urządzenia szesnastkowo,
%T – mniejszy numer urządzenia szesnastkowo,
%u – identyfikator właściciela,
%U – nazwa właściciela,
%w – czytelny dla człowieka czas utworzenia pliku albo - jeżeli nieznany,
%W – czas utworzenia pliku w sekundach albo - jeżeli nieznany,
%x – czytelny dla człowieka czas ostatniego czytania,
%X – czas ostatniego czytania w sekundach,
%y – czytelny dla człowieka czas ostatniej modyfikacji,
%Y – czas ostatniej modyfikacji w sekundach
%z – czytelny dla człowieka czas ostatniej zmiany czasu,
%Z – czas ostatniej zmiany czasu w sekundach.
Prawidłowe specyfikacje formatu dla systemów plików:
%a – liczba wolnych bloków dostępnych dla zwykłego użytkownika,
%b – całkowita liczba bloków danych w systemie plików,
%c – całkowita liczba i-węzłów w systemie plików,
%d – liczba wolnych i-węzłów w systemie plików,
%f – liczba wolnych bloków w systemie plików,
%i – identyfikator systemu plików szesnastkowo,
%l – maksymalna długość nazw plików,
%n – nazwa pliku,
%s – optymalny rozmiar bloku przy zapisie/odczycie,
%S – podstawowy rozmiar bloku (dla zliczeń bloków),
%t – rodzaj systemu plików szesnastkowo,
%T – rodzaj systemu plików w formie czytelnej dla człowieka.
Du – wielkość plików/katalogów
Aby poznać wielkość jaką pliki bądź katalogi zajmują na dysku możemy skorzystać z polecenia: du Domyślnie wydanie polecenia powoduje wyświetlenie objętości plików i podkatalogów odnośnie katalogu w którym się znajdujemy. Dodanie do polecenia nazwy pliku bądź katalogu spowoduje wyświetlenie objętości pliku/katalogu.

Przydatne opcje:
-b – wielkość pliku podawana w bajtach,
-k – wielkość pliku podawana w kilobajtach,
-m – wielkość pliku podawana w megabajtach,
-h – automatyczny dobór wyświetlanej jednostki,
-c – podsumowanie na końcu,
-s – jedynie całkowita wielkość.
Zawartość pliku
W systemie Linux istnieje szereg poleceń pozwalających nam na podejrzenie zawartości interesującego nas pliku. Poniżej przedstawię kilka przykładów, choć zaprezentowaną przeze mnie gamę poleceń pewnie można jeszcze uzupełnić o dodatkowe.
Pierwsza polecenie, które chciałbym przedstawić jest to komenda: less Polecenie to umożliwi nam zajrzenie do pliku, przy czym prezentowana wartość wyświetlana jest kolejno po jednej stronie. Wydanie np. polecenia: less /var/log/syslog.1 wyświetli nam zawartość pliku syslog.1

Po wciśnięciu klawisza: h w trakcie działania polecenia zostanie wyświetlona pomoc programu. W pomocy zawarte są informacje dotyczące działania programu dotyczące np. sposobu wyświetlania zawartości pliku.
Dodatkowo podczas wywołania programu można skorzystać z szeregu opcji pozwalających nam na określenie sposobu działania programu. Przydatne flagi to:
-N – numeracja wyświetlanych wierszy,
-c – wyczyszczenie ekranu, przed wyświetleniem następnego,
-m – informacja o procencie wyświetlonego pliku,
-s – puste wiersze są redukowane do jednego,
-S – wyłączenie zawijania wierszy, teks jest przycięty do szerokości ekranu.
Użycie polecenia: head spowoduje wypisanie pierwszych dziesięciu wierszy pliku. Polecenia można używać by szybko zorientować się co w danym pliku się znajduje.

Parametry na, które mamy wpływ to:
-<liczba> - wyświetlenie zdefiniowanej liczby wierszy,
-c <liczba> - wyświetlenie zdefiniowanej liczby bajtów pliku,
-q - tryb cichy, polecenie head przy większej ilości zdefiniowanych do wyświetlenia plików nie wyświetla nagłówka pliku zawierającego jego nazwę.
Podobnym poleceniem, które możemy użyć do szybkiego zbadania zawartości pliku jest polecenie: tail tylko w przeciwieństwie do head wydanie komendy spowoduje wyświetlenie ostatnich dziesięciu wierszy.

Parametry na, które mamy wpływ to:
-<liczba> - wyświetlenie zdefiniowanej liczby wierszy,
-c <liczba> - wyświetlenie zdefiniowanej liczby bajtów pliku,
-q - tryb cichy, polecenie tail przy większej ilości zdefiniowanych do wyświetlenia plików nie wyświetla nagłówka pliku zawierającego jego nazwę,
-f - użycie tej flagi spowoduje otwarcie pliku i jego ciągłe monitorowanie, nowe wiersze będą się pojawiać w miarę dodawania nowych informacji do otwartego pliku. Użycie tego parametru świetnie nadaje się do przeglądania wszelkiego rodzajów logów monitorujących stan systemu.
Innym programem, który pozwoli nam na podejrzenie zawartości pliku jest: cat

Niektóre parametry programu to:
-s - użycie flagi spowoduje połączenie pustych następujących po sobie wierszy w jeden,
-b - numerowanie nie pustych wierszy,
-n - numerowanie wierszy
Gdy istnieje potrzeba numeracji wierszy w danym pliku możemy do tego celu użyć komendy: nl

Parametry:
-v <liczba> - rozpoczęcie numeracji od zdefiniowanej liczby,
-i <liczba> - zdefiniowanie licznika numeracji czyli wartość o jaką będą się zmieniały kolejne numerowane wiersze,
-b <a><t><n><pW> - określenie sposobu numerowania: -ba numeracja wszystkich wierszy; -bt numeracja niepustych wierszy; -bn brak numerowania; -pW numerowanie tylko tych wierszy, które zawierają zdefiniowane wyrażenie W,
-n <ln><rn> - wyrównanie numeracji: -nln wyrównanie do lewej strony, -nrn wyrównanie do prawej strony,
-w <liczba> - ustalenie szerokości przeznaczonej na numerację,
-s <znak> - ustalenie znaku, który zostanie wstawiony pomiędzy numerację a tekst (domyślnie jest to znak tabulacji).
Aby wydobyć ciągi tekstowe z blików binarnych możemy posłużyć się poleceniem: strings Polecenie przydatne, gdy chcemy poznać wersję czy autora danego programu.

W przypadku potrzeby przeglądnięcia pliku binarnego możemy skorzystać z dwóch programów: pierwszy z nich to od drugi to zaś xxd.
W przypadku pierwszego mamy możliwość wyświetlenia zawartości pliku w postaci ósemkowej (domyślna wartość), dziesiętnej (flaga: -Ad) lub heksadecymalnej (flaga: -Ax).

Drugi program dane prezentuje w formie heksadecymalnej bądź binarnej (flaga: -b)

Aby przeglądać pliki PDF możemy skorzystać z programu xpdf lub gv.

I tu chciałbym zakończyć, mam nadzieję, że nie zraziłeś się Czytelniku do takiej formy komunikacji z systemem i że dalej będziesz chciał odkrywać tajniki tej formy dogadania się z Linuxem. W kolejnym wpisie zajmiemy się kontrolą procesów oraz użytkownikami.
Bibliografia:
http://www.computerhope.com/unix/uchmod.htm
http://krnlpanic.com/wp/linux-file-and-directory-permissions-explained/
http://rtfq.net/linux/linux-single-user/permissions-basic-command-line-tutorial/





Komentarze